














一、常见的数据分析场景
常见的数据分析就是对业务数据或者行为数据进行分析和管理。

业务数据主要是指用户行为发生之后,实际产生的结果,我们使用数仓建模来给业务提供指标,从而指导业务进行一些正向的操作或者修改之前的一些操作。行为数据主要是指用户使用产品上的各种行为,我们可以对面向行为分析的数据进行加工和分析,从用户的行为中推导出来到底是哪些环节没有做好,从而调整和优化这些环节。
二、数仓建模方法
在引入行为分析方法之前,先介绍一下数仓建模的方法。

数仓建模方法主要流程如下:
- 用户空间:以音乐播放为例,用户在APP上的操作会产生行为日志,比如广告请求、曝光、点击,APP打开、用户注册和播放、下载歌曲等操作日志。
- 数仓建模:我们将用户的行为日志采集过来,形成ODS、DWD层的表,再往后是各个主题表。不同业务团队会创建自己的业务宽表,从用户空间中抽取感兴趣的事件放到各自的主题业务宽表中。
- 主题应用:再往下是这些主题宽表所支撑的业务,比如报表建设、特征挖掘、机器学习、OneID系统建设等等,最终为增长团队、经营团队和产品团队等提供支持。
三、数仓建模方法的优劣势
1、优势
- 方法论成熟 : 已经在无数的公司中被验证过,更有像《阿里巴巴大数据实践》《Building The Data Warehouse》 等优秀的指导书籍。
- 技术栈成熟: 无论是从消息中间件、数据ETL管路,数据湖、数据仓库、数据集市的各种选型等,工业界已经诞生了无数优秀的框架和数据库。
- l技术供应商支持完善:Google,Amazon,Microsoft,阿里云,腾讯云等供应都提供几乎一站式的服务。
- 技术人才供给: 各个互联网公司都有数据仓库建模的需求,人才供应充分,培养体系完备。
- 公司推动阻力小: 数仓的重要性经历了充分的市场教育,推动起来会比较顺畅,投入产出比也比较好阐述。
- 应用场景:适合指标类的多维分析数据运算。
2、劣势
- 建设链条长: 数据采集->ODS->DWD->DWT->数据报表和应用。
- 数据一致性保证有挑战:不同数据主题之间会有指标和字段的重合,在工程和业务之间,不同的工程团队之间都可能造成理解的偏差。
- 扩展字段流程复杂:表结构需要预先定义, 扩展新字段往往需要较长的开发周期和回溯数据周期。
- 工程实现很难统一: 架构评估往往取决于承接的工程团队的过往经验和喜好,同样需求的实现差异较大。
- 不适合时序行为数据分析:因为需要按照用户维度shuffle和开窗,用户行为分析往往比较耗资源。
- 预聚合不够灵活:当维度不能命中预聚合的维度时,查询会退化成全表聚合。
四、面向行为分析的分析方法-概念

基于以上数仓建模的优缺点,我们需要对行为数据进行一些不一样的抽象,用一些不一样的查询方式来解决面向用户行为数据的问题。首先来介绍一些概念:
- 用户空间:和数仓建模一样,这部分不变。
- 用户事件序列:和数仓建模方式不同,我们这里不将用户的行为日志抽象到ODS、DWD层,在这里将行为日志数据抽象成用户事件序列,比如对于播放歌曲事件会包含用户属性和事件属性,用户属性回答谁在什么样的设备上这个问题,事件属性回答这个人主要做了什么事, 这个事我怎么去描述它。对于所有事件,我们都可以用这两种类型的元数据来描述这个事件,在一个时间轴上串起来,就可以知道这件事是谁做的,以及做了这件事后发生了什么。
- 事件抽象:有了用户序列的抽象,我们可以聚焦一下,看某个人在某个具体事件序列上的抽象。比如图中会员升级的例子。
- 用户群计算:有了事件抽象之后,最重要的就是我们怎么使用这些数据,我们可以利用这些数据来获取新增用户群、活跃用户群以及满足X条件的用户群等等。

如上图所示,以7日Android用户的留存率为例,左边是传统数仓的解决方案,右边是行为分析的解决方案。
- 传统数仓的解决方案:主要是写一个SQL来看7天前的新增用户在今天的活跃用户中是否有,如果有的话,7天的新增用户作为分母,今天的活跃用户作为分子,除出来一个比例计算留存率。但是可能在数仓里面,一条记录并不是用用户的ID来划分的,所以最终想要计算出用户ID的结果会有一个shuffle、关联、数据倾斜的过程,这都是在传统输出解决方案当中我们需要去考虑的一些点。
- 行为分析的解决方案:这是另外一种简化的计算用户留存的方式,本质上是在图中的三个圈圈选的用户中做计算,三个圈的交集就是7天前的新增用户在今日活跃用户中的比例。我们将复杂留存SQL转成了三个用户群之间并集和交集的计算。
所以我们现在已经有了两层抽象,对于数据的抽象,是用时间线排进来的一个个的事件,对于计算的抽象,是把一个查询拆解成一个个用户群的计算,再根据计算的结果回答我们一个个关于用户群相关的问题。
五、面向行为分析的分析方法-整体架构
下面是面向行为数据分析的整体架构(该架构可供参考,但并非唯一解)。

从下往上看,最下面是数据的存储,采用列式存储,并在其中应用一些对用户群更友好的技术,从而减少数据的加载量和分发量。往上是文件元数据/列元数据。再上面是用户数据访问层,本质上就是计算层。IDMapping层主要解决不同ID对应同一用户的问题。查询缓存层、查询结果聚合层,以及最上面的查询接入层,都是为了提高查询效率。
下图是对于7日的Android用户留存率,在面向行为数据分析的架构中的实现过程抽象:

接下来是对于面向行为数据分析架构中关键节点的介绍。
1、列存储

首先介绍我们自定义的列存储。我们没有使用ORC、Parquet这些列存储格式,主要是因为ORC、Parquet格式不会对用户存储做一些自定义的优化,市面上的Druid、HBase也是为了加速数据访问引用了很多的组件。对于特定的场景,我们可以把更多的组件应用过来,比如说BloomFilter(布隆过滤器),目的是快速判断一个用户是否在当前文件中,因为我们所有的查询其实都是面向用户ID的。还有Delta encoding(差分编码),用来对时间格式进行存储,减少时间戳的存储体积。
2、元数据

列存储再往上一层就是元数据。首先是文件元数据。文件的第一级索引是按时间的,而时间是动态的,因为用户的活跃时间可能是在晚上或者中午的休息时间,凌晨可能用户并不活跃。这就导致我们文件中存储的用户数据在时间上不是平均分配的,比如想要查询凌晨1点到早上9点的数据,有可能需要访问多个文件。这个时候我们需要知道应该在动态时间切片文件中访问哪些文件。因此我们就需要一个元数据的管理,基于查询的起止时间,找出存储的位置,这样可以确保每个文件存储的大小是相近的,尽可能减少数据计算过程中的数据偏移。
其次是列元数据。我们查询的时候并不是要把所有的列都加载进来,计算的时候只加载文件中对应偏移量的列数据,这样可以减少网络传输的开销、磁盘IO和内存使用量。
3、OneID

OneID的建设在每家公司是不一样的,但本质上都是用来追踪用户的设备变化,还原用户事件的最真实状态,进而提供IDMapping、ID Encoding的能力。
4、缓存层

缓存层主要是对以前访问数据的缓存,加速访问。缓存key中有时间的版本号,数据可能会因为回填等原因引入新数据,通过时间版本号的方式可以自动刷新缓存。
5、用户数据访问层

用户数据访问层包括数据的聚合层、用户群算子层以及元数据管理和底层时序数据的加载。首先,用户请求会包含时间范围、过滤条件、用户群聚合条件等;第二步,根据用户请求,请求元数据,确定要访问的文件和列在哪里;第三步,知道了数据在哪后,加载数据到计算节点,并缓存到本地;第四步,用户分区计算,最大化并行查询效果;最后,进行聚合计算。
通过以上架构,我们希望在查询时,只去加载最低密度的数据,在不同节点之间通讯时只去通讯最必要的用户群的bit数组,最终也是通过bit运算的方式返回,再通过OneID将bit数组还原成所关心的用户群的一个详细的描述。
六、面向行为分析的分析方法-分析举例
下面是行为分析的几个例子。
首先是用户留存分析。

上图中包含了7月29日至8月8日(第5天到第10天)之间的留存率。对于行,只需要计算7月29日至8月8日之间每天的新增用户。对于列,只需要计算行时间+偏移量的活跃用户数。而整个表格的计算就是对两个用户群进行逻辑与。这样就把表格的计算拆成了一个个单元格的独立的计算,每一个独立的计算都可以通过预计算保存在缓存中,还可以通过一些好的用户交互方式,实现自助的留存率分析。
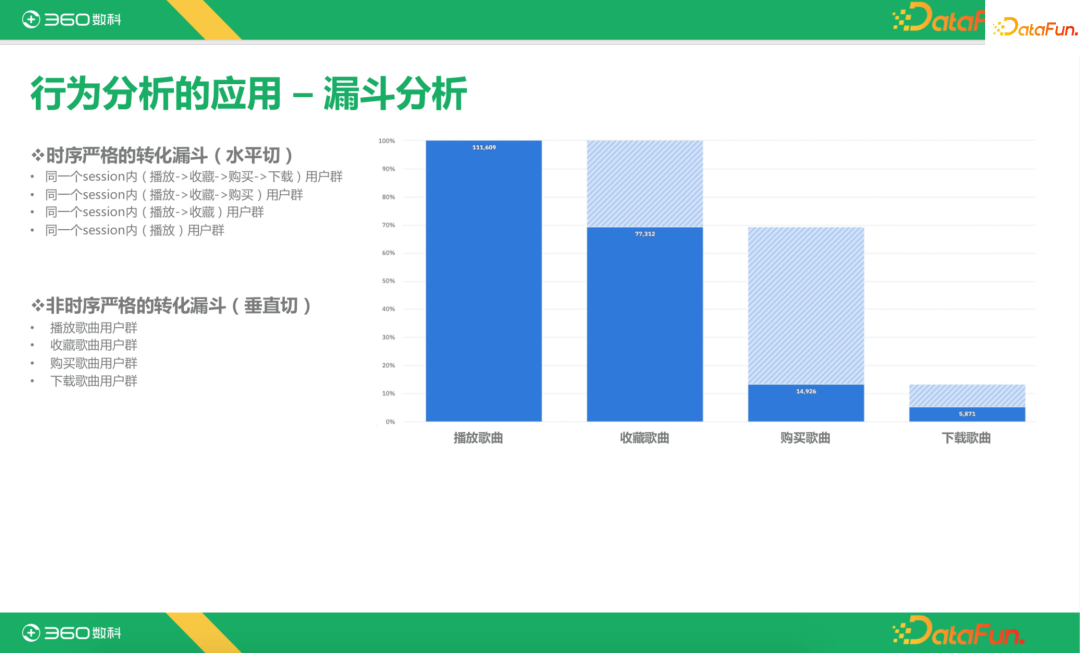
第二个常用的分析是漏斗分析。比如分析做了播放的用户中,有多少进行了收藏,收藏的用户又有多少进行了购买,购买的用户中有多少下载了歌曲。漏斗分析又有时序严格和非严格之分。时序严格的转化漏斗,必须是发生在时序严格递增的场景下,同一个session内,一定是先播放,再收藏,再购买,最后下载。非时序严格的转化漏斗常用来进行趋势分析,有可能先购买再播放。对于非时序严格的转化漏斗,采用垂直切,我们只需要去分别计算每一个事件的用户群,再做与关系。时序严格的转化漏斗,要采用水平切,计算一个session内既播放,又收藏,购买并且下载了的用户群,再用搭积木的方式计算出来。

第三个分析的例子是路径分析。常用于某个业务指标转化不好时进行分析。首先定义事件的入度和出度,也就是一个事件的前一个和后一个事件。计算采用深度遍历的方式。























