自“千模大战”兴起,金融、医疗、教育等拥有数据积累的多领域企业,纷纷加入大模型队伍,发布垂类大模型。垂类大模型以深度解决行业需求为主,即大模型需要具备丰富的专业领域知识,才可能创建出更符合特定垂类场景的“产业版GPT”。
不过,创建大模型并非易事,通常会面临数据、计算资源、模型和算法设计、训练时效、模型验证调优等多方面问题,耗费大量人力、物力、财力后,依然效果甚微,而使用虎博科技的开源大模型Tigerbot则可得到解决,用户最快可在30分钟内无代码的训练和使用专属于自己的大模型和数据。
据了解,虎博科技在发布开源大模型Tigerbot的同时,也发布了大模型应用开发所需的全套API,包括对话(Chat)、插件(Plug-ins)、微调(Fine-Tunes)等,并开放金融、法律、百科等多个专业领域数据,在高效果和高效率双方面,为用户提供了充分保障。
对话方面,Chat-API 为 TigerBot 对外提供的可直接使用的 api,支持 Tigerbot-7B 和 Tigerbot-180B 两种模型的选择;插件方面,除了Tigerbot提供的自研插件,可用api调用外,用户还能管理自己的数据,训练专属插件;微调则更加人性化,用户仅仅按照数据要求管理上传自身数据,即可无代码快速训练出基于 TigerBot 大模型能力基础的自己的模型。
Tigerbot是虎博科技自研的多语言多任务大规模语言模型,10人团队历经三个月超过3000次实验后诞生。目前覆盖生成、开放问答、编程、画图、翻译、头脑风暴等15大类能力,支持子任务超过60种。经测试体验,Tigerbo能胜任写广告语、做表格、纠正语法错误等不同任务,也支持多模态文生图的需求。
目前,虎博科技共推出70亿参数(TigerBot-7B)和1800亿参数(TigerBot-180B)两种规模的模型。根据OpenAI InstructGPT 论文在公开 NLP 数据集上的自动评测,TigerBot-7B 版本已达到 OpenAI 同样大小模型的综合表现的 96%,尤其在推理式问答等个别领域表现更为亮眼,而这一版本还只是MVP(最小可行性模型)。
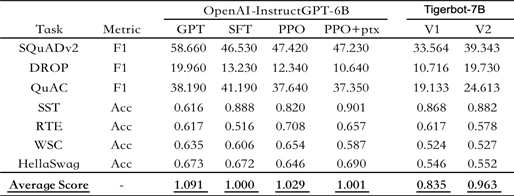
(上图为公开 NLP 数据集上的自动评测,以OpenAI-instruct GPT-6B-SFT为基准,归一化并平均各模型的得分情况)
虎博科技创始人兼CEO陈烨希望通过提供Tigerbot API构建生态蓝图,“大模型是人工智能时代的基础设施,而生态的发展则能反哺大模型的能力,实现技术与产业发展的共荣共生,也可与广大开发者一同打造中国的世界级应用。”
此外,Tigerbot在发布之际便开源,涉及模型、代码、数据三部分内容,包含 TigerBot-7B-sft、 TigerBot-7B-base、TigerBot-180B-research 等多个模型版本;基本训练且覆盖双卡推理 180B 模型的量化和推理代码;以及达 100G 的预训练数据、监督微调 1G/100 万条数据。(开源地址:https://github.com/TigerResearch/TigerBot )
据了解,虎博科技成立于2017年,以让人们获取知识更简单为愿景,其专注于深度学习和NLP技术的研究和应用已得到了广泛认可。此次自研大模型TigerBot发布并开源,更标志着这家专注于深度学习和自然语言处理技术的算法公司在大模型研发领域取得了重要突破。