












业务连续性的重要性
业务连续性是指制定应对重大中断和灾难的策略。灾难恢复(DR) 帮助组织在发生中断或灾难时恢复和恢复业务关键功能或正常操作。
高可用性集群 是支持关键业务应用程序的服务器组。应用程序在主服务器上运行,如果出现故障,应用程序操作将转移到辅助服务器上,并在辅助服务器上继续运行。
与容器前相比,灾难恢复策略的工作方式显着不同。那么关系就简单直接了,应用程序和应用服务器之间是一对一的映射。对所有内容进行备份或快照以便在发生故障时进行恢复是过时的方法。
灾难恢复类型
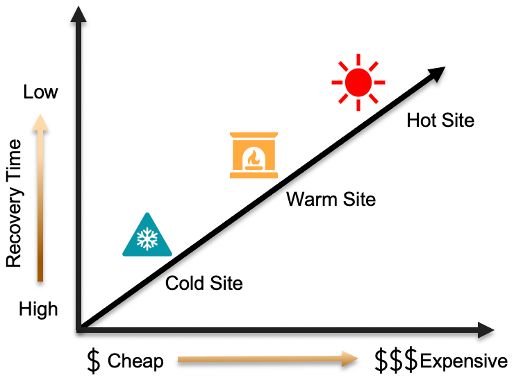
在我们讨论不同的灾难恢复方法之前,了解不同类型的灾难恢复站点非常重要。容灾站点分为冷站点、温站点、热站点三种。
冷站点:这是基本选项,需要最少的硬件/设备或没有硬件/设备。将不会有连接、备份或数据同步。尽管这是最基本、最便宜的选项之一,但它还没有准备好承受故障转移的影响。
暖站点:与冷站点相比,这种类型的升级选项很少。可以选择网络连接和硬件。这具有数据同步功能,并且可以在数小时或数天内解决故障转移,具体取决于设置类型。
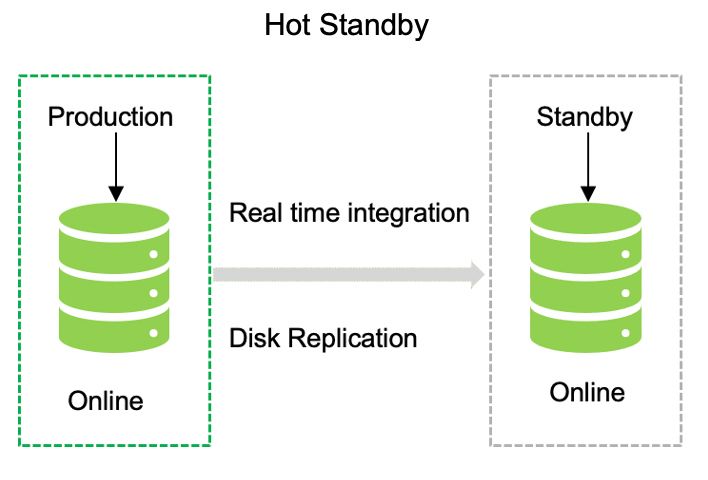
热门站点:这是该地块中最优质的选项,具有配备齐全的硬件和连接以及近乎完美的数据同步。与其他两种类型的站点相比,这是一种昂贵的设置类型。
灾难对组织的影响可能非常昂贵,因此首先做出最佳选择非常重要。灾难恢复管理可以减轻灾难造成的破坏性事件的影响。没有一种方法/选项是完美的,并且可能会根据企业/组织的要求和类型而有所不同。
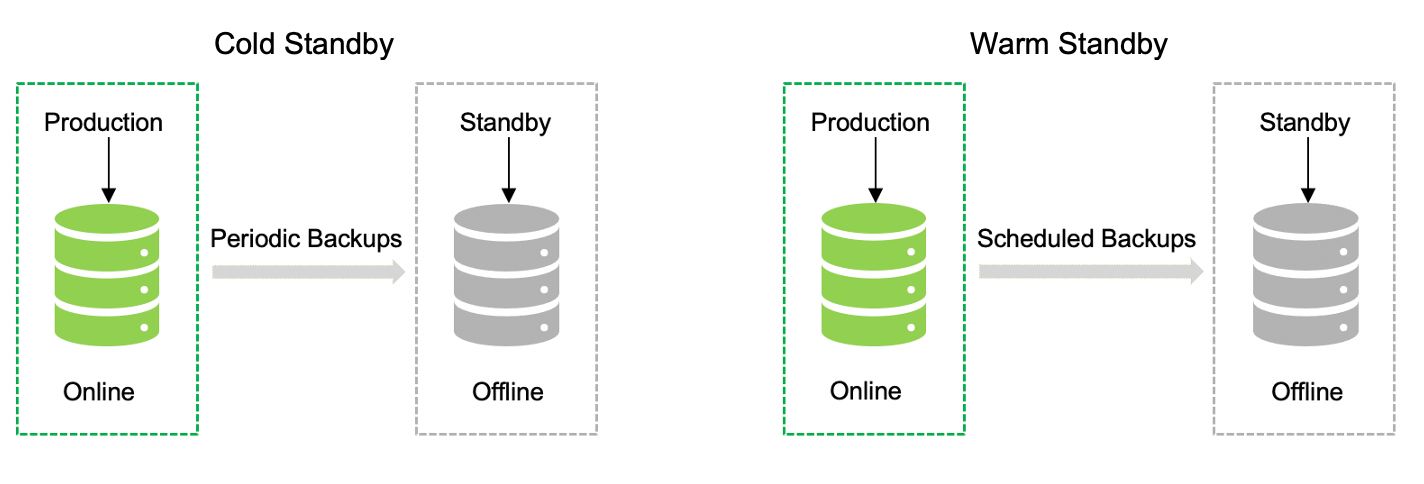
传统灾难恢复方法
选项 1:我们可以通过定期备份来实现冷备用,或者您可以通过批量/计划复制数据来实现热备用。这里的主要区别在于从主数据中心到灾难恢复的复制类型。在此选项中,只有在线购买备用设备后,应用程序和数据才可用,并且由于定期/计划的备份而导致数据丢失的可能性很高。
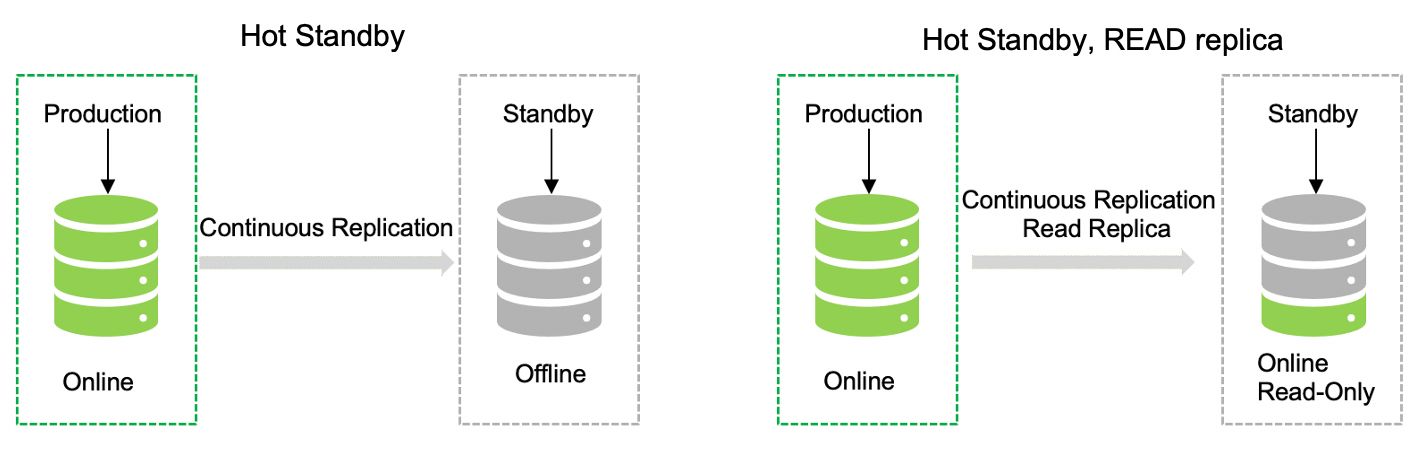
选项 2: 在这种情况下,我们采用连续复制,复制之间的基线时间非常短。这是一种热备,另一种是带有只读副本的热备。这意味着两者在读取数据方面将是相同的,而数据只能在主数据中心位置写入。备用可以在发生中断时立即使用。
选项 3:这是进行灾难恢复设置的最可靠的方法。在这种情况下,您需要维护两个具有实时数据无缝复制的活动数据中心。该模型需要使用最新技术和工具堆栈进行高级设置。这是一个综合模型,但可能很昂贵。配置和维护可能很复杂——运行这种设置需要特定的技能。
容器灾难恢复
现在,我们来讨论一下如何利用容器化生态系统进行灾难恢复管理。
Kubernetes 集群:部署 Kubernetes 时,您将获得一个集群。Kubernetes 集群由一组称为节点的工作机器组成,它们运行容器化应用程序。每个集群至少有一个工作节点。工作节点托管作为应用程序工作负载组件的Pod 。控制平面管理集群中的工作节点和 Pod。在生产环境中,控制平面通常跨多台计算机运行,集群通常运行多个节点,提供容错和高可用性。要了解有关集群组件的更多信息,请参阅链接。
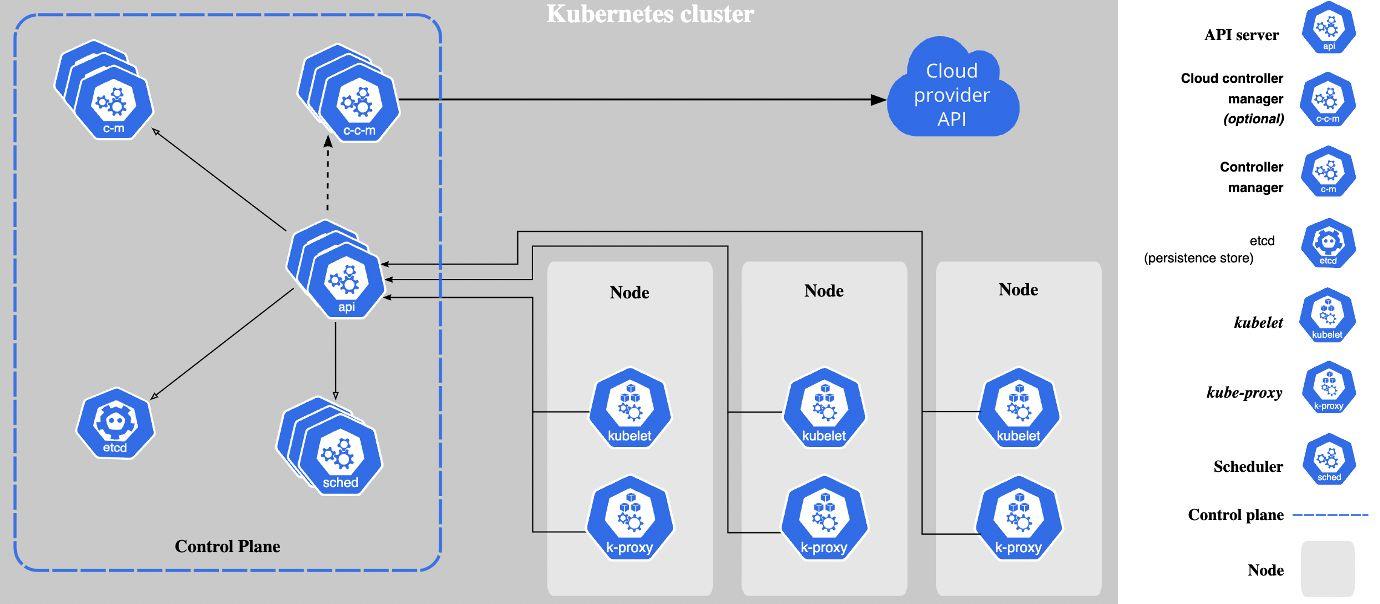
在此设置中,应用程序不会部署到一台定义的服务器中。它可以调度在任何工作节点上。容量管理将在集群中完成,因为 Kubernetes 是一个编排工具——根据节点的可用性分配部署。
我们需要备份什么
我们知道 Kubernetes 生态系统的本质是非常动态的,这使得更传统的备份系统和技术更难在 Kubernetes 节点和应用程序环境中良好运行。RPO 和 RTO 可能需要更加严格,因为应用程序需要不断启动和运行。
以下是备份的重要事项列表:
- 配置
- 容器镜像
- 政策
- 证书
- 用户访问控制
- 持久卷
集群中有两种类型的组件:有状态组件和无状态组件。状态完整组件会留意、期待响应、跟踪信息,并在未收到响应时重新发送请求。ETCD 和 Volumes 是有状态组件。在 Kubernetes 平面的其余部分,工作节点和工作负载是无状态组件。备份所有有状态组件非常重要。
ETCD备份
ETCD 是一种分布式键值存储,用于保存和管理分布式系统保持运行所需的关键信息。最值得注意的是,它管理流行的容器编排平台 Kubernetes 的配置数据、状态数据和元数据。
我们可以利用ETCD内置的快照功能来备份ETCD。另一种选择是拍摄存储卷的快照。第三个选项是备份 Kubernetes 对象/资源。恢复可以分别从快照、卷和对象完成。
持久卷备份
Kubernetes 持久卷是管理员配置的卷。它们是使用特定的文件系统、大小和识别特征(例如卷 ID 和名称)创建的。
Kubernetes 持久卷具有以下属性
- 它是动态配置的或由管理员配置的
- 使用特定文件系统创建
- 有特定的尺寸
- 具有识别特征,例如卷 ID 和名称
为了让 pod 开始使用这些卷,需要声明它们,以及 pod 规范中引用的声明。持久卷声明描述 Pod 所需的存储量和特征,查找任何匹配的持久卷,并声明这些。存储类描述默认卷信息。
从持久卷创建卷快照:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: new-snapshot-test
spec:
volumeSnapshotClassName: csi-hostpath-snapclass
source:
persistentVolumeClaimName: pvc-test
恢复卷快照
您可以引用 aVolumeSnapshot来PersistentVolumeClaim使用现有卷中的数据配置新卷,或将卷恢复到您在快照中捕获的状态。VolumeSnapshot要在 a 中引用 a PersistentVolumeClaim,请将数据源字段添加到您的PersistentVolumeClaim.
在此示例中,您引用VolumeSnapshot在新声明中创建的PersistentVolumeClaim并更新Deployment来使用新声明。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-restore
spec:
dataSource:
name: my-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
storageClassName: standard-rwo
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
恢复 Kubernetes 平台操作
我们可以通过两种方式恢复k8s平台:重建或恢复。以下是恢复平台运营的一些策略:
- 平台备份与恢复
我们需要使用备份工具来运行此操作,该工具将从与应用程序 ETCD、配置和映像相关的源集群中获取备份,并将这些信息存储在备份存储库中。备份完成后,您需要使用相同的备份工具从目标集群运行此恢复操作,并且可以从复制存储库恢复信息。
- 从快照恢复虚拟机
该策略仅适用于 ETCD 恢复。从 ETCD 快照恢复 Kubernetes 集群所涉及的步骤可能会有所不同,具体取决于 Kubernetes 环境的设置方式,但下面描述的步骤旨在让您熟悉基本过程。还值得注意的是,下面描述的过程替换了现有的 ETCD 数据库,因此如果组织需要保留数据库内容,则必须在继续之前创建数据库的备份副本。
- 安装ETCD客户端
- 确定适当的 IP 地址
- 编辑清单文件以更新路径
- 找到规格部分
- 将初始集群令牌添加到文件中
- 更新挂载路径
- 替换软管路径的名称
- 验证新恢复的数据库
- 故障转移到另一个集群
如果一个集群出现故障,我们会使用故障转移集群。这些集群与基础设施和无状态应用程序相同。然而,配置和秘密可能不同。在设置时,这两种类型的集群可以与 CI/CD 同步。由于我们有并行运行的双集群,因此在设置和维护方面可能会很昂贵。
- 在多站点情况下故障转移到另一个站点
在这个策略中,我们需要构建一个跨多个站点的集群。这适用于云和本地。由于 ETCD 仲裁,始终建议拥有两个以上站点且站点数量为奇数,以便在一个站点发生故障时保持集群运行。与其他选项相比,这是一种流行且有效的方式。节省收益取决于我们如何管理产能。
- 从头开始重建
这就是所谓的GitOps,这里的概念是,我们为什么不在出现故障的情况下重建系统而不是修复呢?如果集群出现故障,我们可以从git包装器构建整个集群,并且不需要对ETCD进行备份。这非常适合无状态应用程序,但如果您将其与持久性数据相结合,那么我们需要寻找支持和恢复存储的选项。
结论/总结
根据需求、复杂性和预算来规划和设计自己的灾难恢复策略非常重要。提前做好计划非常重要。我们需要知道基础设施的容忍程度是多少,可以承受多少服务损失等,从而设计出经济高效的灾难恢复策略。所需的另一项关键了解是关于工作负载。我们正在运行有状态的工作负载还是无状态的工作负载?我们需要了解与备份和恢复相关的底层技术和依赖项。当涉及需要 100% 正常运行时间和可用性的任务关键型云原生应用程序的 DevOps 时。在发生灾难时,应用程序需要继续可用并顺利运行。














