ChatGPT回答问题时,是一个字一个字弹出的,给人一种在认真思考的感觉。
这段对话的基本内容是:
问:大语言生成式模型是如何工作的
答:大型语言生成模型(如GPT-3)是基于深度学习技术的神经网络模型。这些模型通常使用一种称为"Transformer"的架构,该架构在自然语言处理领域取得了巨大的成功。下面是大型语言生成模型的工作原理概述:
... 省略一段 ...
生成文本:一旦模型经过训练,就可以使用它来生成文本。给定一个初始文本或提示,模型会根据已经学到的概率分布生成下一个单词,然后使用生成的单词作为输入,并继续生成下一个单词,以此类推,直到达到所需的文本长度或生成终止符号。
... 省略一段 ...
大语言模型,Large Language Model,简称LLM。
从模型的视角来看,LLM每进行一次推理生成一个token,直到达到文本长度限制或生成终止符。
从服务端的视角来看,生成的token需要通过HTTPS协议逐个返回到浏览器端。
Client-Server 模式下,常规的交互方式是client端发送一次请求,接收一次响应。显然,这无法满足ChatGPT回复问题的场景。
其次,我们可能想到websocket,它依赖HTTP实现握手,升级成WebSocket。不过WebSocket需要client和server都持续占用一个socket,server侧成本比较高。
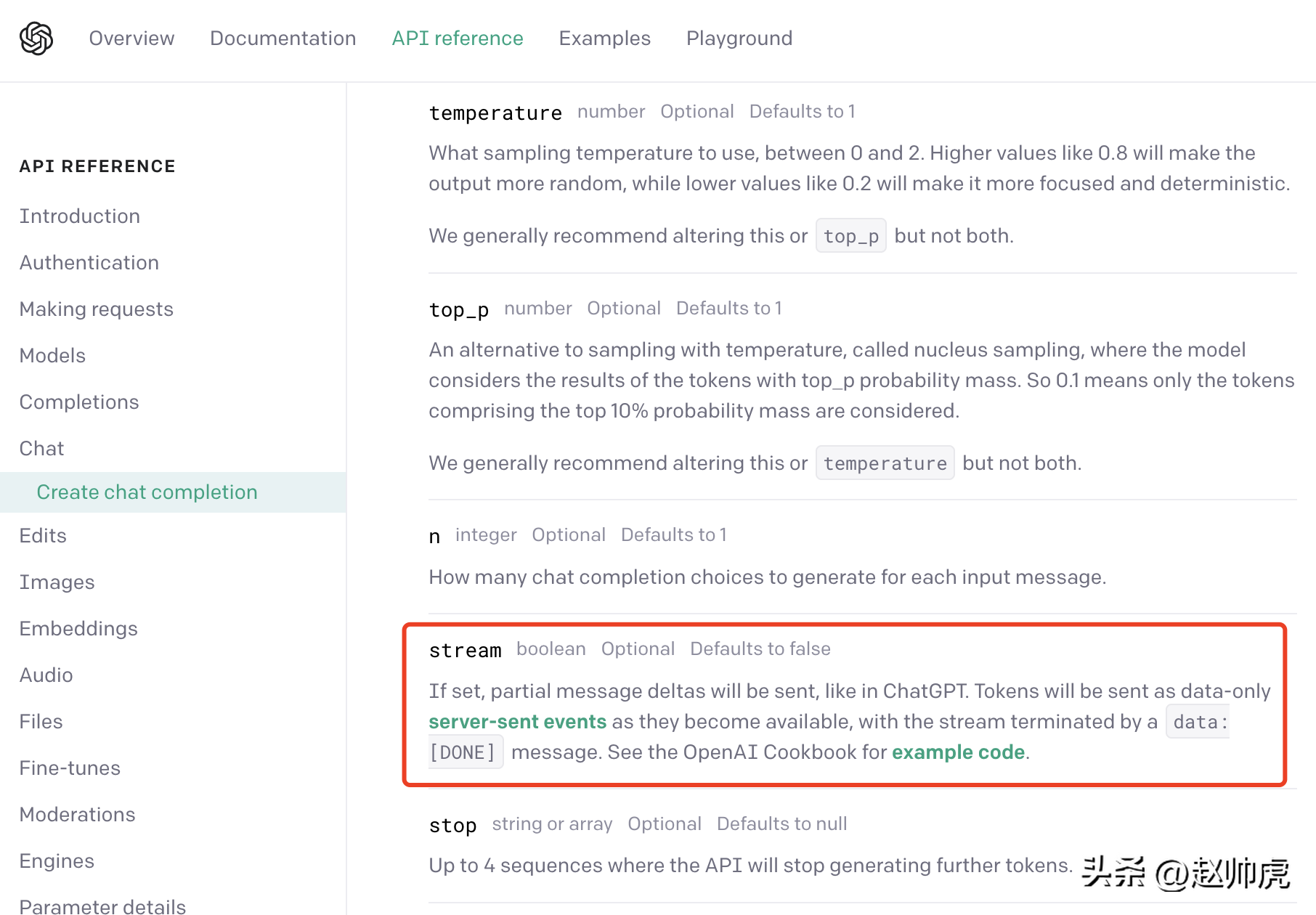
ChatGPT使用的是一种折衷方案: server-sent event(简称SSE). 我们从OpenAI的 API 文档可以发现这一点:
SSE 模式下,client只需要向server发送一次请求,server就能持续输出,直到需要结束。整个交互过程如下图所示:
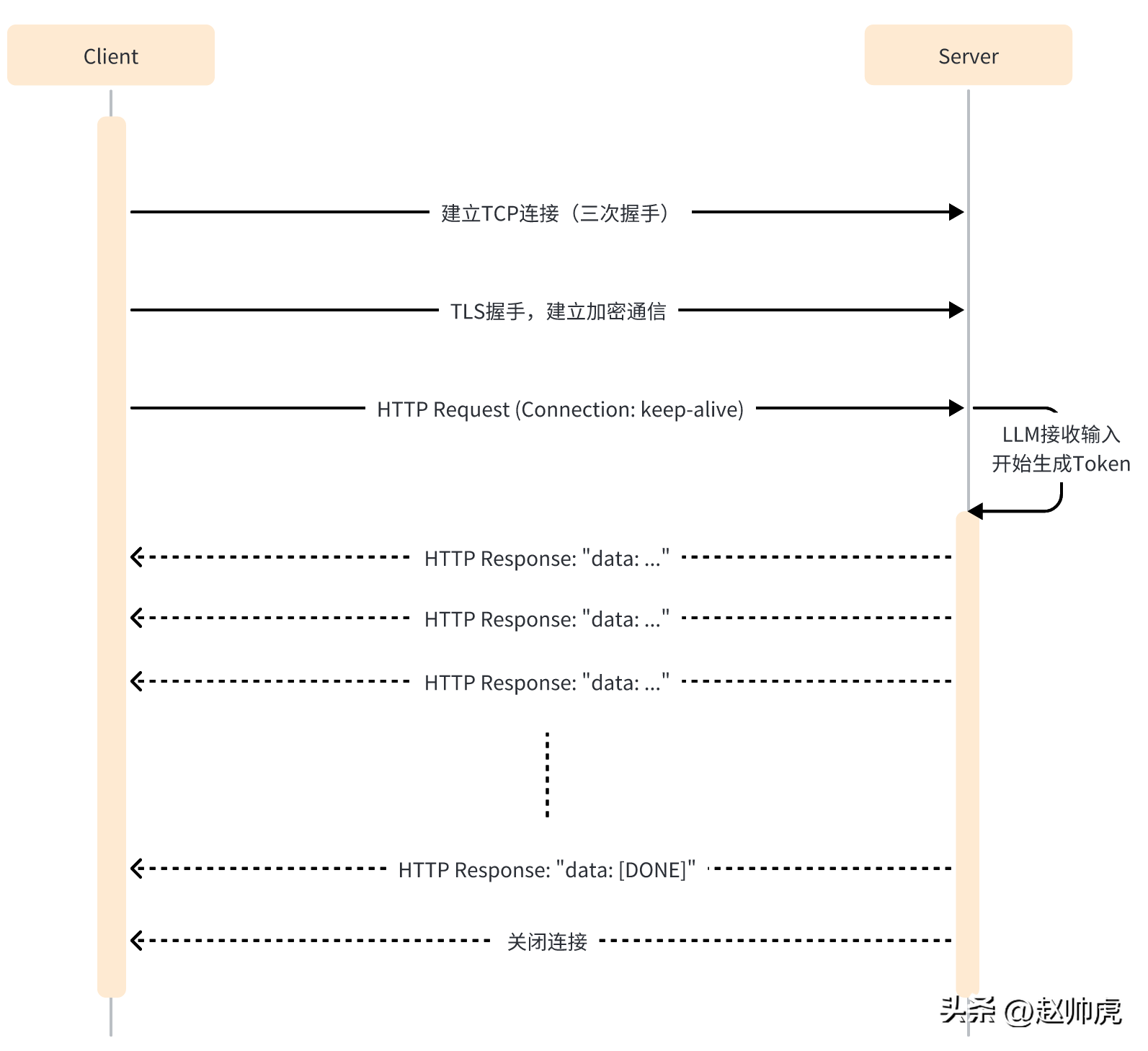
SSE仍然使用HTTP作为应用层传输协议,充分利用HTTP的长连接能力,实现服务端推送能力。
从代码层面来看,SSE模式与单次HTTP请求不同的点有:
- client端需要开启 keep-alive,保证连接不会超时。
- HTTP响应的Header包含 Content-Type=text/event-stream,Cache-Cnotallow=no-cache 等。
- HTTP响应的body一般是 "data: ..." 这样的结构。
- HTTP响应里可能有一些空数据,以避免连接超时。
以 ChatGPT API 为例,在发送请求时,将stream参数设置为true就启用了SSE特性,但在读取数据的SDK里需要稍加注意。
在常规模式下,拿到 http.Response 后,用 ioutil.ReadAll 将数据读出来即可,代码如下:
执行大概耗费20s+,得到一个完整的结果:
如果我们将 stream 设置为 true,不做任何修改,请求总消耗28s+,体现为很多条 stream 消息:
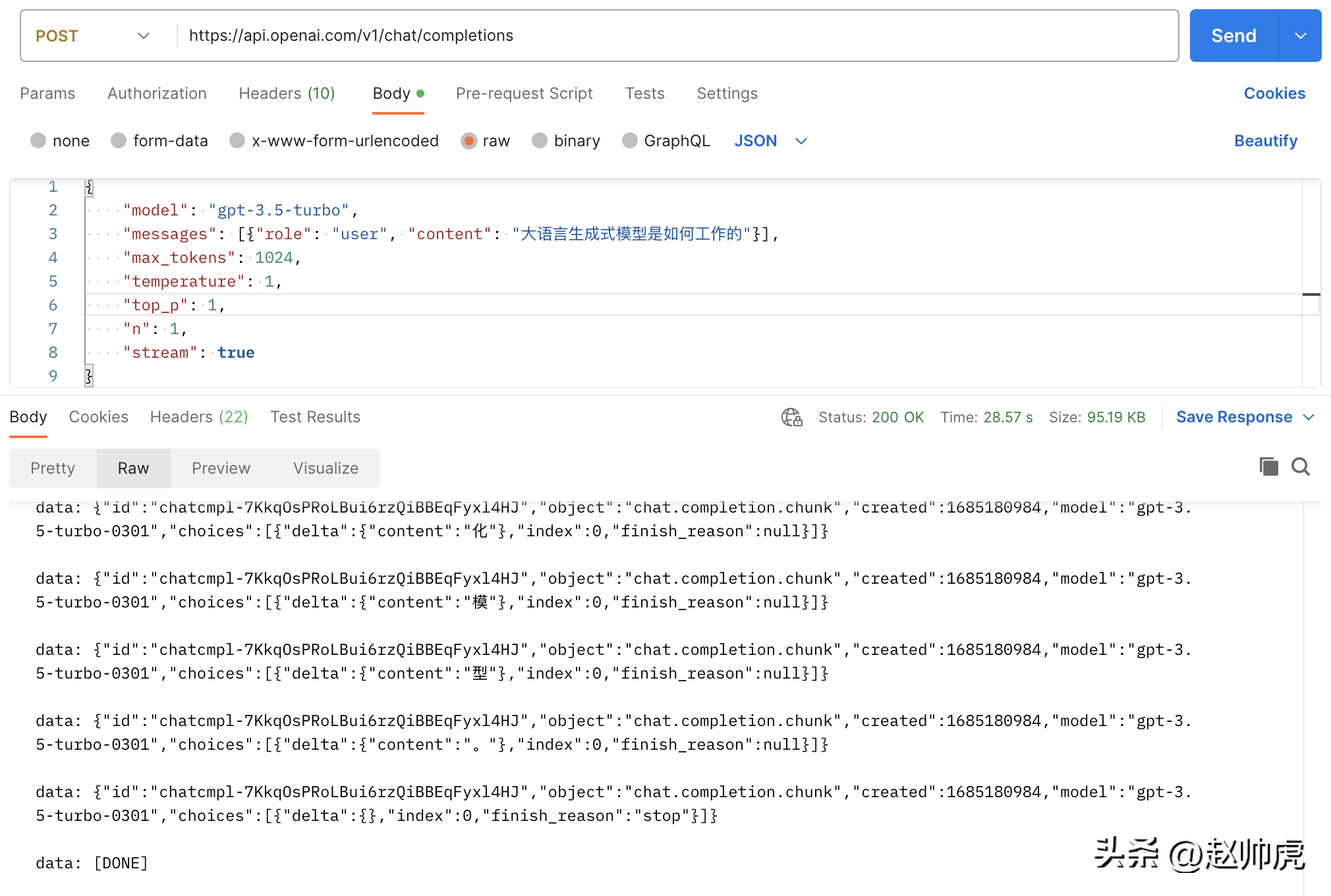
上面这张图是一张Postman调用 chatgpt api的图,走的就是 ioutil.ReadAll 的模式。为了实现stream读取,我们可以分段读取 http.Response.Body。下面是这种方式可行的原因:
- http.Response.Body 的类型是 io.ReaderCloser,底层依赖一个HTTP连接,支持stream读。
- SSE 返回的数据通过换行符\n进行分割
所以修正的方法是通过bufio.NewReader(resp.Body)包装起来,并在一个for-loop里读取, 代码如下:
看完client端,我们再看server端。现在我们尝试mock chatgpt server逐字返回一段文字。这里涉及到两个点:
- Response Header 需要设置 Connection 为 keep-alive 和 Content-Type 为 text/event-stream。
- 写入 respnose 以后,需要flush到client端。
代码如下:
在真实场景中,要返回的数据来源于另一个服务或函数调用,如果这个服务或函数调用返回时间不稳定,可能导致client端长时间收不到消息,所以一般的处理方式是:
- 对第三方的调用放到一个 goroutine 中。
- 通过 time.Tick 创建一个定时器,向client端发送空消息。
- 创建一个timeout channel,避免响应时间太久。
为了能够从不同的channel读取数据,select 是一个不错的关键字,比如这段演示代码:
小结一下
大语言模型生成响应整个结果的过程是比较漫长的,但逐token生成的响应比较快,ChatGPT将这一特性与SSE技术充分结合,一个字一个字地弹出回复,在用户体验上实现了质的提升。
纵观生成式模型,不管是LLAMA/小羊驼 (不能商用),还是Stable Diffusion/Midjourney。在提供线上服务时,均可利用SSE技术节省提升用户体验,节省服务器资源。