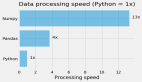
在本文中,我们将探讨几种通过迭代和向量化技术来提高Pandas代码性能的方法。
迭代是遍历数据结构元素的过程,而向量化是将操作同时应用于整个数组或数据系列的一种方法,利用底层优化来提高效率。
通过有效地使用这些技术,我们可以加速数据分析任务并提高代码的效率。
理解迭代和向量化的区别
在这个例子中,我们将使用NumPy比较迭代和向量化的性能。
首先,导入所需的库并创建一个随机数据集。
import numpy as np
import time
# 创建一个包含1000万个数据点的随机数据集
data = np.random.rand(10000000)
data.shape(10000000,)
现在,使用for循环(迭代)来计算数据集中各元素的总和。
start_time = time.time()
sum_iter = 0
for i in data:
sum_iter += i
end_time = time.time()
print("Iteration - Sum:", sum_iter)
Print("Iteration - Time taken:", end_time - start_time, "seconds")(‘Iteration — Time taken:’, 3.507000207901001, ‘seconds’)
接下来,使用NumPy的内置函数(向量化)来计算数据集中各元素的总和。
start_time = time.time()
sum_vec = np.sum(data)
end_time = time.time()
print("Vectorization - Sum:", sum_vec)
print("Vectorization - Time taken:", end_time - start_time, "seconds")(‘Vectorization — Time taken:’, 0.006000041961669922, ‘seconds’)
通过比较两种方法所需的时间,可以观察到向量化所实现的性能提升。
使用向量化函数加速操作
在这个例子中,我们将演示如何使用向量化函数来加速Python中的操作。我们将比较使用for循环和向量化函数执行操作所需的时间。
首先,导入必要的库并创建一个包含随机数的数组。
import numpy as np
import time
# 创建一个包含100万个随机数的数组
data = np.random.rand(1000000)
data.shape(1000000,)
现在,使用for循环执行操作,并计算出所需的时间。
使用for循环
start_time = time.time()
result = []
for value in data:
result.append(value * 2)
end_time = time.time()
for_loop_time = end_time - start_time
print("Time taken using a for loop: ", for_loop_time)(‘Time taken using a for loop: ‘, 0.3400001525878906)
接下来,使用向量化函数执行相同的操作,并计算出所需的时间。
使用向量化函数
start_time = time.time()
result = data * 2
end_time = time.time()
vectorized_time = end_time - start_time
print("Time taken using a vectorized function: ", vectorized_time)(‘Time taken using a vectorized function: ‘, 0.059999942779541016)
最后,比较一下两种方法所需的时间。
print("Speedup factor: ", for_loop_time / vectorized_time)(‘Speedup factor: ‘, 5.6666746139602155)
正如在示例中所看到的那样,向量化函数比for循环快得多。这是因为向量化函数利用了底层优化和硬件能力,使它们更加高效地处理大型数据集上的操作。
使用NumPy向量化优化代码
向量化是将一个逐个处理元素的算法转换为一个等效的同时处理多个元素的算法的过程。
这可以带来显著的性能提升,特别是在处理大型数据集时。
让我们从创建一个简单的NumPy数组并使用迭代和向量化进行加法运算开始。
首先,导入所需的库并创建一个NumPy数组。
import numpy as np
import time
# 创建一个包含1000万个元素的NumPy数组
arr = np.arange(1, 10000001)
arrarray([ 1, 2, 3, …, 9999998, 9999999, 10000000])
现在,使用迭代(for循环)执行加法运算。
# 使用for循环进行迭代
start_time = time.time()
result = np.zeros(len(arr))
for i in range(len(arr)):
result[i] = arr[i] + 1
print("Time taken for iteration: {} seconds".format(time.time() - start_time))Time taken for iteration: 7.158999681472778 seconds
接下来,使用NumPy向量化执行相同的加法运算。
# 使用NumPy进行向量化
start_time = time.time()
result_vectorized = arr + 1
print("Time taken for vectorization: {} seconds".format(time.time() - start_time))Time taken for vectorization: 0.01999974250793457 seconds
你会注意到向量化所需的时间明显低于迭代所需的时间。这展示了NumPy向量化在优化代码性能方面的强大作用。
现在,看另一个使用更复杂的操作的例子——计算两组点之间的欧几里得距离。
# 创建两组点
points_a = np.random.random((1000000, 2))
points_b = np.random.random((1000000, 2))首先,使用迭代法计算欧几里得距离。
def euclidean_distance_iterative(points_a, points_b):
num_points = len(points_a)
distances = np.zeros(num_points)
for i in range(num_points):
distances[i] = np.sqrt(np.sum((points_a[i] - points_b[i])**2))
return distancesstart_time = time.time()
result_iterative = euclidean_distance_iterative(points_a, points_b)
print("Time taken for iterative Euclidean distance: {} seconds".format(time.time() - start_time))Time taken for iterative Euclidean distance: 7.052000045776367 seconds
现在,使用NumPy向量化计算欧几里得距离。
def euclidean_distance_vectorized(points_a, points_b):
return np.sqrt(np.sum((points_a - points_b)**2, axis=1))start_time = time.time()
result_vectorized = euclidean_distance_vectorized(points_a, points_b)
print("Time taken for vectorized Euclidean distance: {} seconds".format(time.time() - start_time))Time taken for vectorized Euclidean distance: 0.03600001335144043 seconds
同样,你会注意到向量化方法所需的时间要比迭代方法低得多。
总之,使用NumPy的向量化可以极大地提高代码性能,特别是在处理大型数据集时。在处理数值运算时,可以考虑向量化你的代码,从而获得更好的性能。