大家好,我是小米。今天我们来探讨一下数据库索引原理以及底层索引数据结构,同时还会介绍叶子节点存储的内容以及索引失效的情况。废话不多说,让我们开始吧!
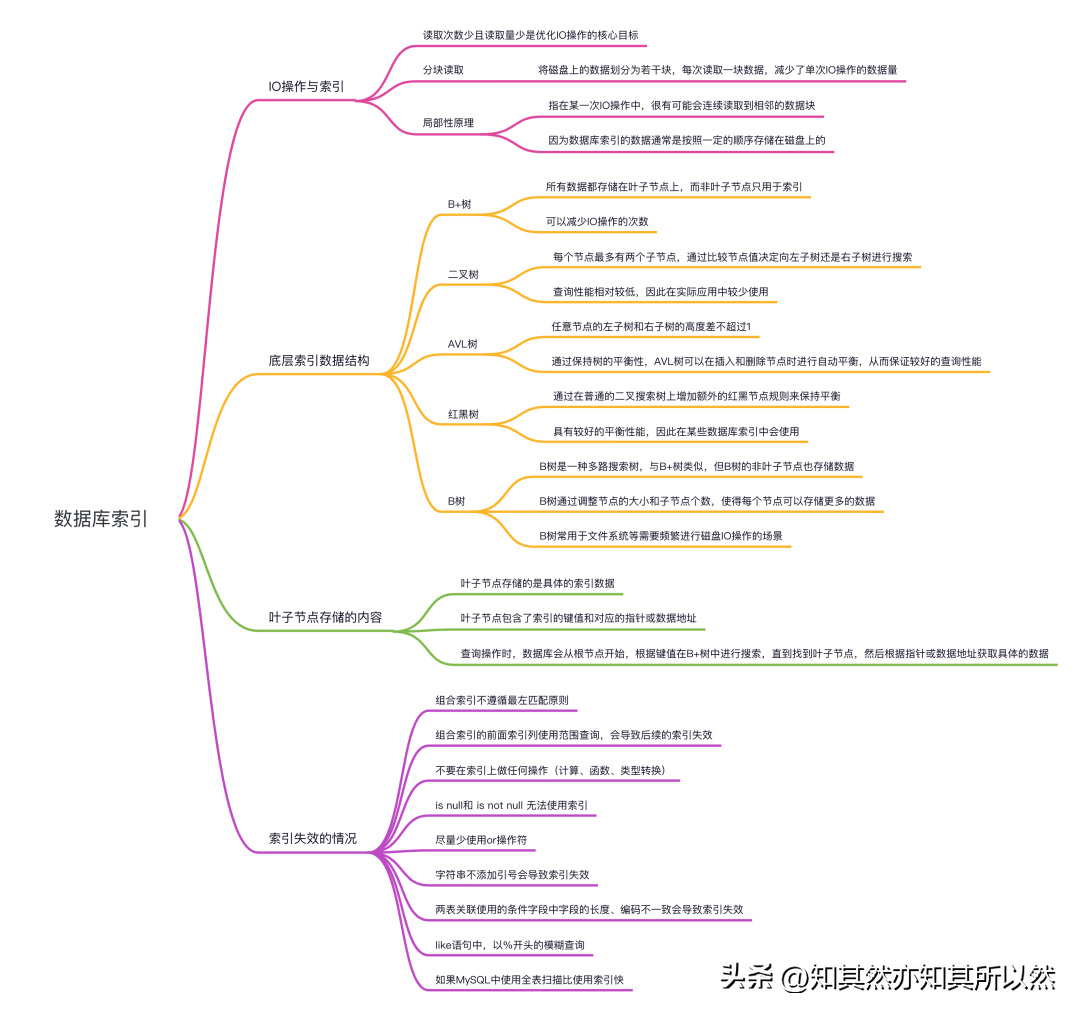
IO操作与索引
首先,我们先来了解一下IO操作对于数据库索引的影响。IO(Input/Output)操作是指从磁盘中读取或写入数据的过程。IO操作是数据库性能的瓶颈之一,因为相对于内存来说,磁盘的读写速度较慢,每次进行IO操作都需要耗费时间和资源。因此,在数据库中,我们希望尽量减少IO操作的次数,以提高数据库的性能。而索引在这方面扮演了非常重要的角色。
读取次数少且读取量少是优化IO操作的核心目标。为了达到这个目标,我们可以采用分块读取和局部性原理。
- 分块读取:将磁盘上的数据划分为若干块,每次读取一块数据,减少了单次IO操作的数据量。这样做的好处是,如果我们只需要查询某个块中的数据,就不需要读取整个表或索引的数据,从而减少了IO操作次数。
- 局部性原理:局部性原理是指在某一次IO操作中,很有可能会连续读取到相邻的数据块。这是因为数据库索引的数据通常是按照一定的顺序存储在磁盘上的。当我们查询某个索引时,由于数据的有序性,磁盘预读机制会帮助我们预先将相邻的数据块读入内存,提高查询效率。
底层索引数据结构
接下来,我们来了解一下底层索引数据结构。在数据库中,常见的底层索引数据结构有B+树、二叉树、AVL树、红黑树以及B树等。
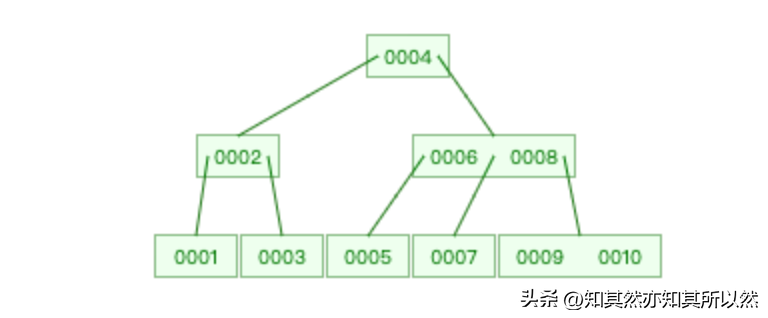
- B+树:B+树是最常用的底层索引数据结构之一。它是一种平衡的多路搜索树,具有较好的查询性能。B+树的特点是,所有数据都存储在叶子节点上,而非叶子节点只用于索引。这样做的好处是,可以减少IO操作的次数。B+树的叶子节点通过指针连接起来,形成一个有序链表,方便范围查询。
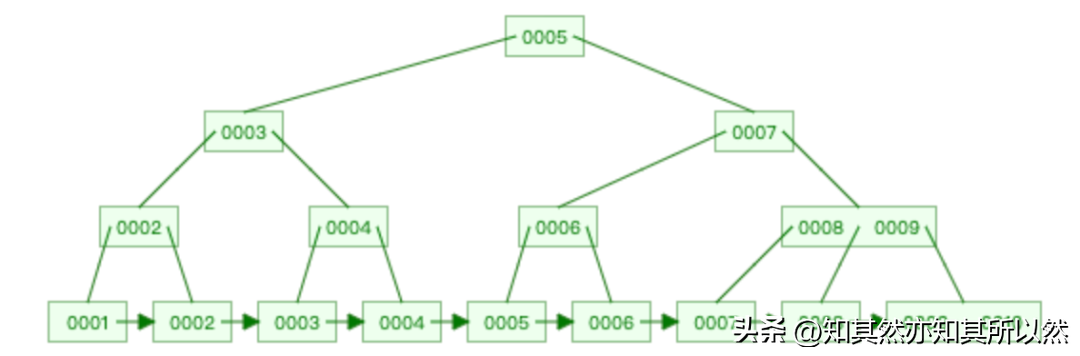
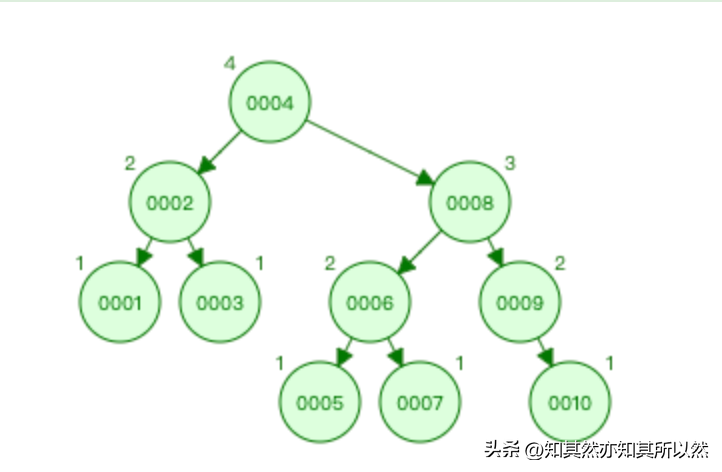
- 二叉树:二叉树是一种常见的数据结构,但在数据库索引中使用较少。它的特点是每个节点最多有两个子节点,通过比较节点值决定向左子树还是右子树进行搜索。由于二叉树的查询性能相对较低,因此在实际应用中较少使用。
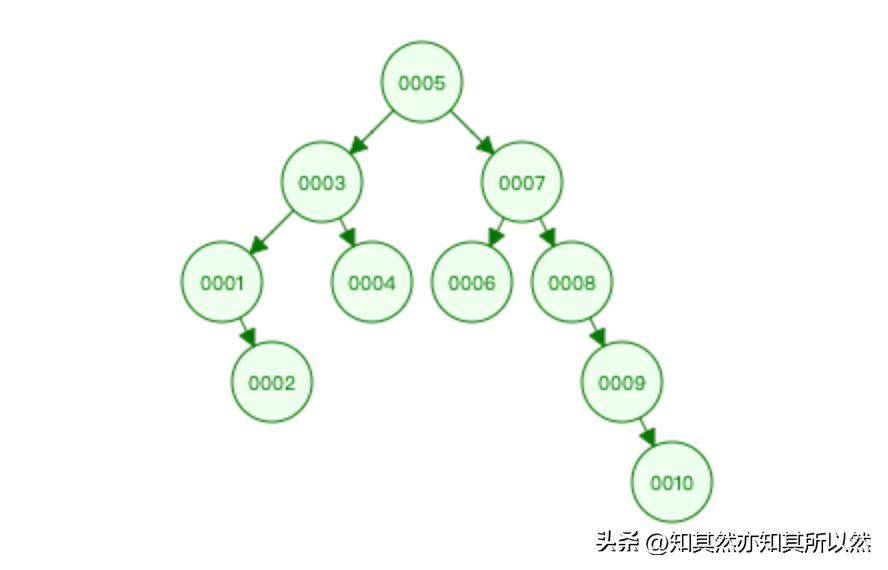
- AVL树:AVL树是一种自平衡的二叉搜索树,它的特点是任意节点的左子树和右子树的高度差不超过1。通过保持树的平衡性,AVL树可以在插入和删除节点时进行自动平衡,从而保证较好的查询性能。
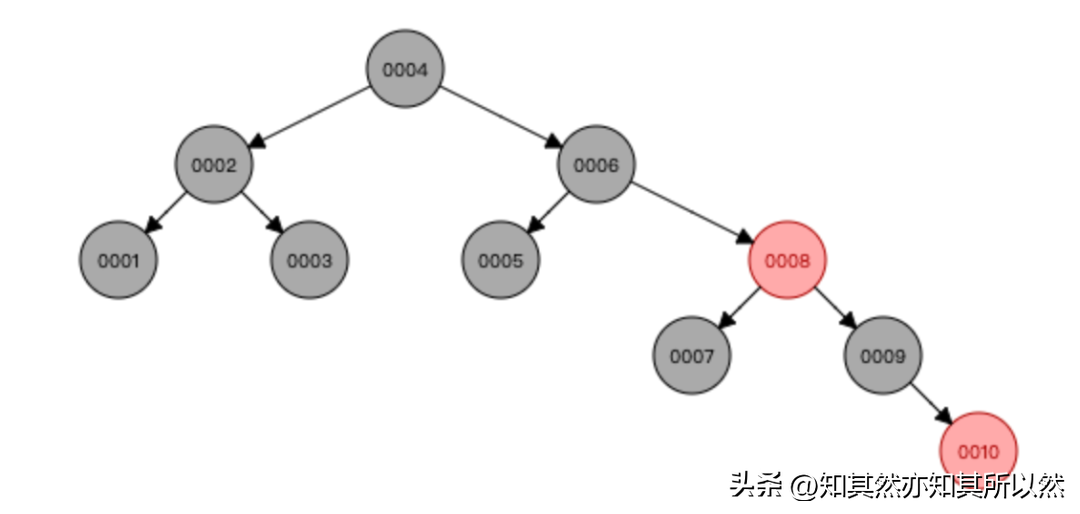
- 红黑树:红黑树是一种自平衡的二叉搜索树,它通过在普通的二叉搜索树上增加额外的红黑节点规则来保持平衡。红黑树具有较好的平衡性能,因此在某些数据库索引中会使用。
- B树:B树是一种多路搜索树,与B+树类似,但B树的非叶子节点也存储数据。B树通过调整节点的大小和子节点个数,使得每个节点可以存储更多的数据。B树常用于文件系统等需要频繁进行磁盘IO操作的场景。
叶子节点存储的内容
对于B+树而言,叶子节点存储的是具体的索引数据。也就是说,叶子节点包含了索引的键值和对应的指针或数据地址。当我们进行查询操作时,数据库会从根节点开始,根据键值在B+树中进行搜索,直到找到叶子节点,然后根据指针或数据地址获取具体的数据。
索引失效的情况
最后,我们来看一下索引失效的情况。索引失效通常指的是数据库查询时无法使用索引进行高效的数据定位,从而导致性能下降。以下是一些常见的索引失效情况:
- 条件不符合索引的使用:如果查询条件不符合索引的定义,数据库无法使用索引进行定位,会导致索引失效。例如,如果我们在一个整型字段上建立了索引,但查询条件中使用了字符串比较,索引就无法发挥作用。
- 使用了函数或运算符:在查询条件中使用函数或运算符可能导致索引失效。因为数据库无法在索引树中执行这些函数或运算符操作,所以无法使用索引进行定位。
- 数据分布不均匀:如果数据分布不均匀,即某些值的重复率非常高,索引的选择性就会降低,导致索引失效。在这种情况下,数据库可能选择全表扫描而不是使用索引。
- 索引列参与计算:如果索引列参与了计算操作,比如进行加减乘除运算,索引也会失效。因为数据库无法直接在索引树中进行这些计算操作。
总结
通过本文的介绍,我们了解了数据库索引的原理和底层数据结构。我们知道了IO操作对于索引的重要性,以及如何通过分块读取和局部性原理来优化IO性能。同时,我们也了解了B+树、二叉树、AVL树、红黑树和B树等常见的底层索引数据结构。另外,我们还了解了叶子节点存储的内容以及索引失效的情况。希望通过这篇文章的分享,能够帮助大家更好地理解数据库索引的原理与底层数据结构。