译者 | 朱先忠
审校 | 重楼
图像分割是机器学习中的一个热门话题,如今已经得到广泛应用。在视觉模型领域,可以根据一些标准进行训练来实现分割图像,这通常是按照熟悉类型的对象的轮廓来进行的。当模型不仅可以分割图像,而且可以区分不同类型的对象时,这被称为语义分割(semantic segmentation)。自动驾驶汽车应用领域就是使用语义分割来识别附近的物体:行人、停车标志、道路、其他汽车等。语义分割的另一个应用是在医学(放射学)领域,可以训练模型来识别超声波图像中的恶性肿瘤。当然,类似的应用场景远远不止这些。
本文假设您熟悉图像分割的基本概念,以及模拟退火等优化算法。为了确保文章不至于太冗长,文章中没有引用任何代码;但是,请自行参阅我在本系列文章示例工程的GitHub存储库中的源码,该存储库也在文章最后一节中提供了链接,以了解项目的所有代码。我还在整个文本描述的相关位置放置了相应的代码链接。此外,我还提供了有关的主要笔记,其中包含用于为本文生成图像的代码。
项目目标
先介绍一下背景:
2022年12月,我在威斯康星大学拉克罗斯分校完成了数据科学硕士研究的最后一个学期。在UWLAX的Jeff Baggett博士的监督下,我的毕业项目是建立语义分割模型,此模型可以检测乳腺超声图像中的组织损伤。其中一些病变是恶性的,重要的是要借助良好的诊断工具来尽早发现这种疾病。在大型通用数据集(如ImageNet)上预先训练的分割模型可以在医学超声成像数据上进行微调。通过将超声扫描仪的图像输入到这样的模型中,我们能够从模型中得到预测,从而指示病变是否存在于扫描区域中,病变位于何处,病变的形状是什么,以及可供选择的关于疾病的性质(恶性或良性)提示等信息。
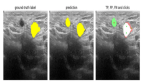
以下是一个图像分割模型的示例,该模型对从乳腺超声图像数据集获取的超声图像执行预测:

对超声图像的预测(图像来源:乳腺超声图像数据集)
其中,左边的矩形中内容是来自数据集的超声图像;它包含看起来可能是恶性的或可能不是恶性的病变(暗区)。中间矩形展示的是正确标注的标签,也是数据集的一部分;人类专家已经绘制了感兴趣区域(病变)周围的轮廓;这些标签用于训练模型,并在训练后测量其性能。右边矩形中内容是我的模型的预测结果;在图示的这种情况下,它接近于正确标注的标签。在这种情况下,模型并不是用来区分恶性和良性病变的,它们都以黄色显示。
在上述我的毕业项目的基础上,本文中项目也是华盛顿大学洛杉矶分校CADBUSI项目的一部分,就像我的毕业项目一样)将从以下几个关键点展开讨论:
- 医学成像与其他分割应用程序有些不同,因为查看模型输出的用户(放射科医生)在该领域具有重要的专业知识。用户并不像大多数其他应用程序那样完全被动。问题不在于该模型在识别病变方面是否优于人工操作员,而在于如何将模型的功能和用户所知相结合,以获得更好的整体结果。
- 用户可能在各个方面都同意模型的预测结果,或者模型和用户之间可能存在分歧。此外,用户可能拥有模型所没有的关于患者的知识。如果用户能够向模型提供提示或反馈,就模型而言,提供额外的输入数据,以达到结合模型和用户的优势的更高质量的预测,这将是非常有用的。
- 此外,用户应该能够以简单的方式向模型提供反馈,例如用鼠标点击图像以突出显示重要区域。用户生成的鼠标点击的坐标成为模型的额外输入,然后模型应该相应地调整其预测。
如果你从头开始构建模型,你可以用任何你想要的方式设计输入,包括各种类型的数据。但在这种情况下,您需要进行完整的预训练周期(例如使用ImageNet),这需要大量的计算和时间资源。如果你使用现成的模型,在ImageNet上预先训练,这会节省大量的时间和精力,但在模型的输入中似乎没有用户反馈的空间——这些模型的设计目的是将图像作为输入,而不是其他形式的数据。
当然,除非你能在现成模型的输入中识别出冗余。这意味着,除了通常的成像数据之外,输入中还存在冗余通道,可以重新用于向模型提供用户反馈。本系列文章将介绍这是如何实现的:
- 识别现有图像分割模型中的输入冗余
- 使用冗余输入通道提供用户反馈
- 训练模型正确识别用户反馈
- 尽可能使整个过程自动化
当模型出错时
让我们考虑一下这个案例:

假阴性(图像来源:乳腺超声图像数据集)
注意到,图像左侧似乎有一个感兴趣的区域(RoI)——一个小的、深色的椭圆形。这在标签中显示为黄色区域。但模型的预测是空集——预测帧中没有黄色像素。模型似乎不相信这张照片中有RoI。我们,在这里扮演人类专家的角色,显然是不同意此结果的。
或者在这种情况下:

假阳性(图像来源:乳腺超声图像数据集)
人类专家(标签的作者)认为图像中只有一个真实的RoI。然而,该模型却确定了两个独立的RoI。
在上面这样的情况下,预测结果是非常边缘性的,并且人类专家可能有理由不同意模型的预测结果。此时,允许用户的反馈基于用户拥有但模型没有的信息或知识来指导模型的预测将是有用的。
理想情况下,用户应该能够通过一种非常简单的方法提供反馈,例如点击图像中的各个区域——然后模型应该考虑点击坐标提供的信息,以调整其预测结果。此时,单击坐标将成为模型输入的一部分。这可以通过多种不同的方式来实现。
Liu等人的PseudoClick论文(2022)描述了一种模型架构,其中点击是通过单独的输入层提供给模型:模型有一个实际图像的输入,和一个不同的点击输入。当然,如果你从头开始构建你的模型,你可以随心所欲地设计它,也可以从PseudoClick架构中获得某种建议。
但是,如果您使用现成的模型,则必须使用现有的输入。这将在下一节中进行描述。
使用颜色通道提供反馈信息
如果你使用现成的视觉模型,它很可能是为处理彩色图像而构建的——模型的输入实际上是三个相同的层,每个颜色通道一个:红色、绿色和蓝色。如果输入是黑白的,这是超声图像的情况,则相同的信息(纯亮度)以相同的方式分布在所有颜色通道上。换句话说,对于相同的信息,有三个独立的通道似乎是多余的。
如果单色图像只使用一个颜色通道,那么模型的工作原理是否相同呢?假设我们将两个颜色通道(R和G)归零,并且只在B通道中保留图像信息。
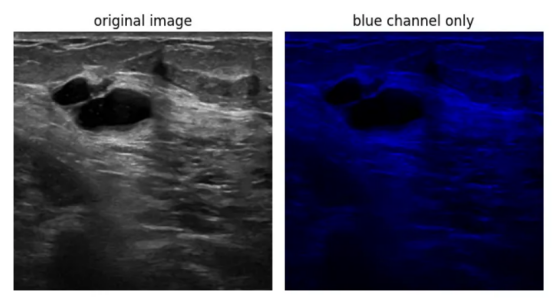
蓝色通道(图像来源:乳腺超声图像数据集)
用预训练的图像分割模型(例如SegFormer MiT-b3——可在HuggingFace存储库上获得,在ImageNet上预训练)测试这一想法。很明显,用通常的图像分割指标(IoU,Dice)测量的模型性能没有改变。该模型的工作原理基本相同。当对单色图像进行预测时,来自彩色通道的冗余既没有帮助,也没有害处。
这意味着,我们可以只在B通道中保留图像数据,并使用R和G通道进行额外的输入——用户生成的点击。不仅如此,我们还有两个独立的通道,R和G,它们可以为模型提供不同类型的输入。
这正是我们所需要的:一种点击应该是“激活”或“积极”,告诉模型“这是一个感兴趣的区域,关注这里”,而另一种应该是“抑制”或“消极”,告诉模型“这里什么都没发生,避开这个区域”。
问题是,在训练数据中放置点击以使模型对用户输入做出响应的最佳方式是什么?这将在下一节中进行描述。
真阳性、假阳性和假阴性
来自分割模型的预测是图像中像素以某种方式标记的区域,例如通过非零值标记。当预测区域与该图像的正确标注的标签非常匹配时,我们认为该模型表现良好。与标签匹配的预测像素被称为真阳性(TP)。
在模型进行非零预测但标签中的像素为零的情况下,这些像素为假阳性(FP)。如果标签中的像素为非零,但模型的预测为零,则这些是假阴性(FN)。下面是一个例子:
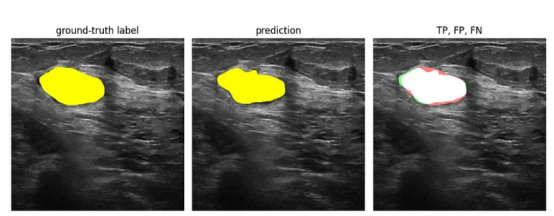
真阳性、假阳性、假阴性(图像来源:乳腺超声图像数据集)
其中,左边的矩形中显示的是标签。中间矩形中给出的是模型的预测结果。在右边的矩形中,我们用白色标记了真阳性(TP):预测像素与标签像素匹配。假阳性(FP)是标签中为零的非零预测像素,并标记为绿色。假阴性(FN)是标签中存在非零像素的零值预测像素,并且被标记为红色。
如果我们知道模型往往错误并做出错误预测的图像区域(FP,FN),我们可以在原始数据集中添加点击,标记FP和FN区域。由于我们已经将所有图像信息移动到蓝色通道,因此可以使用红色和绿色通道进行这些点击。
例如,我们可以在红色通道中单击来标记假阳性区域。我们希望,这些点击将成为“抑制性”或“负面”点击,从而使模型不再进行预测。假阴性区域可以用绿色通道中的点击标记,这将变成“激活”或“阳性”点击,并引导模型更多地关注这些区域。示例:
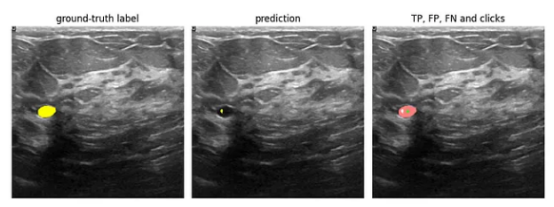
图像来源:乳腺超声图像数据集
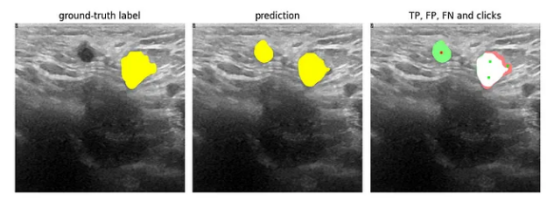
图像来源:乳腺超声图像数据集
在上面显示的图像中,我们在假阳性区域(模型预测不存在的RoI)中放置了红色通道点击(负点击),在假阴性区域(模型没有预测任何内容,但有实际的RoI的区域)中放置绿色通道点击(正点击)。为了更好的度量目的,我们在真阳性区域再点击几次绿色通道,以“锚定”预测并确保TP区域保持稳定。
使用点击的完整训练程序如下文所述。
通过点击训练模型
下面给出了训练模型对用户输入做出响应所涉及的主要步骤:
- 选定一个特定的现成图像分割模型,例如使用ImageNet预训练的SegFormer MiT-b3
- 处理所有单色图像,使图像数据仅存在于B通道中;R和G通道将变为空白
- 将图像数据集拆分为5组;对每组中的模型进行微调;这将创建5个模型,每个模型都针对数据集中的不同组进行了微调;让我们把这些称为基线模型
- 使用5个基线模型中的每一个对其在训练中没有看到的图像进行预测;这将为数据集中的所有图像生成预测
- 对于每个预测,确定TP、FP、FN区域;如上所述,用R和G点击覆盖FP、FN和可选的TP区域;小区域每个点击一次;大区域可多次点击;目前,假设单击坐标是手动生成的(稍后会详细介绍)
- 将点击嵌入到数据集中的R和G通道中,但保持B通道不变;每次点击都是R或G通道中的3x3像素区域,我们将像素值设置为该通道的最大值(例如,uint8dtype为255)
- 使用相同的5个组,在数据集上训练5个新模型,并将点击添加到R和G通道;让我们称之为点击训练模型
换句话说,我们训练基线模型来“预测”模型可能出错的地方,我们根据需要将点击量添加到“错误”区域,然后训练新模型(点击训练模型),将点击量增加到数据集中。我们希望经过点击训练的模型能够对通过R和G通道提供的点击做出反应。完整的代码显示在链接https://github.com/FlorinAndrei/segmentation_click_train/blob/main/train_models.ipynb处。
为了清晰起见,经过所有处理并且在添加点击后,结果图像将是下图所示的样子:
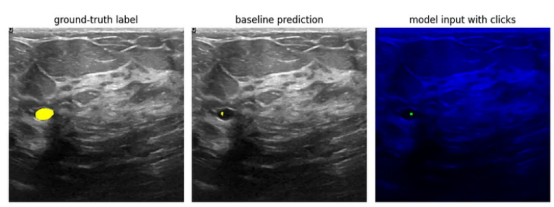
图像来源:乳腺超声图像数据集
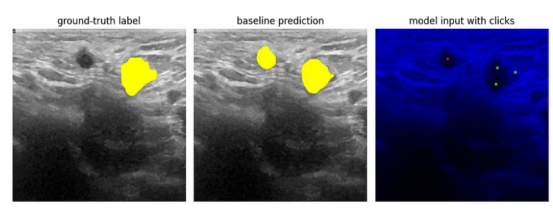
图像来源:乳腺超声图像数据集
其中,左边的矩形是我们试图匹配的正确标注的标签。中间矩形是来自基线模型的预测。右侧矩形中显示了用于训练点击训练模型的处理图像——所有图像数据都已移动到B通道,并根据需要将点击添加到R和G通道以修改预测。
您不需要实际修改数据集来添加R和G点击。您可以简单地注册点击坐标,并修改数据加载器,以便在训练模型时动态应用点击。如果出于任何原因需要重新生成单击坐标,则这样的修改就要灵活得多。
此外,您可以从图像增强技术中得到提示,并在训练中以一定的概率应用点击。点击并不总是被添加到输入中,只是在某些情况下是随机的。我使用了0.9的概率,结果很好。这个想法是为了不让模型过度依赖点击。另外,微调此参数可能需要进一步探索。
实验结果
上述方法有效吗?
确实有效。这是一个经过点击训练的模型,用于进行预测,然后实时响应用户反馈:
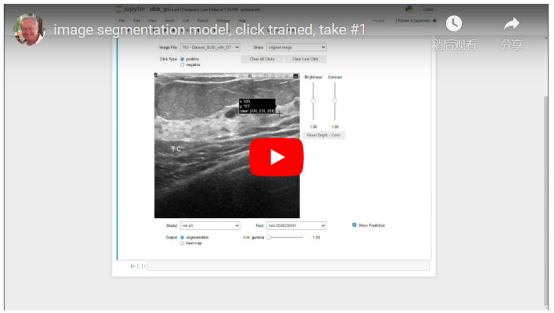
我们要求模型进行预测,它覆盖了图像上半部分的两个黑暗区域。我们不同意这个模型——我们认为左边的区域不是感兴趣的区域,所以我们在上面点击了一个抑制性的(红色)。我们还在右边的区域点击了一次激活性的(绿色)。现在,模型的预测遵循了我们所掌握的额外信息。
应该注意的是,一次点击,大小约为3x3像素,会影响模型在直径数百像素的区域中的预测。此外,该模型还考虑了点击的存在和图像中可见的特征:在感兴趣区域(RoI:region of interest)中放置点击会使模型用预测掩码填充整个区域,遵循图像中可见轮廓。
在某些情况下,模型很容易遵循用户反馈——这就是模型输出中的预测存在高模糊性/低置信度的情况。在其他情况下,模型的预测将不会因负面点击而被“逐出”RoI——这是在模型自身输出的模糊度较低/可信度较高的情况下。
规模化问题
到目前为止,所描述的技术的主要问题都是围绕着小规模数据进行。我们假设点击坐标是手动生成的。换句话说,操作员需要仔细筛选所有图像,将正确标注的标签与预测进行比较,决定点击位置和点击次数,并记录所有点击坐标。
这显然谈不上什么规模化的问题。为一个包含数百张图像的数据集生成一组点击已经是乏味和耗时的,不过并非不可能。如果数据集包含数千张或更多的图像,或者特别是当基线模型发生变化时,需要重新生成一组点击,那么这项任务就变得不可能了。因此,这需要借助某种自动化来实现。
不过,这将是本系列第2部分的主题。其中,我们将展示如何自动创建点击坐标,使训练过程可以在完全无监督的情况下运行。第2部分将描述一种生成点击的算法,该算法的生成方式与操作员做出的决策非常相似。
链接、引文、评论
本文中的这个项目是我在数据科学硕士研究的最后一个学期的毕业项目的延伸。
毕业项目和这项工作都是在威斯康星大学拉克罗斯分校的乳腺超声图像计算机辅助诊断(CADBUSI)项目中完成的,由Jeff Baggett博士监督。参考地址:https://datascienceuwl.github.io/CADBUSI/。
包含本文代码的GitHub存储库:https://github.com/FlorinAndrei/segmentation_click_train。
本文中使用的所有超声图像都是乳腺超声图像数据集的一部分,可在CC BY 4.0许可证下获得。引文链接有:
Al-Dhabyani, W., Gomaa, M., Khaled, H., & Fahmy, A. (2019)。《乳腺超声图像数据集》(Dataset of Breast Ultrasound Images)。ResearchGate。检索日期:2023年5月1日,论文:https://www.sciencedirect.com/science/article/pii/S2352340919312181。
其他链接、引用和评论:
- Liu, Q., Zheng, M., Planche, B., Karanam, S., Chen, T., Niethammer, M., & Wu, Z. (2022)。《伪点击:具有点击模仿的交互式图像分割》(PseudoClick: Interactive Image Segmentation with Click Imitation)。arXiv.org。检索日期:2023年5月1日,论文:https://arxiv.org/abs/2207.05282。
- Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J. M., & Luo. P. (2021)。《SegFormer:一种简单高效的变压器语义分割设计》(SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers)。arXiv.org。检索日期:2023年5月1日,论文:https://arxiv.org/abs/2105.15203。
最后,本文中不属于乳腺超声图像数据集的所有图像都是由作者自己创建的。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Train Image Segmentation Models to Accept User Feedback via Voronoi Tiling, Part 1,作者:Florin Andrei