一、多云缓存产生的背景
1、多云架构

知乎目前采用的是多云架构,主要基于以下三个方面的考虑:
- 服务多活。这是为了防止在某个机房出现不可抗力、不能提供服务的时候,业务被全面中断。
- 容量扩展。单一机房的容量上限是万台,知乎目前的服务器规模已经超过了万台。
- 降本增效。同一云服务在不同云厂商的定价是不同的,我们希望能够以比较低廉的价格享受到优质的服务。
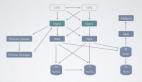
知乎目前的数据中心有5-6个,核心的机房有两个。一个是在线机房,它部署直接面向知乎主站用户的服务,比如评论、回答和推荐等。另一个是离线机房,主要部署一些离线计算相关的服务,比如我们常见的数据平台、离线存储以及OLAP引擎等。这两个机房之间依靠机房专线进行通信,所以机房专线很重要。
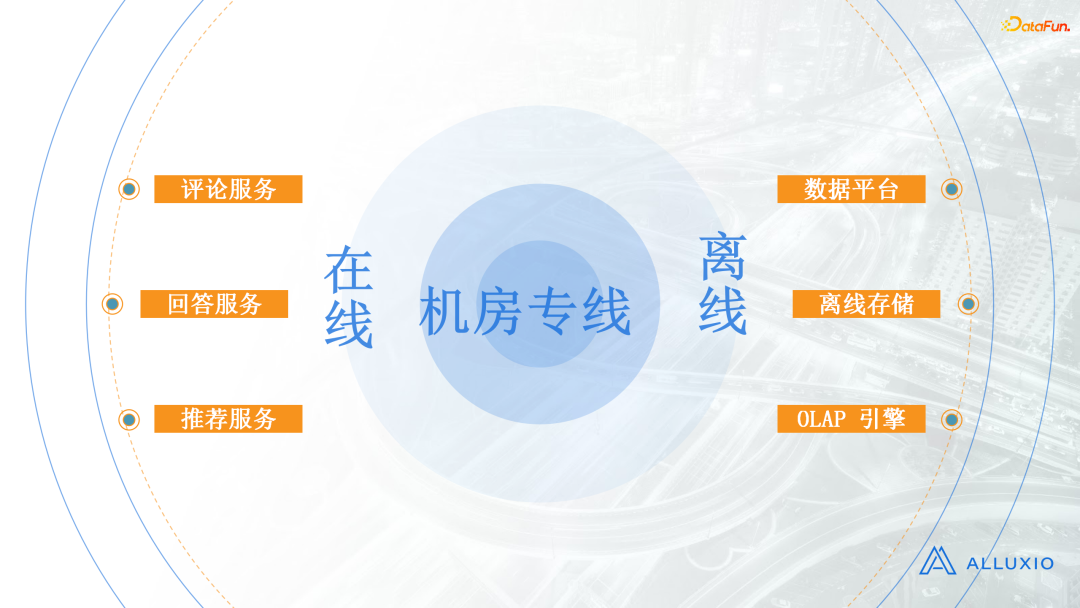
衡量机房专线是否稳定的重要指标之一,就是机房的流量。一般情况下,服务之间的调用不会影响到机房专线流量,因为服务之间的调用使用的机房流量非常少。但是在我们的算法场景中,有一类非常特殊的情况,它会直接占满整个机房专线。这就是接下来要介绍的推荐/搜索模型上线场景。
2、推荐/搜索模型上线场景

我们模型的产出,依赖于离线机房的机器学习平台和Spark集群进行大规模的分布式计算,模型最后写入到离线HDFS。模型上线的时候,推理服务容器会有几百个容器,多的甚至有上千个容器,同时去拉取HDFS上面的模型,这样会产生比较大的跨专线流量,会带来两个问题:
- 流量过大导致专线不可用,这时专线带宽直接被占满。
- 并发过高出现DN热节点。高并发拉取HDFS,因为都是拉取同一份模型文件,HDFS会出现DataNode热节点的问题。
3、多HDFS集群方案

早期我们解决这种模型上线问题的方案十分简单,就是多HDFS集群方案。相比于之前直接从离线HDFS拉取,我们在模型产出时,采用一个离线拷贝任务将模型拷贝到在线的HDFS,拉取的时候直接从在线HDFS读取模型。这样做有两个好处:
- 解决了专线流量问题。离线拷贝任务相当于模型只通过一次专线,而且因为离线拷贝任务是定期运行的任务,不会很多个任务一起拷贝,而是排队拷贝,所以这个专线的流量是可控的。
- 增加文件副本解决了热点问题。在线HDFS增加了文件的副本,解决了DataNode热节点的问题。
但是这种做法也存在一些不足:
- 多个HDFS集群维护困难。这里既有在线HDFS,又有离线HDFS。
- 引入了新的离线拷贝任务,文件视图难以维护。因为在线HDFS和离线HDFS的文件视图是不一样的业务,用起来会非常麻烦。
- 新建HDFS集群、增加文件副本都会导致存储成本激增。
二、自研组件阶段
接下来介绍我们迭代的第三个版本,就是我们的自研组件UnionStore。
1、自研组件——UnionStore
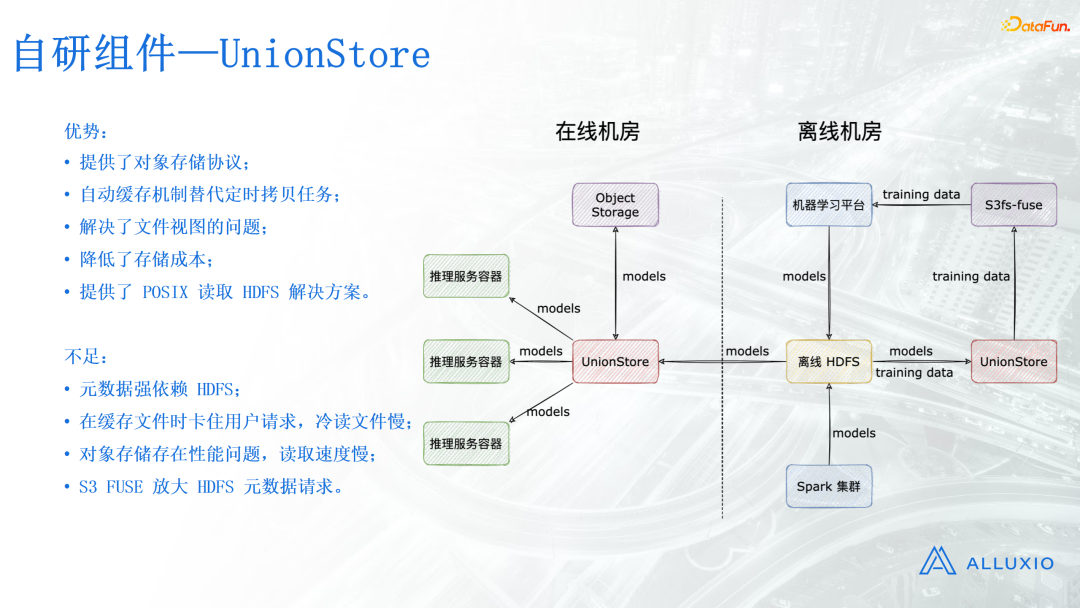
我们的多云缓存自研组件叫UnionStore。顾名思义,它是联合存储的意思,联合了HDFS和对象存储,对外提供对象存储的访问接口。其工作流程为:模型通过机器学习平台和spark产出,最后写入HDFS。读取的时候通过对象存储协议向UnionStore发出请求。UnionStore接收到读取文件请求后,会检查对象存储里面是否存在这个文件,如果存在就直接返回给用户,如果不存在就从离线HDFS进行读取,然后上传到对象存储,最后再从对象存储返回给用户。
2、UnionStore的优势
UnionStore的好处有以下几点:
- 提供了对象存储协议。
- 自动缓存机制替代定时拷贝任务。它有一个自动缓存机制,会先检查对象存储和HDFS的文件的一致性,然后看有没有缓存到对象存储上面去。它替代了原来的定时拷贝任务。
- 解决了文件视图的问题。因为UnionStore的文件视图强依赖于离线HDFS,所以它没有文件视图不一致的问题。
- 降低了存储成本。我们下线了一套HDFS集群,换成了对象存储,所以减少了存储成本。
- 提供了POSIX读取HDFS的解决方案。
这是UnionStore的第一个使用场景。UnionStore提供了对象存储的访问方式,它其实还可以做一件事情,就是用户可以把UnionStore用s3fs-fuse挂载到POSIX本地目录上,读取训练数据的时候直接通过本地目录来读,从而为机器学习平台提供更好的帮助。
这个方案一上线就备受用户好评。当时HDFS挂载采用了两种方式,第一种是Hadoop社区提供的HDFS挂载本地目录的方式,另外一种是以go语言写的HDFS挂载方式。但是这两种方案的重试都做得不够好。s3fs-fuse的重试做得比较好,所以我们选择了s3fs-fuse这种方式。
3、UnionStore的不足
UnionStore在知乎内部运行了足足两年时间,早期没有出现任何问题,但是随着模型规模的不断扩大,逐渐出现了以下问题:
- 元数据强依赖HDFS,在HDFS抖动的时候,有些需要频繁更新的模型文件会受影响,无法更新,UnionStore有时候不可用。
- 缓存文件时卡住用户请求,冷读文件慢。在缓存文件的时候,UnionStore会做检查,这个时候会卡住用户的请求,导致冷读文件十分慢。
- 对象存储存在性能问题,读取速度慢。这里不仅是单线程读取的速度很慢,而且对象存储整体是有带宽的,一般来说,假如云厂商比较靠谱,能够提供1TB左右的带宽,否则只有几百GB,显然不能满足我们的需求。
- S3 fuse组件放大HDFS元数据请求,带来比较大的性能压力。
以上缺点使我们面临两个选择,第一个方案就是继续迭代UnionStore,使它能够满足我们内部的需求;第二个方案就是寻找一个合适的开源解决方案,替代UnionStore的使用场景。基于人力资源的宝贵,我们选择了第2个方案,找一个合适的开源解决方案。
开源方案需要解决两个使用场景,第一个是模型读取加速场景,它要提供一个对象存储协议;第二个是模型训练加速场景,它要提供本地目录的一种访问方式。

三、Alluxio阶段
我们调研了很多开源解决方案,内部也有很多缓存组件,最后发现只有Alluxio能够满足我们的需求。Alluxio具有以下优势:
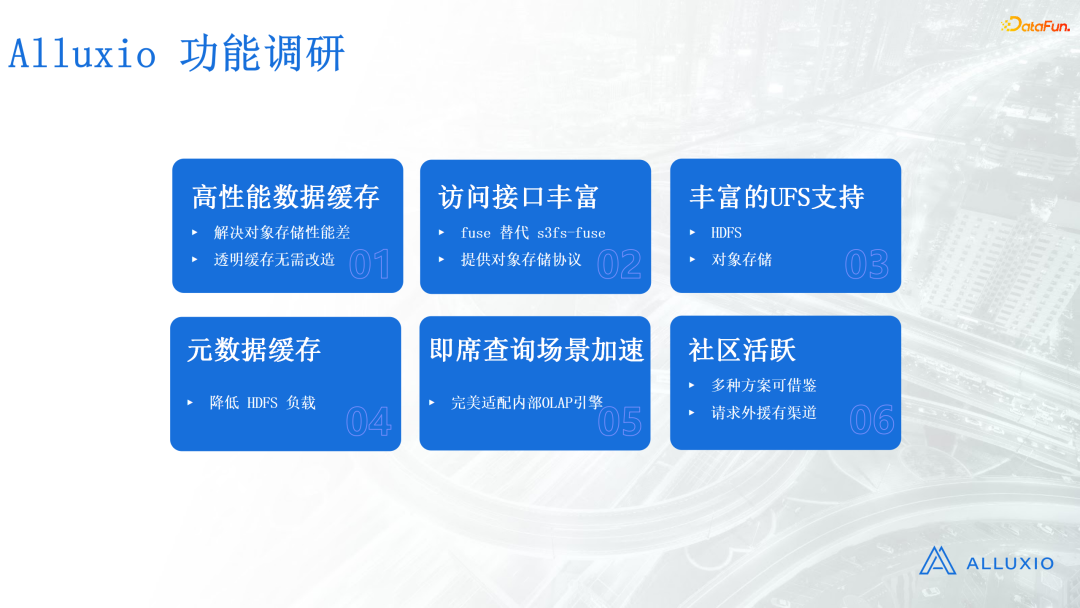
- 高性能数据缓存能力。它能够解决对象存储性能差的问题,其缓存是透明的,业务方无需改造就能够直接上线。透明缓存能力十分重要。我们之前也有一些其他多云缓存组件,缓存不是透明的,必须要向它那里写才能从它那里读,而我们的数据存在HDFS,因此无法满足需求。
- 访问接口非常丰富。它提供了Alluxio fuse,能够提供本地的文件访问方式,也提供了对象存储协议。
- 丰富的UFS支持。它能够同时挂载HDFS和对象存储。
这三点就已经能够满足我们的需求了,但是它还提供了另外三个功能:
- 元数据缓存,它能够有效降低NameNode的负载。
- 即席查询场景加速。它的即席查询场景加速适配是非常好的。我们内部把Spark和Presto作为主要的Ad-hoc场景查询,Alluxio社区有非常多的案例可以供我们借鉴。
- 社区活跃。模型上线的时候可以借鉴社区的各种方案,遇到问题也可以向社区请求一些支援,社区为我们提供了非常多的帮助。
通过调研确定功能满足我们的需求以后,我们使用它进行了模型的上线。
1、模型读取加速场景
第一个场景,模型读取加速场景,接下来将从客户端的选择、性能测试、部署与调优,以及上线效果这四方面来进行介绍。
(1)客户端选择—S3 Proxy
我们选择Alluxio S3 Proxy进行模型读取场景的加速,原因有以下几点:
- 用户当前使用的UnionStore对象存储协议与S3 Proxy天然兼容。
- 用户单个容器可用资源比较少,这就排除了Alluxio fuse,因为它比较依赖本地缓存,本地元数据缓存要消耗比较大的磁盘和内存。
- 用户读取文件的方式有三种语言:Python、Java和Golang。因为知乎最开始是用Python写主站程序的,后面才转成Golang和Java,所以这里也排除了Alluxio Java client,因为它只支持Java语言。
(2)Alluxio S3 Proxy性能测试

我们对Alluxio S3 Proxy进行了一系列的性能测试,对比了HDFS、UnionStore以及Alluxio,发现Alluxio在热读文件的时候,其性能远超另外两个组件,100GB文件热读的时间只有UnionStore的1/7,这个加速效果是非常明显的。
(3)部署方式
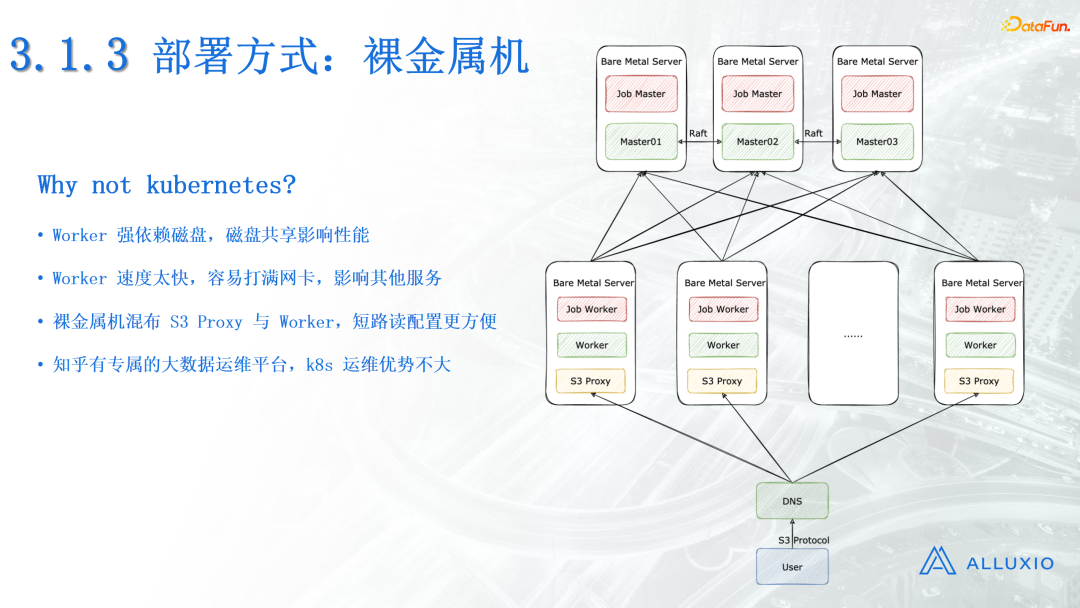
部署时我们选择了裸金属机部署,为什么没有选择K8S部署,原因有以下几点:
- Worker强依赖磁盘,如果和其他的应用程序共享磁盘,可能会影响Worker本身的性能。
- Worker读取速度太快,容易打满网卡,影响其他服务。如果进行K8S部署,假如有其他的服务跟Worker部署到同一个K8S节点,那么该节点的网卡资源将被占满,调用不了其他的服务。
- 裸金属机混合部署S3 Proxy与Worker,配置短路读更加方便。它天然支持短路读。
- 知乎有基于Ansible构建的专属的大数据运维平台,所以K8S的运维优势不大。
这里我们的部署方式是S3 proxy,最后通过DNS代理域名,供用户的访问。
(4)部署与调优
模型读取场景的调优,需要结合模型读取场景的特点来进行。模型读取场景有以下三个特点:
- 并发高。单一模型文件上线的时候流量能够达到1TB每秒。
- 过期快。模型文件只会在短时间内使用,读取完毕后即可视为过期。
- 缓存穿透。数据产出与数据读取的时间间隔短,只有几秒钟,所以基本上是无法进行提前预热的。
我们针对这三个特点进行了针对性的调优:
- 针对并发高的问题,文件的缓存副本没有设置上限,基本上每一个Worker都会缓存一个文件,每一个文件都会在每一个Worker存在一份,供客户端读取,并且我们把Worker与Proxy进行了混部使用,短路读节省流量。
- 针对过期快的问题,过期快对我们来说不是劣势,反而是一个优势,意味着集群存储容量可以非常小,Worker完全可以采取高性能磁盘。我们现在采用NVME磁盘,成本是可控的。
- 缓存穿透的问题,实际上是非常难以解决的,我们最后改了一些代码,自研了一些文件预热策略,然后进行实时的预热。
接下来详细说明各个调优策略。
- 调优一:短路读

左边的图是没有短路读的时候,用户在请求S3 Proxy读取文件的时候,会经过两层网络,第一层网络是用户到S3 Proxy,第二层网络是S3 Proxy到Worker,最后由Worker读取磁盘上的文件,这种情况下网卡的消耗非常大。
右边的图是短路读的情况,用户在请求了S3 Proxy以后,S3 Proxy会直接读取磁盘上的数据,无需经过Worker,这样相当于省下了S3 Proxy到Worker之间的流量。据我们线上的测试,大概能够节省30%到50%的流量。
- 调优二:文件实时预热策略

文件实时预热策略,通俗的讲,就是把Distributed Load的功能做到了S3 Proxy里面去。S3 Proxy接受下载请求时,会将文件分块,把每一个文件块提交到不同的Worker进行并发缓存。这样做的好处在于,下载文件时,前面可能没缓存,下载得很慢,但是读到后面文件的时候,因为其他的Worker可能已经把文件缓存完了,所以能够达到跟命中缓存几乎一样的速度。这种加速策略是文件越大,效果越明显。在读取大文件的时候,比如文件有10GB,这时读的速度比冷读提升到2-5倍;如果是100GB,基本上和热读没有区别。
第二个好处是顺序靠后的文件块,因为已经提前缓存了,能够节省UFS的流量,据线上数据验证,能够节省2-3倍的UFS流量。
再来看一下实时预热策略的效果,下图是线上的真实截图,里面的每一条线段都代表模型读取的一个请求,线段越长代表读模型花费的时间越长,读取速度越慢。
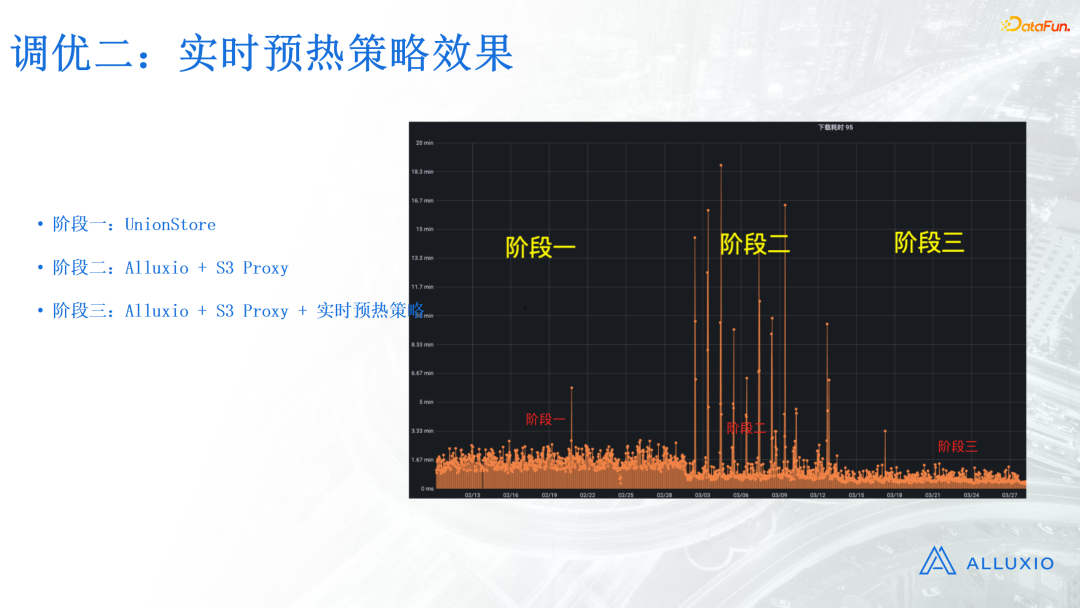
阶段一是用UnionStore读取的效果,阶段二是直接上线S3 Proxy读取的效果。可以看到整体的读取耗时下降了大概一半,但是出现了一些尖刺,说明有些请求可能会读得特别慢,这是因为Alluxio在冷读文件的时候性能下降得十分明显。
阶段三是上线了实时预热策略后读取的效果,可以看到所有的尖刺基本上消失了,而且文件整体的读取速度也有所提升,预热的效果是非常好的。
- 调优三:元数据缓存

第三个优化策略是做了一定的元数据缓存,分为三个阶段。上图也是线上的真实截图。阶段一是用UnionStore读取,速度非常慢;阶段二是直接上线S3 Proxy读取,可以看到时间降了一大截,速度几乎提升了一倍;阶段三是上线了一分钟的元数据缓存以后的情况,对比最开始UnionStore,速度提升了几十倍。
元数据缓存开启以后需要特别注意元数据同步,因为它可能会造成文件的不一致,所以我们也制定了一些文件的使用规范。比如新增文件,我们让用户尽量去写入新目录,以版本号的形式管理,尽量不要追加或覆盖旧文件。如果对于一些业务历史遗留的任务,实在需要对旧文件进行修改,我们也提供了一些比较特殊的方式。我们在S3 Proxy上改了一些代码,增加了特殊的命令,供用户来刷新元数据。

- 调优四:S3 Proxy限速

S3 Proxy限速的目的主要是为了保护Worker和业务容器,防止网卡打满。因为S3 Proxy的速度非常快,最高能够达到1.6GB的速度,对网卡的消耗非常大,所以要保护Worker的网卡和业务容器的网卡。这里我们做了两个限速,第一个是进行S3 Proxy进程的全局限速,这样可以保护Worker网卡。第二个是进行了单连接限速,保护业务所在容器的K8S节点,防止这个节点整体的网卡被打满。这个功能已经贡献给了社区,2.9.0以后的版本也都已经上线。
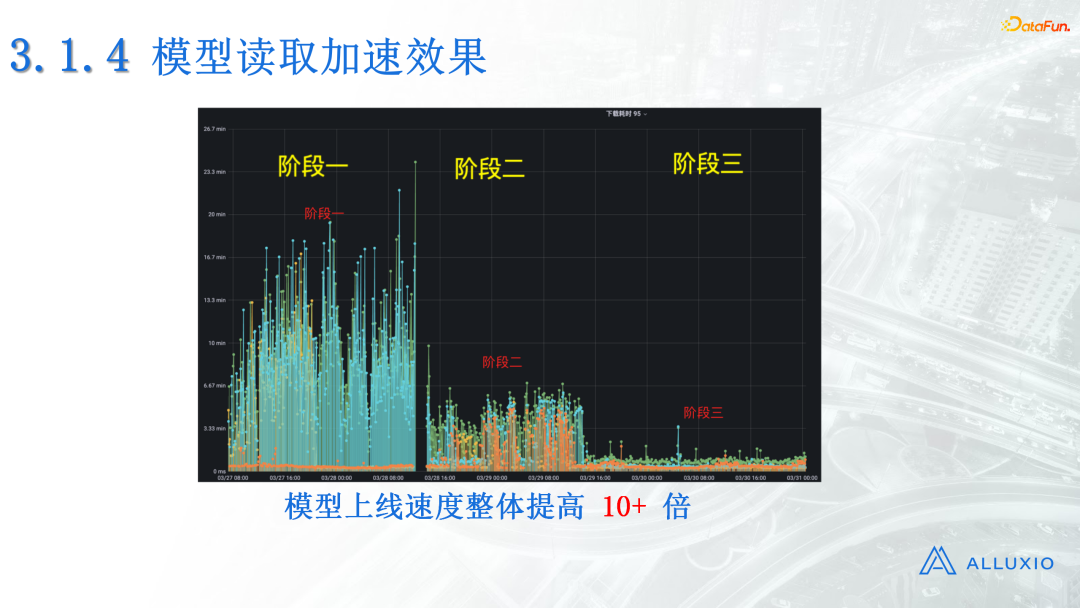
下图是模型读取加速的整体效果,可以看到速度提高了大概几十倍。当然这里的几十倍是因为我们的Alluxio集群是非常空闲的,真实的上线结果是UnionStore和Alluxio的速度一样,但是Alluxio用的资源只有UnionStore的一半,相当于是节省了50%的成本。
2、模型训练加速场景
第二个场景是模型训练加速场景,也从四个方面来介绍:客户端的选择、性能测试、部署与调优、上线效果。
(1)客户端选择——Alluxio fuse
客户端选择了Alluxio Fuse,原因有以下几点:
- 用户当前使用s3f3-fuse,它可以被Alluxio fuse替代。
- 模型训练框架对本地目录支持较好。比如Tensorflow、pytorch这些模型训练框架,对本地目录支持是最好的,其他的如S3可能也支持,但是没有本地目录支持得好,所以我们还是选Alluxio fuse。
- GPU机器是比较特殊的,它的瓶颈在于GPU,而不是内存、磁盘和CPU。它的内存、磁盘、CPU相对比较空闲,Alluxio fuse能够充分地利用这些闲置的资源,进行本地的数据缓存和元数据缓存。

(2)Alluxio fuse性能测试
选择了客户端以后,我们对它进行性能测试。测试选用官方的默认配置,这里有两个跟官方默认配置不同的点,一个是开启了一定的内核元数据缓存,另一个是容器的总内存非常大,原因是我们想用内核元数据缓存。
我们以本地磁盘作为测试基准,测试的结果如下。本地磁盘的顺序读是1800 MB/S,随机读是1000 MB/S,fuse 1G实际文件顺序读的时候,达到了1700 MB/S的速度,基本达到本地磁盘90%的性能,这是非常高的性能了。fuse 100G文件顺序读的时候,性能急速下降,这是因为我们之前容器的内存是40GB,它没有充足的page cache来缓存100GB文件,而对于1GB和10GB的文件是有充足的缓存命中的,所以它的性能会降低一半。

fuse随机读的性能相对较差,只有450 MB/S,但也能满足我们的模型训练的需求,整体上符合预期。
(3)部署与调优
模型训练场景的调优需要结合它的特点进行。模型训练场景也有3个特点:
- 资源充足。GPU机器除了GPU以外,其他的资源都比较空闲。
- 独占。GPU机器只运行模型训练任务,它不会和其他服务进行混部,如果不运行训练任务,它就是空闲的。
- 文件快照。训练数据是以文件快照的形式进行组织的,不会时常更新它,所以它对元数据的一致性要求比较低。
我们采用DeamonSet的形式来部署fuse进程。我们用host path一层一层地挂载缓存数据的目录,然后提供给模型训练容器来使用。
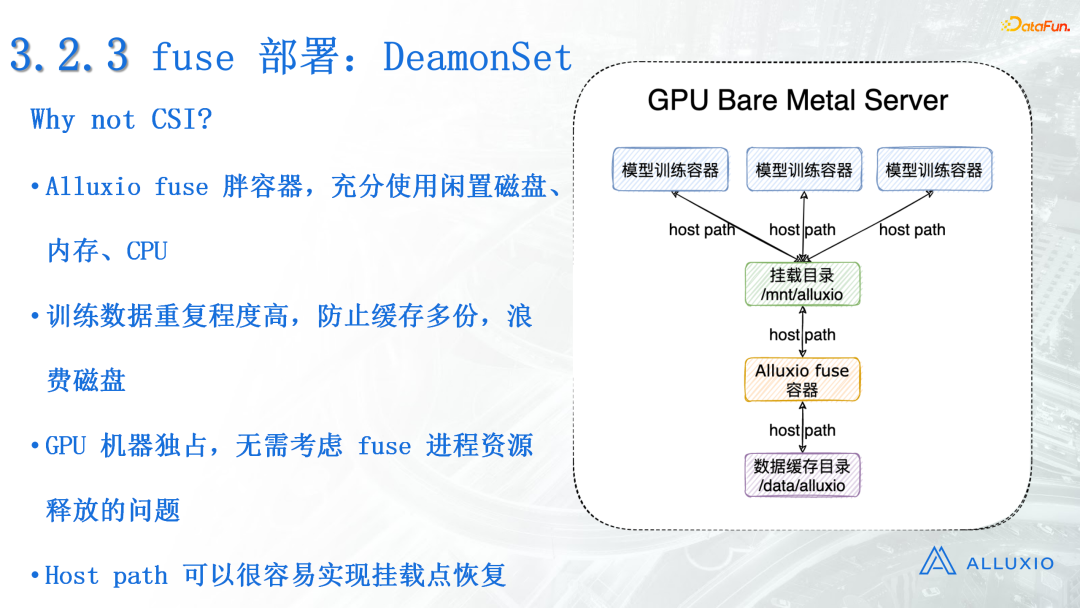
- Fuse本身提供了CSI的部署方式,但是我们没有选,主要是基于以下几点考虑:首先就是GPU机器的老问题,它大多数情况下是非常空闲的,所以Alluxio fuse可以提供一个超级大的胖容器,让它充分的使用闲置的磁盘、内存和CPU。
- 第二个是训练数据的重复程度高,在分布式训练的时候,所有的节点可能会去读同一份数据,如果用CSI的话,可能同一个GPU机器上启动了多个fuse进程,它们将同一个文件缓存了多份,这样比较浪费磁盘。
- 第三个是GPU机器的独占性,不需要考虑fuse进程资源释放的问题。即使训练容器退出了,也不需要释放,它可以长时间运行。
- 最重要的一点就是DeamonSet加上host path的方式,可以很容易实现挂载点恢复,这样即使是在fuse进程退出以后,当场读文件失败了,只要用户配置了重试,也是可以重新拉起来的。

接下来我们结合fuse,看一下整个Alluxio集群的部署方式。我们采取小集群重客户端的方式,顾名思义,Alluxio集群其实是非常小的,它只有3个支持Raft协议的master节点以及3个Worker节点,但是它支撑了上百台GPU机器,这里大概是100-300台GPU机器,包括几PB的NVME存储。有数百个fuse进程部署在GPU机器上。每个fuse进程都有10TB的NVME做本地缓存。这样相当于Alluxio集群其实只做了一件事情,就是数据的分发,其他的如性能保障之类的事情就完全交给fuse进程本地完成了。
最后是Alluxio的调优。它的调优项非常简单,我们仅做了少许改造,其他都是官方配置。
- 首先是适当地增加本地缓存页的大小,因为官方配置的本地缓存页太小,默认是1MB,在读大文件的时候性能很差,我们把它改成了16MB。
- 第二个是开启内核元数据缓存。从前面的测试结果来看,开启了内核元数据缓存可以使性能提升一倍。
- 第三个是推荐使用短内核元数据缓存时间配合一个长时间的metadata sync时间,这样可以让每个fuse基本都能够读到相同的文件版本。
- 第四个是实现挂载点恢复防止fuse进程意外重启。我们发现在容器里面部署fuse,在容器里面实现存储会遇到很多奇怪的问题。如果有一种自动恢复的手段,能够大大提高它的稳定性。
(3)模型训练加速效果
从实际加速效果来看,模型训练整体提速60%,本来需要训练10天的模型,现在只需要6天就可以训练完毕。另外,训练模型时读取数据的速度也提升了2.5倍。
3、补充场景
我们内部还有一个比较有意思的场景,就是大数据运维场景,这也是我们的补充场景。
(1)大数据组件发布与上线(优化前)
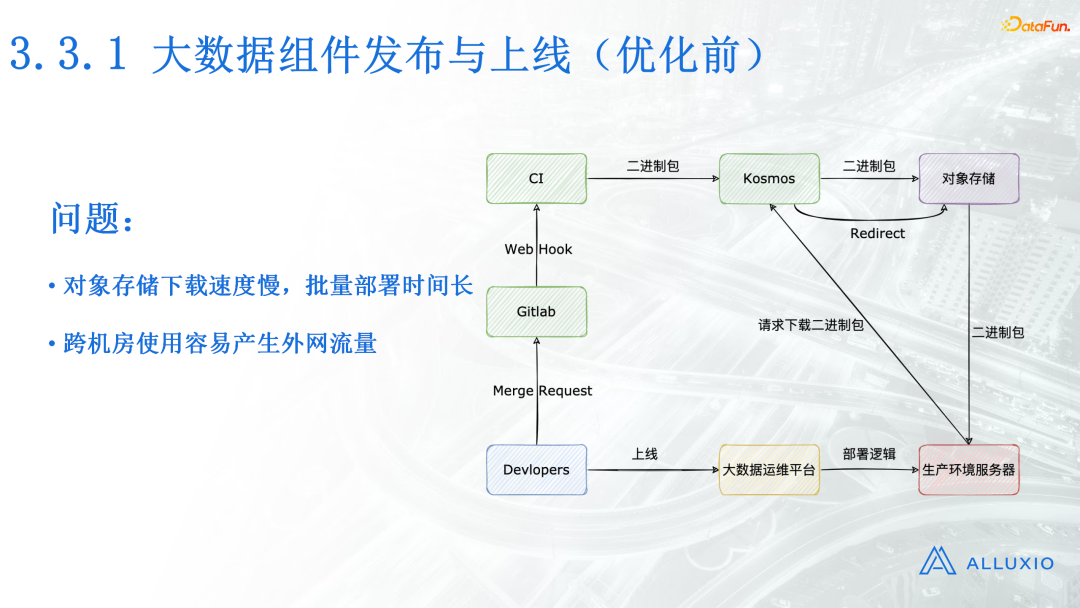
首先介绍一下我们大数据组件的发布与上线流程。比如上线一个大数据组件,用户开发者首先提交他的任务到GitLab,GitLab在收到合并代码请求以后,会调用CI的Web Hook,自动帮用户构建打包,然后把二进制包上传到Kosmos。这里的Kosmos是我们内部的包管理服务,Kosmos在收到二进制包后,会转存到对象存储,这是发布过程。
再看上线过程。开发者在大数据运维平台点击新版本上线,然后大数据运维平台会把部署逻辑分发到生产环境服务器。生产环境服务器运行部署逻辑,如果中途要下载包,它会请求Kosmos进行下载。Kosmos在接收下载请求以后,会将请求重定向到对象存储,这个时候生产环境服务器直接从对象存储拉取二进制包,整个流程是非常完美的。唯一的瑕疵出现在对象存储下载二进制包的时候,它会有以下两个问题:
- 对象存储下载速度慢,批量部署时间长。单线程对象存储的下载速度只有10-30M,在批量部署DataNode的时候,花费的时间非常长。以1万台DataNode为例,如果我们按两台滚动重启,每一个就接近半分钟的下载时间,整体合计的部署时间在48小时以上。
- 跨机房使用容易产生外网流量。这是因为我们只用了一个对象存储,如果其他地方的技术组件进行部署,而且不在同一个机房的话,它会产生外网流量,这个成本相当高。
(2)大数据组件发布与上线(优化后)

我们用Alluxio对这个流程进行了一些优化,过程很简单。我们把Kosmos用的对象存储直接挂载到Alluxio上,因为Alluxio不仅支持HDFS的挂载,还支持对象存储的挂载。生产环境服务器在下载包的时候,会直接向S3 Proxy请求二进制包。由于是在Alluxio下载的,它的速度非常快,如下图所示,这是一个对比图,展示了最后上线后的效果。

图中的红圈是从对象存储下载的速度,大概是十几MB/S,从Alluxio下载大概是600 MB/S。这里的600 MB/S,是压制下的情况,考虑到前述提及的优化方案,即S3 Proxy进行限速,我们限速为600 MB/S,它其实最高能够达到1600 MB/S。
四、总结
最后进行一个技术总结。回顾我们多云缓存的发展历程,从最开始的暴力读取,到后来的多HDFS集群,再到自研组件UnionStore,都不能满足我们的需求。最后我们上线了Alluxio,才满足需求。

Alluxio为我们带来了哪些提升?首先是性能方面,整体上有2-5倍的性能提升。另外是稳定性方面,它解除了HDFS的强依赖。最后是成本方面,它为我们节省了大约一半的成本。
未来我们计划在数据编排领域以及OLAP加速的场景来使用Alluxio。因为我们有一些人工智能的场景需要用到小文件,所以我们比较期待它的新一代架构,Dora架构。

五、讨论交流
1.Hive使用Alluxio怎么让用户历史创建Hive表尽量少的改动?
答:这个问题我猜可能是不想改Hive表的location,不想让它从HDFS的开头改成Alluxio开头。我们现在还没做OLAP引擎的加速,但是我们目前有一个备选的方案。我们可能会对Hive的MetaStore做一些改造,在计算引擎读取HDFS上面的分区时,如果已经缓存到Alluxio,我们会直接在Hive MetaStore内进行修改,然后把HDFS前缀直接修改成Alluxio前缀。这样就不用改Hive的location。
2.刚刚提到那个页的大小,调优从1MB变成了16MB,这是怎么调出来的?为什么不是32MB?
答:业务读取数据的时候,它不仅有大文件,也有小文件,如果这个值太大的话,对小文件支持不好,太小的话又对大文件支持不好。所以我们根据实验经验,选了一个相对折中的值。
3.Alluxio在冷读的时候性能下降得比较明显,然后通过预热的方式来解决这个问题。请问是怎么做预热的?
答:比如我们现在有一个用户向S3 Proxy请求512 MB的文件,然后S3 Proxy从master拉取到这个文件的元信息,可以看到它有四个块,每个块是128 MB大小。对这四个块,我们会通过一个特殊的算法,可以是哈希也可以是别的,分别打到不同的worker进行缓存。S3 Proxy在读取的时候可能会先下载,比如说下载块1,但块1可能还没缓存,所以它是直接从UFS读取再返回给用户,可能会很慢。在读块2的时候,它可能已经被缓存完了,这种情况下读取是非常快的。然后在读块3、块4的时候可能也都缓存完了,也读取的很快。我们是这样来做的。这里要求文件的 block数要大于1,否则就没有必要去进行加速,因为文件本身比较小,就算性能差,它也能很快地读完。
4.刚刚提到利用Alluxio做元数据缓存,元数据到底里面有哪些东西?
答:元数据缓存在Alluxio里面分为三块,第一块是UFS的元数据,比如对象存储的元数据,它会在master里面进行缓存。第二块是fuse,就是客户端本地的元数据缓存。这个比较常见,fuse会用内存来缓存一次master的元数据。第三块是内核元数据,这个也是fuse里面比较常见的,它是操作系统层面的缓存,缓存操作系统本地的目录情况。
元数据缓存对性能有很大的影响。不开启元数据缓存的时候,比如我们不缓存UFS的元数据,那么客户端的每一次请求都会穿透到UFS上面去,性能会非常差。特别是在对象存储的时候,比如要list一个目录,对象存储list目录的性能是非常差的,有时候可能要花好几秒。
我们这里设置了1分钟的缓存超时时间。1分钟的元数据缓存其实也是一个折中的做法,就是要尽可能的让用户很快地感受到他的文件有变更,同时也要做一定程度的缓存。如果对元数据一致性要求不是那么的严格的话,其实也可以调成1小时、几小时或者几天都行,或者手动刷新都可以。这个只能根据场景来调优。
5.模型上线和模型训练场景里边都有对象存储,它具体是用的云上的对象存储,还是本地的对象存储?它的连接接口都是用标准S3协议连接的吗?
答:我们直接买的云厂商的对象存储服务。因为自己搞一套对象存储,这个成本太高了。
这里涉及到两种S3协议。一方面UnionStore本身对外提供S3协议,这个组件是我们自研的;另一方面UnionStore利用S3协议与对象存储交互,对象存储是从云厂商买的。
6.模型训练场景中,GPU集群刚开始是几百个节点,但是Alluxio用的是一个小集群的部署,3个master加3个worker的部署,这个小集群架构能满足整个热数据的拉取容量以及并发访问需求吗?
答:这个需要结合Alluxio自己目前有的一个问题来解决。目前fuse从集群读数据的时候是非常慢的,这是Alluxio的一个缺陷,它最高只能达到200MB/S左右的速度,所以其实它怎么读也读不满Worker的网卡。这个我们已经和Alluxio社区沟通过好多次了,Alluxio下一个版本会解决掉这个问题,我们也非常期待,到时我们可能也会做一些版本升级和架构升级,比如会把Worker扩一下,或者把Worker直接和业务部到一起。