Aurora简述
Amazon Aurora 是亚马逊自研的云原生数据库,除兼容性、性能、扩展性外,它在设计之初,就以极致的可用性作为目标,尽可能减少故障对应用程序的影响。
Amazon Aurora 在故障恢复方面的设计理念主要包括:
- 1. 能在较大范围故障时仍然提供服务:跨3个可用区的6备份存储使它在一个可用区和另一个额外备份发生故障时仍能提供服务;跨区域的全球数据库能在主区域发生故障时快速切换到从区域;
- 2. 加快故障恢复的速度:将数据拆分成10 GB 粒度存储单元使单个存储单元能在秒级别恢复;通过分布式存储进行并行恢复等;快速找到健康计算节点先进行节点替换来使整个集群尽快提供服务。

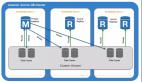
Amazon Aurora 的架构示意图如上所示,仅有Primary RW(Read/Write) DB一个主节点用于处理写请求,而其余的则为从节点Secondary RO(Read-Only) DB用于处理读请求,在其论文中指出Secondary RO DB可以多达15个。( Aurora论文翻译版本 )
Aurora有多主架构吗?如果是多主架构会怎样?
它们以端点 cluster endpoint 的形式对外提供服务,用户可以通过读写端点来访问 Aurora 写节点;通过只读端点访问 Aurora 读节点。
这里的只读端点只有一个,我们在应用程序中的配置也只有一个,但并不表示我们只有一个只读实例。
只读端点下面可以挂载多个实例,通过 Route53(高度可用和可扩展的云托管域名系统 (DNS) 服务) 进行负载轮训到不同的只读节点实例。
Failover介绍
在 Amazon Aurora 中,Failover 是指在主节点不可用时,自动或手动的将一个从节点提升为新的主节点的过程。
Failover 通常发生在以下情况:
主节点故障:如果主节点发生故障或停止服务,Amazon Aurora 将自动将一个从节点提升为新的主节点,以确保数据库的高可用性和容错性。
可用区故障:如果主节点所在的可用区发生故障,Amazon Aurora 将自动将一个在其他可用区中的从节点提升为新的主节点。
手动干预:如果需要执行主节点的计划维护或升级操作,可以手动将一个从节点提升为新的主节点,以确保数据库的可用性和稳定性。
当写节点发生故障时,Aurora 会进行如下的 Failover 过程:
1. 根据不同节点 failover 优先级和复制延迟来选择一个读节点,将其提升成新的写节点。因为该节点角色发生切换,需要重启该节点。
2. 尝试恢复原来的写节点并让它成为新的读节点。这里也会涉及到节点重启。
3. 待新的写节点重启成功以后,定位读写端点指向新的写节点。这里涉及到域名的更新,依赖于 Route53 的实现。
4. 待新的读节点重启成功以后,定位只读端点指向新的读节点。这里同样涉及到域名更新,依赖于 Route53 的实现。
AWS在控制台提供了手动触发failover的操作,我们可以通过观测 Event 事件来查看 failover 过程中 Aurora 的读写节点究竟发生了哪些操作。
以一写一读的集群为例,在控制台点击 failover,可以观测并整理出如下事件。

并绘制出事件时间图

整个集群 failover 过程在29秒完成,其中,新的写节点重启成功用了7秒,新的写节点在7秒以后就可以接受请求。
由于用户访问 Aurora 是利用域名的方式(Aurora 的读写域名和只读域名),新写节点启动后需要更新域名,而域名更新需要一定的时间,所以应用程序在数据库实例可用到 DNS 更新完成这个时间段内通过域名的方式连接 Aurora 集群时会发生连接错乱的现象。
在DNS发生切换前,使用写域名会连接到新读库上、使用读域名会连接到新写库上。而这种情况会对应用程序产生较大影响~~~
Failover对应用程序的影响
我们分别使用Maria和AWS驱动做了测试。
这里我们使用当前自身中间件版本的 ORM (基于 Mybatis 的封装)和 Maria驱动,分析每个阶段对程序的读写影响。

阶段一
这个阶段还未开始触发failover,读写一切正常。
阶段二
这个阶段读库开始并正在重启中,写库正常,对于写库的操作一切正常。
读库连接池状态: RO - Pool Status: Active: 0, Idle: 0, Total: 0, Waiting: 1
写库连接池状态: WR - Pool Status: Active: 1, Idle: 1, Total: 2, Waiting: 0
DEBUG级别日志:Connection refused (Connection refused)- 补充读库连接
对于读库的操作则会发生慢接口(queryTime > 业务sql执行时间 + 阶段二 + 阶段三)。但这并不会意味着一定会产生ERROR异常,具体要看连接参数connection-timeout设置和restart的过程时长。
connection-timeout > restart
会有长查询,但不会有ERROR级别异常。因为会在restart成功后正常建立TCP连接。
在这个过程中,Hikari连接池会做很多事情。
首先,这个阶段连接池内的连接都是一个time_wait状态的,获取连接时,这个连接如果空闲超出500ms,会在连接存活检测失效,如果空闲在500ms内,会在执行请求时立即得到连接关闭的状态。
不管哪种此时连接池都会把它关闭并从维护的池中清理,直到把维护的连接都尝试并清理个遍,然后尝试创建新的连接进行补充。
如果此时我们开启DEBUG日志的话会看到大量Connection refused (Connection refused)debug级别日志,只要restart时间在connection-timeout的范围内,也就无所谓了,大不了就查询时间长一些。
connection-timeout < restart
这时是会真的报ERROR级别的错误了
Cause: java.sql.SQLTransientConnectionException: single:RO - Connection is not available, request timed out after 30005ms.
阶段三
主从数据库全部不可用
写库也会进入读库的上个阶段
阶段四
读库连接池逐渐补充、读请求正常
[single:RO connection adder] DEBUG com.zaxxer.hikari.pool.HikariPool - single:RO - Added connection org.mariadb.jdbc.MariaDbConnection@515740ab
读库连接池状态: RO - Pool Status: Active: 1, Idle: 1, Total: 2, Waiting: 0
注意: 此时DNS并未发生切换,补充进来的读库连接实际上是连接到老的读库上(新的写库)。
阶段五
写库连接池逐渐补充、写请求发生 --read-only异常!!!
[single:WR connection adder] DEBUG com.zaxxer.hikari.pool.HikariPool - single:WR - Added connection org.mariadb.jdbc.MariaDbConnection@2ca547c0
写库连接池状态: WR - Pool Status: Active: 1, Idle: 1, Total: 1, Waiting: 0
注意: 此时DNS并未发生切换,补充进来的写库连接实际上是连接到老的写库上(新的读库)。
阶段六
连接池状态
RO - Pool Status: Active: 0, Idle: 2, Total: 2, Waiting: 0
WR - Pool Status: Active: 1, Idle: 2, Total: 3, Waiting: 0
应用异常日志
阶段七
- 1. 读请求正常
- 2. 写请求持续 read-only,直到连接生命周期结束(默认30分钟)
。。。
很显然、30分钟的写业务不可用是不可接受的……
如何应对数据库的Failover
通常情况下,Aurora 的 failover 通常能在30~60秒左右内完成,对应用程序产生较低影响。
那么,是否有可能进一步加快 Aurora failover 的速度呢?实现部分会重点介绍如何在 Aurora 进行故障恢复的时候避免或者减少 DNS 的影响,从而加快故障切换速度。
控制客户端 DNS TTL 的时间
检查客户端是否缓存了DNS及设置时间,如果设置较久的话,可以考虑将客户端的 DNS 的 TTL 调小,但这并不能消除DNS切换带来的影响。
数据库实例的底层 IP 地址在故障转移完成后可能会发生变化,也就是说如果我在故障转移过程中建立连接还是会有出错的可能性。
使用 RDS Proxy
RDS Proxy 是基于 Aurora/RDS 之上提供的一个代理层,它有三个特性:
1. 连接池能够实现连接的多路复用,如果应用对数据库的并发请求比较多,直接打到 Aurora 数据库上会耗费很多资源。可以使用 RDS Proxy 来实现连接复用,支持更多的并发应用,并减少新建连接的需要。
2. 增强的安全性,如果不希望直接把底层数据库的密码直接暴露,可以使用 RDS Proxy,通过使 RDS Proxy 访问 Secrets Manager 里的密码来增强安全性。
3. 快速的故障恢复时间,RDS Proxy 避开了 Aurora 发生故障切换时节点切换带来的域名 DNS 记录更新的问题,用户通过连接 RDS Proxy 可以避免域名更新的时间消耗。
AWS 的另一个产品,据说会有SQL上的性能损耗,未使用、未调研、未测试。
AWS智能驱动
智能驱动在连接到 Aurora 集群时,会拿到整个集群的拓扑和各个节点的角色信息(是写节点还是读节点)维持在缓存中。
有了这个拓扑,在节点发生变化时,就可以快速拿到变化的节点的角色信息,而无需再依赖的 DNS 的解析。

AWS 官方图
上图是AWS智能驱动自身的逻辑示意,应用程序连接到它时,会维护一个逻辑的连接和物理的连接。
比如现在的写节点是 C,但同时它的拓扑缓存中会存放着节点 A 和 B 的信息,这样如果节点 C 发生了故障,能够及时检测并将物理连接切换到 A 或 B 节点(取决于 Aurora 决定 failover 到哪个节点)而逻辑连接是保持不变的。
智能驱动与 MySQL 的普通驱动使用方法是一样的,您只需要更换驱动,并将连接字符串更换为如下格式即可。
注意这里的 url 的字符串前面是 jdbc:mysql:aws。缺省情况下,故障切换的能力是开启的,也可以通过参数调整的方式进行关闭。
jdbc:mysql:aws://集群名称.集群id.us-east-2.rds.amazonaws.com:3306/数据库名?useSSL=false&characterEncoding=utf-8
在对AWS智能驱动实验中,failover这块表现甚好,查看其failover代码实现,发现其为每个连接绑定了一套插件执行链,其中就有failover插件。

AWS 官方图
插件链的执行必然会对SQL带来点性能上的损失,为了能够正常failover,这点损失也能接受。
查看其版本变化和ISSUE、嗯…… 很活跃。
中间件的处理方式
AWS是自己实现了JDBC的Connection,为每一个连接绑定了插件机制,在每个业务SQL执行时检测拓普变化,决定是否替换掉真实的物理连接,参考上上图。
而我们使用Maria驱动每个创建的都是真实物理连接,如果要在物理连接上再抽象逻辑连接的话,工作量和实现都还是挺复杂的。
第一版:等待DNS切换的实现方案

在应用程序中开启一个线程每隔20s去拓普表中检查当前集群的写节点是否发生变化,因为DNS切换的时间大概就是20s左右。

当检测到集群拓普发生变化时,获取集群主节点端点HOST和当前集群写端点域名进行探测,当两个端点指向相同IP时,认为DNS切换完成,发出重建数据源事件,进行数据源重建。(写节点DNS切换基本维持在20s左右)
我们看下failover过程中DNS探测解析的日志(此过程和上图不是在同一个failover中搜集的,时间会有偏差)
failover 过程中域名DNS解析总结
1. 【写域名】转移到【老读库】 -- 16:37:35
2. 此时间段读写域名都解析到【老读库】(后续晋升为新写库) -- ----
3. 【读域名】转移到【老写库】(后续降级为新读库) -- 16:38:13
此方案的问题:
- 1. DNS完成切换前会有写业务的 read-only报错,持续在阶段五,时间10~20s,主要看老读库重启时长。
- 2. 从上面DNS探测的结果可以看出,会有持续较长一个阶段读写域名解析到同一个实例上(老读库=新写库)。当探测到写库域名切换时发起数据源重建,此时创建的读连接会连接到新写库上。尽管不会对业务产生影响,但是读写分离的功能会持续30min失效。

如果是由于瞬时流量造成的写库故障发生failover,这样切换到新写库上的话,除了正常的写流量还会有所有的读流量涌入,这样将更快的把写库打垮,然后继续failover……
那再把读库域名的切换加入到探测过程中呢?等待读写域名指向全部稳定后再发起数据源重建事件怎样?
首先,read-only的报错时长会拉长,因为要同时等待读写域名的切换完成。
其次,如果我们只读端点挂载多个读实例的话,读库域名会在 Rout53 下每 5~30s 进行轮训,固定不下来不好作为 DNS 切换完成的依据。
可以对只读端点域名进行多次探测,当发现轮训结束后的IP数量等同于读库数量时认为读库DNS切换完成。这个时间就太长了,并且还不确定是不是采用的轮询算法。
此时,又想起了AWS智能驱动…… 不幸的是它也没有解决上述问题(上图AWS-1.1.5版本测试结果)
第二版:依赖拓普结构创建连接
上面看AWS故障转移模块代码的时候发现,当发生故障转移时,逻辑连接不变,物理连接会通过拓普中的实例端点进行连接替换。
要在Maria的连接中按照此方案实现的话,工作量太大、实现太复杂。
我们使用的是HikariCP连接池管理的链接生命周期,那如果我们在连接池创建连接时让它按照我们给定的拓普去连接呢?
这样的话,我们不仅解除了对DNS的解析依赖、还可以按照指定算法对读库进行连接负载,同时还可以把故障影响范围控制在数据库实例重启的时间范围内了!!!
在连接池创建连接前,我们通过外部配置给定的集群读/写端点获取当前集群拓普结构,在连接池创建连接的时候,写库连接我们分配主端点、从库连接我们按照自己的分配算法(轮询),将分配后的实例端点给到连接池,让它按照我们给定的实例端点进行连接的创建。

其中SwitchHostDatasource需要自己实现并给到Hikari,让连接池使用我们提供的Datasource进行连接的创建和维护。
经验证,在 Failover 过程中, 仅影响当前活跃连接在数据库重启过程中对应的读/写业务,彻底消除 Failover 过程 DNS 带来的read-only异常、也避免了 failover 后的连接倾斜现象,最小化的处理数据库 failover 对应用程序造成的影响。
巨人的肩膀:
https://aws.amazon.com/cn/blogs/china/be-vigilant-in-times-of-peace-amazon-aurora-fault-recovery-reduces-the-impact-of-dns-switching-on-applications/