













译者 | 布加迪
审校 | 重楼
生成式AI模型经过训练后,可基于输入生成内容。输入指令的描述性越强,输出内容就越准确、越精确。馈送给生成式AI模型的输入指令被称为提示,这恰如其名。设计最合适的提示这门技艺就叫提示工程(prompt engineering)。
本文向使用GPT-4和PaLM等大型语言模型(LLM)的开发人员介绍了提示工程。我会解释LLM的类型、提示工程的重要性以及辅以实例的各种提示。
了解大型语言模型
在开始介绍提示工程之前,不妨探讨一下LLM的发展历程。这将帮助我们了解提示的重要性。
生成式AI基于基础模型,而基础模型基于无监督学习技术用庞大的数据库加以训练。这些基础模型成为了针对特定用例或场景进行微调的多个模型变体的基础。
大型语言模型可以分为基础LLM和指令调优的LLM。
基础LLM是用公共领域可用的庞大数据集加以训练的基础模型。这些模型直接可以使用,擅长单词补全。它们可以预测句子中接下来的内容。基础LLM的例子包括OpenAI的GPT 3.5和Meta的LLaMa。当您将字符串作为输入传递给基础模型后,它会生成通常紧跟在输入字符串之后的另一个字符串。
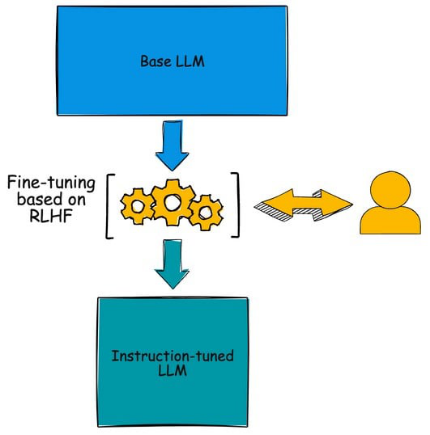
指令调优的LLM是基础模型的微调变体,旨在遵循指令并生成适当的输出。指令通常采用一种描述任务或提出问题的格式。OpenAI的gpt-3.5-turbo、斯坦福大学的Alpaca和Databricks的Dolly都是基于指令的LLM的几个例子。gpt-3.5-turbo模型基于GPT-3基础模型,而Alpaca和Dolly是LLaMa的微调变体。
这些模型采用了一种名为人类反馈强化学习(RLHF)的技术;在这种技术中,针对每个给定的指令,模型都获得人类的反馈。与馈送给基础模型的提示相比,这种模型的输入提示更具描述性、更面向任务。
提示设计的重要性
提示工程是充分发挥LLM潜力的一项基本技能。一个设计良好的提示可以确保意图清晰、明确上下文、控制输出风格、减少偏误,并避免有害的内容。通过精心设计提示,用户可以提高LLM的相关性、准确性,并在各种应用环境中负责任地使用生成式AI。
提示工程的两个关键方面是全面了解LLM和熟练运用英语。设计糟糕的提示只会生成不成熟、不准确的糟糕回应,这接近于产生幻觉。使用正确的词汇表以最简洁的形式来指令模型对于利用LLM的功能至关重要。
由于我们将处理多个LLM,因此了解模型特有的最佳实践和技术也很重要。这通常来自使用模型,并仔细分析模型提供者发布的文档和示例方面的经验。LLM还受到用于接受输入和生成输出的token数量的限制,token是一种压缩输入文本的形式。提示必须遵守模型规定的大小限制。
提示的类型
提示工程仍然是一个模糊的领域,没有具体的指导方针或原则。随着LLM不断发展,提示工程也将随之发展。
不妨看一下与当前LLM结合使用的一些常见类型的提示。
- 显式提示
显式提示为LLM提供了一个清晰而精确的方向。大多数时候,它们都是清晰而有针对性的,为LLM提供了一个简单的任务或一个需要回答的问题。当您需要提供简短的事实性答案或完成某项任务(比如总结一篇文章或回答多项选择题)时,显式提示会有所帮助。
显式提示的一个例子是这样的:“写一篇关于一个小女孩发现了一把神奇的钥匙,打开了通往另一个世界的隐藏之门的短篇故事。”
这个显式提示清楚地概述了故事的主题、背景和主要元素,为LLM提供了生成内容的具体指令。通过提供这样的提示,LLM可以致力于确保回复满足给定的标准,并围绕提供的概念创建一个故事。
- 对话提示
对话提示是为了让您以一种更自然的方式与LLM进行交互。大多数时候,这些问题不是那么有条理,在长度和风格上给了LLM更大的自由。对话提示适用于提供感觉更自然、更流畅的回答,就像使用聊天机器人或虚拟助手一样。不妨举一个对话提示的例子。
“嗨,Bard!你能给我讲一个关于猫的笑话吗?”
在这个对话提示中,用户开始与LLM进行对话,明确要求特定类型的内容(这里是一个关于猫的有趣笑话)。然后,LLM可以通过提供与猫有关的幽默笑话,生成满足用户请求的响应。这种对话提示允许与LLM进行更具互动性、更具吸引力的交互。
- 基于上下文的提示
基于上下文的提示为LLM提供了更多关于情况的信息,这有助于LLM提供更正确更有用的答案。这些问题常常包括特定领域的术语或背景信息,可以帮助LLM了解当前的对话或主题。基于上下文的提示在内容创建等应用领域大有帮助;在这些应用领域,确保输出准确、在给定的上下文中有意义显得很重要。
一个基于上下文的提示的例子类似下面分享的提示:
“我计划下个月前往纽约旅行。你能给我推荐一些受欢迎的旅游景点、当地餐馆和比较冷门的景点吗?”
在这个基于上下文的提示中,用户提供了关于即将成行的纽约之旅的具体信息。提示包括用户想要寻找热门旅游景点、当地餐馆和比较冷门的景点方面的建议。这种基于上下文的提示可以帮助LLM了解用户的当前情况,并针对用户的纽约之行提供相关的建议和信息,从而调整回复内容。
- 开放式提示
开放式提示是LLM面临的另一类问题。它鼓励模型给出更长的、更详细的答案。开放式问题可以帮助您创造性地写作、讲故事,或者为文章或写作提出想法。这些问题让LLM可以给出一个更自由的答案,并分析不同的想法和观点。
以下面的提示为例,它代表一个开放式提示:
“请告诉我技术给社会带来的影响。”
在这个开放式提示中,用户发起一个宽泛的讨论主题,而并没有指定任何特定的方面或角度。LLM可以自由地探索技术对社会影响的方方面面,比如社会互动、经济、教育、隐私或任何其他相关方面。这种开放式提示让LLM可以通过深入研究与技术对社会的影响相关的不同维度和视角,提供更全面的回复。
- 消除偏误的提示
可以设计成这样的提示:提示迫使LLM避免输出中可能出现的偏误。比如说,提示可以询问不同的观点,或者建议LLM思考基于证据的思维。这些问题有助于确保LLM没有隐藏的偏误,并且结果是公平、平等的。
下面是一个要求LLM避免偏误的提示的例子。
“请生成回复,就以下主题给出平衡和客观的看法:印度基于种姓的居留地。考虑提供多个观点,避免偏袒任何某个群体、意识形态或观点。致力于提供有可靠来源作为佐证的事实信息,并在回复中竭力做到包容和公平。”
这个提示鼓励LLM以中立和公正的方式探讨这个话题。它强调了呈现多视角、避免偏袒和依赖可靠来源的事实信息具有的重要性。它还强调包容和公平,敦促LLM考虑不同的观点,而不助长歧视或偏见。提供这种提示的目的是消除潜在的偏误,并给出更平衡的输出。
- 代码生成提示
由于LLM是用公共领域的代码库加以训练的,因此它们可以用各种语言生成代码片段。基于代码的LLM提示是要求LLM以一种特定的语言生成代码的提示。提示应该是具体而清晰的,并提供足够多的信息,以便LLM生成正确的答案。以下是基于代码的LLM提示的一个例子:
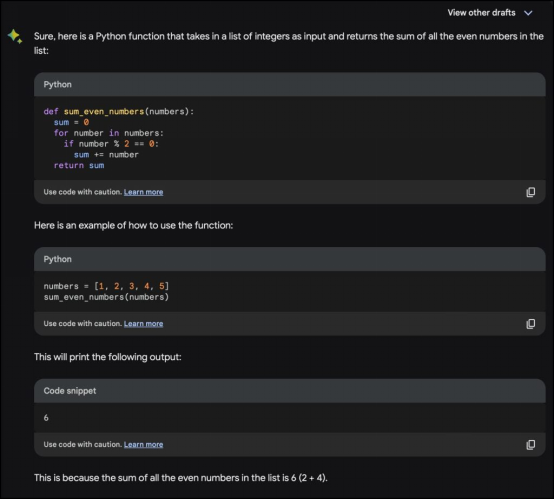
“编写一个Python函数,接受整数列表作为输入,并返回列表中所有偶数的和。”
在这个例子中,提示要求一个Python函数来计算给定列表中所有偶数的和。生成的代码定义了一个名为sum_even_numbers的函数,该函数接受整数列表作为输入。它初始化一个变量sum来存储偶数的和,然后遍历输入列表中的每个数字。如果某个数字是偶数(即能被2整除且无余数),它将该数字加到总和中。最后,函数返回和。它还添加了文档,并解释了它是如何得到解决方案的。
在这个系列的下一篇文章中,我们将探讨用于提示工程的一些技术,辅以例子。敬请关注!
原文标题:Prompt Engineering: Get LLMs to Generate the Content You Want,作者:Janakiram MSV




























