













在设计大规模分布式系统时,你可能会遇到两个概念——分片(sharding)和一致性哈希(consistent hashing)。虽然我在网上找到了很多关于这些术语的解释,但它们让我感到有些困惑。我觉得分片和一致性哈希本质上是在讨论同一件事——将数据分布在一组服务器上。
我想—这两个概念是不是相同的,还是有所不同?如果你也有类似的困惑,让我们简要地来解释一下。
分片
想象一下我们有一个数据库,其中数据以行和列的形式存储(就像关系型数据库,尽管分片也适用于NoSQL数据库)。当我们的数据集变得非常庞大时(比如1百万条记录),对庞大数据集进行任何类型的操作(读取、更新、删除、连接等)都会变得非常缓慢。而且随着数据量的增长,由于服务器可能具有的物理空间(HDD/SSD)的限制,将所有数据存储在一个数据库服务器上几乎是不可能的。为了解决这些问题,最合理的方法是将数据集划分为较小的数据集。
想象一下,我们将整个数据集(100万行)划分为10个较小的子集(每个子集有10万行)。这个将数据集水平(或沿着行)划分的过程被称为对数据集进行分片。
除了提高性能外,分片数据集的另一个非常重要的好处是将这些数据分片存储在较小且更便宜的数据库服务器上,而不是将整个百万行存储在一个庞大且非常昂贵的数据库服务器上。
一致性哈希
一致性哈希是一种将庞大的数据集(例如100万行)分割成多个较小的数据子集(存储在一组数据库服务器上)的技术,以确保在集群中的服务器数量发生变化(即添加或删除服务器)时,数据的迁移量最小。在大规模分布式系统设计中,这非常重要,因为服务器故障在数据中心中相当常见。
对于一致性哈希,我们选择两个值M和N,即哈希键空间(根据应用程序需求选择的M)和数据库服务器数量(用N表示)。通常情况下,M >> N。
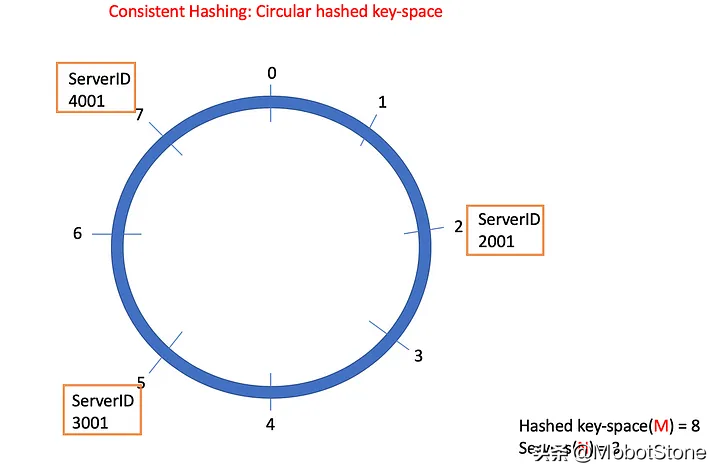
算法本身是一个简单的三步过程。
创建一个循环数字线(从0到M-1)。 对数据库服务器ID进行哈希运算,对M取模,并在循环数字线上分配一个位置。 对每个数据行进行哈希(基于其唯一键),对M取模,并在循环数字线上找到其位置。顺时针方向移动,直到找到第一个数据库服务器。将这些数据存储在该服务器上。
好了..那么它们之间有什么真正的区别吗? 尽管分片和一致性哈希看起来都可以将巨大的数据集分割成较小的数据集,但它们之间存在微妙的区别。分片是所有水平数据分区方案的统称。从本质上讲,分片只是将数据集沿着行进行划分的一个花哨的名字。
如果你觉得水平分割(或分片)数据集可能有许多不同的方式,那么你是对的。在许多不同的分片数据集的方式/算法中,一致性哈希是最高效的算法之一。所以,这是一个相当简单但微妙的区别。分片是一个通用术语,而一致性哈希是一种特定类型的算法,用于实现数据分片。























