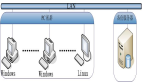
在Web前端中实现断点续传功能的一种常见方式是使用HTTP Range请求和文件分片上传。

以下是一个简单的断点续传实现的步骤:
- 前端将要上传的文件分成多个固定大小的片段(chunk),例如每个片段的大小为1MB。
- 当用户选择上传文件时,前端发送一个初始请求到服务器,询问服务器当前已上传的文件大小(如果之前有上传过该文件)。
- 服务器通过响应返回已上传的文件大小给前端。
- 前端根据服务器返回的已上传文件大小,计算出还需要上传的文件片段。
- 前端使用File API的slice方法将剩余的文件分片进行上传。同时,在每次上传片段时,设置HTTP请求的Range头部,指示上传的起始位置。
- 服务器接收到文件片段后,根据Range头部确定文件的上传位置,并将数据追加到对应的位置上。
- 重复步骤5-6,直到所有文件片段都上传完成。
- 可选:前端可以在每次上传完一个片段后,更新进度条或显示上传进度。
需要注意的是,服务器端也需要相应的逻辑来处理断点续传的请求,并将上传的文件片段正确拼接到最终的文件中。
以上是一个基本的断点续传的实现思路,具体的代码实现可能会因具体的技术框架和需求而有所不同。
具体代码如何实现
以下是一个基于JavaScript和Node.js的简单示例:
前端代码(使用Fetch API):
const uploadFile = async (file) => {
const CHUNK_SIZE = 1 * 1024 * 1024; // 1MB
let start = 0;
let end = Math.min(CHUNK_SIZE, file.size);
while (start < file.size) {
const chunk = file.slice(start, end);
const formData = new FormData();
formData.append('file', chunk);
await fetch('/upload', {
method: 'POST',
body: formData,
headers: {
'Content-Range': `bytes ${start}-${end - 1}/${file.size}`,
},
});
start = end;
end = Math.min(start + CHUNK_SIZE, file.size);
}
console.log('Upload complete');};const fileInput = document.getElementById('file-input');fileInput.addEventListener('change', (event) => {
const file = event.target.files[0];
uploadFile(file);});后端代码(使用Express.js):
app.post('/upload', (req, res) => {
const rangeHeader = req.headers['content-range'];
const fileSize = parseInt(rangeHeader.split('/')[1]);
const [start, end] = rangeHeader.replace(/bytes=([0-9]+)-([0-9]+)/, '$1-$2').split('-');
// 在此处处理文件上传逻辑,将接收到的文件片段追加到最终文件中
// 例如,可以使用fs模块将片段写入磁盘上的文件
res.sendStatus(200);});请注意,以上示例是一个简化的版本,实际的代码可能需要添加错误处理、进度更新等功能。另外,您还需要根据自己的具体需求和技术栈进行相应的调整和完善。
断点续传中,如何判断是否为同一文件
在断点续传中,判断是否为同一文件可以使用文件的唯一标识来进行比较。通常情况下,我们可以使用文件的名称或者文件的MD5值作为文件的唯一标识。
具体实现方式如下:
前端:
- 在选择文件时,获取文件的名称或者计算文件的MD5值。
- 将文件的名称或者MD5值保存在一个变量中。
后端:
- 接收到上传请求时,从请求参数或HTTP头部中获取文件的名称或者MD5值。
- 将文件的名称或者MD5值与服务器上已有的文件进行比较,判断是否为同一文件。
注意:由于JavaScript的安全限制,无法直接在前端计算文件的MD5值。您可以选择使用第三方库或者调用后端API来获取文件的MD5值。
另外,如果您希望确保文件的唯一性并避免重复上传,可以在服务器端存储文件的相关信息,并在每次上传前进行检查。这样可以避免重复上传相同的文件。