














火山引擎刚刚交出大模型趋势答卷:
火山方舟,一个大模型服务平台。
它将国内多个明星大模型放在平台上,如MiniMax、智谱AI、复旦MOSS、百川智能、IDEA、澜舟科技、出门问问等。
不仅为大模型玩家提供训练、推理、评测、精调等功能与服务,后续还提供运营、应用插件等工具,进一步支撑大模型生态。
总之,就是要为大模型,打造一个超强底座。
而透过火山方舟,火山引擎如何看待大模型趋势?想做哪些事?如今也有了更明确的答案。
火山方舟是什么?
简单理解,各种大模型平台都好比自营商铺,向行业用户售卖大模型服务。
不过火山方舟想做的不是自家专卖店,而是一个集合了多家大模型旗舰店的商城。
在这个商城里,行业用户可以快速触及到业界优质的大模型,基于火山引擎的能力对模型精调推理,降低大模型使用门槛。
大模型玩家能基于火山引擎搭建稳健的大模型基础设施,提升自家模型业务能力,触及到更加直接和广泛的行业需求,加速迭代升级。
火山方舟作为连接二者的平台,则负责提供丰富完善的开发工具、充沛算力、安全互信的平台以及企业服务等,让双方的合作更加丝滑。
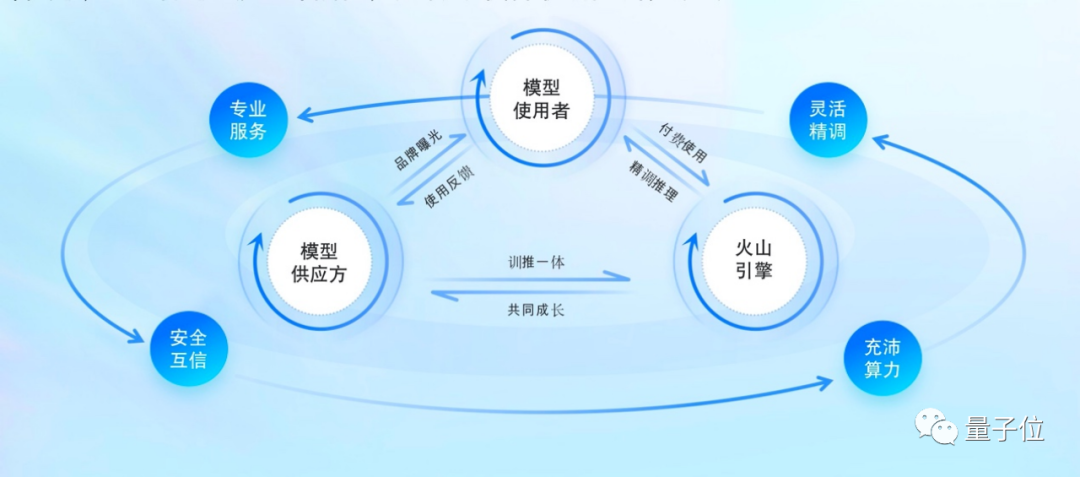
重点功能包括6个方面,贯穿了大模型采购使用的全流程:
第一是模型广场
这可以理解为模型提供方和使用方初步了解的一个平台,大模型厂商能在此进行模型创建、上传、部署等操作,下游用户能看到模型效果并快捷体验。
第二是模型推理
当用户选定好模型后,火山引擎可提供安全互信的推理方案,既保障模型提供方的知识产权安全,同时也维护使用者的数据信息安全。用户能直接使用已部署的在线服务,或者将精调模型部署为在线任务。
第三是模型精调
对于大部分行业用户来说,通用大模型只是基础能力,想要使用更优质的大模型服务可能都需要基于自家数据进行持续训练或精调。
火山方舟能提供极简精调流程,只需两步即可一键精调:选择基础模型→上传标注数据集。对于有复杂需求的场景,还能进一步设置高级参数、验证集、测试集等更丰富的功能。
第四是模型评测。
生成式大模型目前还很难形成一个业界公认的benchmark,应用场景、数据等因素都会影响它的表现。但对于行业用户来说,明晰不同大模型的优劣势是购买服务前至关重要的一步。
所以火山方舟同步推出了评测工具,支持用户基于自身数据、系统化地感知模型表现情况,并且给出详细的测评报告,为后续做决策提供数据基础。
要知道,B端的使用场景也是“千人千面”的,企业要用自己的评测数据试一试,才能给出符合自身要求的准确评估。此外,基础模型的升级,新技术新模型的涌现,还将持续很长一段时间。企业需要不断测试对比、紧跟发展。
第五是运营干预
通过提供运营干预工具,用户可以快速设置相关规则,这样在模型已经投入使用后,无需精调模型即可干预模型输出结果。
第六是应用插件
目前大模型接入插件功能是大势所趋,能进一步发挥模型能力。未来在火山方舟上,能看到实时信息获取(通常说的“联网”)*、私域文档问答召回、Prompt补全与构建等。
透过以上重点功能,不难看出火山引擎对于当下云计算趋势的理解——尽可能加速大模型应用落地。
而且在具体实现路径上,火山引擎还给出了一种别样的打法,并且形成了鲜明的自身特点。
火山引擎智能算法负责人吴迪给出了三个关键词来总结:
开放、加速、信任。
所以火山方舟有何不同?
开放、加速、信任,三个关键词一一对应,其实代表火山方舟的自身定位、算力和安全。
首先来看自身定位上,火山方舟是个开放、中立的平台,企业客户可以根据实际效果自由选择模型。
对于云厂商而言,想要做好MaaS服务,核心之一肯定是模型层要够丰富、够强大。因为这意味着能在更丰富的应用场景中落地。
此前不少人将这一问题的解决,局限在了云厂商自家大模型能力提升上。
随着亚马逊云推出大模型平台Bedrock,一次接入Stability AI、Anthropic等多家大模型能力,给行业内开启了一种新范式。
这样一来,平台能直接引入业内最优秀的大模型,丰富自身能力和应用场景。
火山方舟的路径亦是如此,纳入更多大模型也让它具备更高的灵活性。
吴迪介绍,这样一来用户能够根据不同任务需求“货比三家”,接触到更多行业先进大模型。
通过提供统一的workflow,火山方舟能够实现模型之间的灵活插拔。在多模型切换下,工作流基本不改变,让各个模型完成自己擅长的任务,加速大模型的开发构建应用。
其次,火山引擎重点关注了大模型玩家们焦虑的算力问题。主打一个够用、实惠且稳定。
火山引擎的海量资源池,能够满足当下大模型训练推理的需求。
而通过加速训练和推理,能让算力的性价比更高。
NVIDIA开发与技术部亚太区总经理李曦鹏表示,如果想要硬件充分发挥性能,需要软硬件协同设计。
硬件方面,NVIDIA针对生成式AI的不同硬件配置与火山引擎底层平台深度结合。
在软件层面也提出了多种优化方法,双方一起做了很多开源发布,以图像预处理算子库CV-CUDA为例。它们能高效地运行在GPU上,算子速度达到OpenCV(运行在CPU)的百倍左右。如果用CV-CUDA作为后端替换OpenCV和TorchVision,整个推理的吞吐量能提升至原来的二十多倍,算子输入结果上CV-CUDA与OpenCV完全对齐。
此外,火山引擎还推出了Lego算子优化。
这一框架可以根据模型子图的结构,采用火山引擎自研高性能算子,实现更高的加速比。
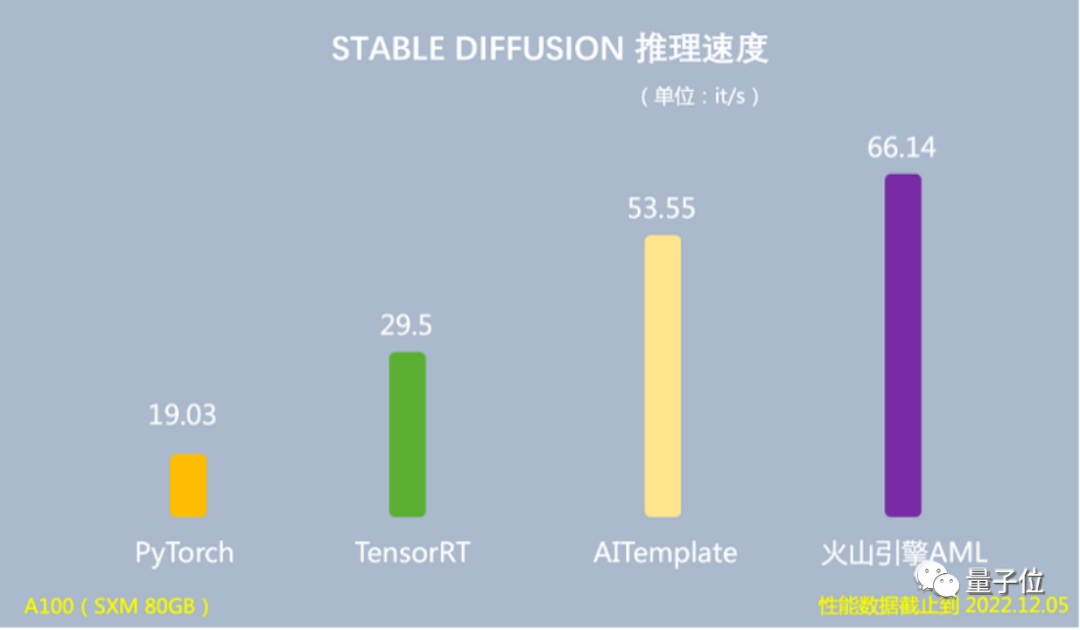
在推理场景下,使用Lego算子优化,可以将基于Stable Diffusion模型的端到端推理速度提升至66.14 it/s,是PyTorch推理速度的3.47倍,运行时GPU显存占用量降低60%。在训练场景下,在128张A100上跑15天,模型即可训练完成,比当时最好的开源版本快40%。
而在稳定性方面,火山引擎也和英伟达做了更底层的合作。
李曦鹏介绍,目前大模型训练往往需要几千、上万张卡同时启动,如果其中某台机器出现故障,则会导致整个训练过程被影响。因此训练过程中的稳定性非常关键,它将直接影响开发效率。
在这方面,火山引擎和英伟达基于内部大量测试,最终实现了特定模型的规模、网络结构等,确定合适的checkpointing频率,在保障训练连续性的同时又让机器能够稳定运行。
具体能力也已有实际案例验证
大模型玩家MiniMax基于火山引擎,研发了超大规模的大模型训练平台,高效支撑着三个模态大模型每天数千卡以上的常态化稳定训练。在并行训练上实现了99.9%以上的可用性。除了训练以外,MiniMax也同步自研了超大规模的推理平台,目前拥有近万卡级别的GPU算力池,稳定支撑着每天上亿次的大模型推理调用。MiniMax和火山引擎一起为大模型训练搭建了高性能计算集群,一起致力于提升大模型训练的稳定性,保证了超千卡训练的任务稳定运行数周以上。
稳健的大模型基础设施让MiniMax从零开始自主完整地跑通了大模型与用户交互的迭代闭环,实现从月至周级别的大模型迭代速度,和指数级的用户交互增长。MiniMax面向企业级的大模型解决方案目前已接入数百家企业客户,打通办公协作、智能硬件、教育、医疗、客服等十余个行业场景。
然后是能力输出上,火山引擎提出训推一体以及统一workflow
统一workflow的能力不仅在于模型的灵活插拔,它还集成了火山引擎对大模型能力的理解。
比如如何做自动评估?pipeline怎么定?该做多少精调?这些问题都是需要经过大量开发工作后,才能输出的经验。通过这些细节上的保驾护航,企业用户落地大模型的效率和成功率都会有明显提升。
另一边,火山方舟也重点提出了训推一体的理念。
吴迪表示,基于对行业的观察,他相信未来大模型领域的头部及腰部厂商都会使用“1+n模式”,也就是自研或深度合作一个主力大模型、同时调用多个外部模型,对训练和推理都有需求。
加之火山引擎始终认为深度学习、机器学习是一件统一、紧凑且纯粹的事情,所以他们判断训推一体模式会是发展趋势,并已在火山方舟上推出。
而且训推一体化后,同样能为企业节省算力。
最后再来看安全方面,这也是火山方舟着重强调的部分
吴迪表示,在大模型时代,信任问题至关重要。
大模型提供方不希望自己辛苦训练出的模型被人拷贝走,这属于重要知识产权;下游客户不希望自己的数据在推理和精调过程中不被泄露,敏感数据只有自己可见。
在这二者之间,便会形成一个信任的gap。尤其是当下大模型服务中的合作方众多,构筑信任墙就显得至关重要。而火山引擎作为云平台,会通过互信计算框架,基于不同客户的安全和隐私保护诉求,提供了包括安全沙箱、可信硬件以及联邦学习方案,来保证大家在互信的基础上推理、精调等。
以上三个方面,将火山引擎在云市场中的差异勾勒清晰。
从中也可看出,火山引擎的技术积累、行业经验和趋势理解,都为它入局大模型平台提供了坚实的保障。
那么,为什么火山引擎的答卷是火山方舟?
为什么是火山方舟?
直接原因来自于市场需求。
大模型趋势轰轰烈烈演进几个月,几乎触及到了各行各业,相应的需求也随之暴涨。
但对于行业用户来说,怎么触及市面上最先进的模型?怎么选择最适合自己的模型?怎么确定最后的大模型服务方案?这些问题对企业自身的技术理解程度、开发水平都提出了要求。
作为供给侧,大模型玩家也急于在热潮下快速推进自家业务发展。这不仅是一场技术竞赛,同时也是一场商业竞速赛,谁能更快触及更多用户,就会在市场中更快站住脚跟。在这种情况下,平台的触达能力一定大于厂商自身。
以及底层硬件厂商,同样也迫切需要大模型底座
NVIDIA开发与技术部亚太区总经理李曦鹏表示,英伟达开发每一款新产品,都是以workload来驱动,所有开发都是要解决真实存在的问题。
比如随着深度学习的兴起,用Tensor Core加速矩阵乘法计算,就是在原有框架下针对workload的重点模块做效率提升。
再比如英伟达去年发布的Hopper架构,设计远早于发布时间。当时GPT-3才刚刚问世,大模型趋势远没有到来,英伟达是做了大量前瞻性的研究。而怎么做出这种前瞻性的探索,就是要从实际应用的基础结构中去发现问题。
回到当下来看,对于未来AI的趋势是否朝着GPT趋势发展,李曦鹏表示现在也无法确定,但是行业中的实际需求能够推动英伟达做出更有针对性的硬件和软件特性升级。
怎么更快、更准确把握住这些需求?还是要依托平台连接大模型玩家。
所以,像火山方舟这样承载着大模型供给方、使用方以及底层硬件厂商的平台,是行业迫切需求的。
而更深层的原因,还来自火山引擎自身
吴迪很确定地说,火山方舟的使命,是加速大模型、大算力应用落地。
为什么要加速?两条增长曲线可以给出答案。

在以时间为横轴、GPU需求量为纵轴的坐标系里,首先出现当下的第一条增长曲线:模型训练曲线。
现在新兴的大模型正如雨后春笋般冒出,训练需求量飙升。但随着通用大模型市场趋于饱和,这条增长曲线也会逐渐放缓。
与此同时,还有一条增长曲线出现:推理需求曲线(模型应用曲线)。
而且它将在短期内呈指数增长趋势,在2025年左右和训练需求曲线相交,并在之后反超。
也就是说,市场上的推理需求量,最终一定会大于训练需求量。因为推理需求多大,代表了应用场景有多丰富。
如果应用场景的丰富度不够高,导致推理需求曲线没有快速升起,训练需求曲线同样也会受到影响滑落。
一旦出现这一局面,将意味着目前诸多投身大模型浪潮的创业者和企业,将会面临非常艰难的局面。
吴迪表示,火山引擎深信大模型趋势不是一次简单的浪潮,它将是新技术时代的一扇窗。如果想要加速这个时代更快到来,那么就要尽可能缩短推理需求超过训练需求的时间轴。
也就是加速大模型的应用落地。
火山方舟同时连接下游应用层和上游模型层、硬件层,加速企业用户使用大模型,在营收上更快去回报大模型领域创业者,以此形成一个加速正向循环。
而这也是为什么火山引擎要将自家大模型平台取名为“方舟”。
吴迪说,在想名字的时候,他们希望能有一个词来形容开放包容、生机勃勃、充满希望的意境。
最终在几十个词中确定了方舟。因为它能代表两方面寓意。
第一,承载着很多人的事业和梦想,共同驶向一个成功的远方,而且是一个具象的词;
第二,火山引擎相信整个大模型、大算力领域,需要众多合作伙伴在模型训练、内容安全、硬件优化等方面共同努力;
如今,方舟带着火山引擎的技术积累、行业理解以及美好愿景,正式启航。
未来大模型浪潮将会如何翻涌,还是未知数。
但载着众多国产大模型玩家、携手英伟达的火山方舟,一定会带着火山引擎驶向新的节点。



















