













6 月 27 日消息,AI 模型盲堆体积实际上效果并不见得更好,更多要看训练数据的质量,微软日前最近发布了一款 13 亿参数的语言模型 phi-1,采用“教科书等级”的高品质资料集训练而成,据称“实际效果胜于千亿参数的 GPT 3.5”。

▲ 图源 Arxiv
IT之家注意到,该模型以 Transformer 架构为基础,微软团队使用了包括来自网络的“教科书等级”数据和以 GPT-3.5 经过处理的“逻辑严密的内容”,以及 8 个英伟达 A100 GPU,在短短 4 天内完成训练。

▲ 图源 Arxiv
微软团队表示,比起增加模型的参数量,通过提高模型的训练数据集质量,也许更能强化模型的准确率和效率,于是,他们利用高质量数据训练出了 phi-1 模型。在测试中,phi-1 的分数达到 50.6%,比起 1750 亿参数的 GPT-3.5(47%)还要好。
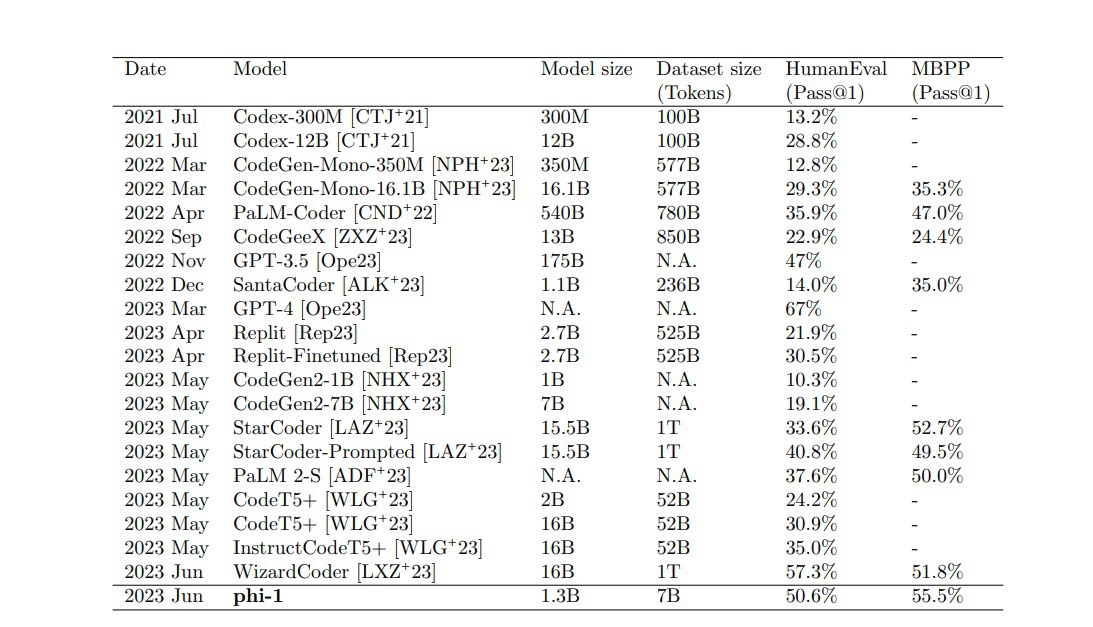
▲ 图源 Arxiv
微软表示,phi-1 接下来会在 HuggingFace 中开源,而这不是微软第一次开发小型 LLM,此前,他们打造一款 130 亿参数的 Orca,使用了 GPT-4 合成的数据训练而成,表现也同样比 ChatGPT 更好。
目前关于 phi-1 的论文已经在 arXiv 中发布,可以在这里找到论文的相关内容。





























