一、有数 BI 图表的数据查询原理
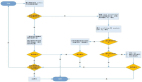
1、可视化的数据分析流程
可视化的数据分析流程,主要分成三部分:数据接入、数据建模和报告制作。

(1)数据接入
目前有数已经支持 30 多种数据源,且支持多种数据源类型,包含关系型数据库、分布式数据库、restAPI、数据表单等。
(2)数据建模
数据接入后,我们就可以进行数据建模。
目前我们支持通过拖拽式的 Join/Union 建模,如果用户有复杂需求,也可以通过自定义 SQL 方式建模。另外我们也具备计算字段的能力,可以进行一些计算字段的扩展。同时,我们也支持字段元信息定义,比如字段类型、指标口径等等。
(3)报告制作
数据模型建好了,就可以进行拖拽式的报告制作。
目前我们支持丰富的图表库以及强大的分析能力,让用户做报告就像制作 PPT 一样简单。同时,用户也可以把做好的报告通过移动端、微信小程序、分享链接等形式分享出去,进行数据的分发和共享。
2、图表背后的数据查询和处理技术

(1)Query DSL:图表数据查询语言
首先图表配置好以后会先生成 Query DSL(图表数据查询语言),它包含模型依赖的数据源连接信息、宽表信息以及用户拖上去的维度、度量、筛选、排序等等。
(2)所有操作都可以转换成 Query DSL
用户配置的图表最终都能转换成一套 Query DSL。
(3)抽象语法树的生成
有了 Query DSL,就可以生成对应的 AST(抽象语法树),它包含 Table 节点、Select 节点、From 节点、Group By 节点和一些计算节点等。
(4)SQL 语法适配:屏蔽数据源差异
有了抽象语法树,我们就可以针对不同的数据源进行 SQL 的适配,然后从不同的数据源将数据查询回来并返回给用户。这样,对于用户来说是不需要感知到底层数据源的类型的。
3、图表查询核心能力

首先,最基础的部分,支持排序、筛选、聚合、数据字典、计算字段和分组字段等等。
另外,支持图表联动、上卷下钻、地图计算等强大的分析能力。
同时,还支持行列权限(同一个图表不同用户看到不同数据)以及跨视图粒度分析(同一张图表可以看到不同聚合粒度的数据)的能力。
最后总结下,前面讲到的图表提供的一些能力,背后的核心其实都是对数据字段行为的处理,比如我们常用的聚焦下钻,当点击地区 = “东北”这个柱子下钻下去看下东北下面各个省份求和销售额的分布,其实背后的处理行为就是,我们会把 x 轴的维度字段从地区转换为省份,然后再加一个地区 = “东北”的字段筛选器,所以这里聚焦下钻其实背后被转换成了两个对字段行为的处理,最后这些字段都会转换成统一的语法树。

二、有数 BI 智能缓存的设计和实现
前面我们讲到,针对用户配置的图表会对应生成 SQL,然后去对应的落库查询。整个查询过程有以下几个特点:
① 高并发:早上看数高峰期。
② 大数据量:很多千万、亿级数据查询场景。
③ 离线数据:大部分都是 T + 1 的数据。
针对以上特点最有效的手段就是通过缓存去解决,可以看到下图是我们线上最近一个月的查询耗时对比(绿色线表示落库查询、红色线表示缓存查询),很明显命中缓存以后查询效率可以有上百倍的提升。

那么,图表缓存的是什么数据呢?
答案是图表数据。
这里可能很多同学会问,为什么不缓存模型数据?
首先,模型数据可能较大;其次,当缓存模型数据时,图表查询时依然需要进行二次聚合运算,因此也存在一定的计算成本。

可以看到我们缓存的对象由图表和用户组成,这里的主要原因是由于前面讲到的同一图表不同用户可以看到不同数据,因此一个图表会存在多份缓存。
除此之外,我们还引入了二级缓存的概念。
一级缓存,主要缓存前端图表通过 queryData 查询出来的数据。
二级缓存,主要缓存生成的 SQL 查询出来的数据,同时,二级缓存可以实现缓存复用,例如:同一套数据展示成折线图和柱状图,虽然他们的展示形式不同,但底层生成的 SQL 是一样的,此时就可以复用二级缓存。
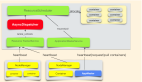
下图展示了智能缓存的整体架构。

第一层是调度器:包括缓存的刷新计划、OpenAPI、表产出订阅、MPP 抽取和手动触发。
第二层是运算器:包括数据产出驱动、图表血缘计算、用户查询行为分析和基于 ROI 的优先级计算。
第三层是执行器:通过运算器会生产一个缓存对象,缓存对象就会被放入队列进行排队执行,最终生成缓存的数据。
另外,我们我们还会实时地监控缓存数据,进行一些缓存的监控和报警。
接下来,我们看一下缓存运算器中的基于数据产出驱动缓存的原理。

因为大部分数据是 T+1 离线数据,因此这里也是以天为单位进行实现。它的输入是离线表的产出消息,当消息推送过来时,我们可以根据图表的血缘关系找到该表关联的图表,然后对图表进行缓存。
当然,有些表不是每天都有产出任务的,因此这里我们引入了产出预测模块。它可以根据数据任务的调度信息计算出某个表今天有没有产出,另外还可以根据表产出历史推测出今天该表有没有产出。
该方式的优点是可以提升缓存效率,进行错峰缓存,从而保障缓存的实时性和有效性。
它的应用场景有三点:
① 一是与有数数据中台的数据服务打通,天然就具备了这个能力。
② 二是内置 MPP 抽取完进行数据驱动,例如物化视图完或数据抽取完以后可以实时触发缓存。
③ 三是用户可以通过调用 API 的方式,主动触发缓存。
下面介绍缓存运算器的原理。

这里主要讲四点:
第一点是用户行为分析:用户在打开报告后,会默认进行一些筛选,然后用户可以进行筛选器切换、图表联动、图表跳转等行为,此时随着图表的变换,缓存数据也会随之变动。因此,用户行为分析是希望从中找出规律,提高用户行为分析时的缓存命中率。
第二点是 QueryData:QueryData 是图表的查询请求输入,它主要分为两类,一类是图表默认的 QueryData;另一类是根据图表历史分析行为采集器生成的 QueryData,它可能有很多份,我们会选取 TopN 进行缓存。
第三点是权限判断:因为用户权限每天可能发生变化,因此我们会结合用户的资源权限和数据权限,最终选取 TopN 的用户进行缓存。
第四点是优先级计算:可以看到我们这里是根据 ROI 算法进行缓存的优先级判断的,计算因子包括 PV、UV、产出频率等等,最终计算出每一个用户和 queryData 的优先级。
除此之外,我们可以计算出:缓存总数量 = 用户数量 * queryData 数量。
下面是我们在云音乐环境下缓存实践效果统计:
① 首次缓存命中率从 35% 提高到 93%+。
② 整体缓存命中率从 70% 提高到 92%+。
③ 5 秒内页面响应占比从 70% 提高到 90%+。

下面是用户行为分析缓存的统计,可看到用户行为分析缓存命中率从 35% 提高到 80%+,效果比较明显。

三、图表查询的合并和优化
下图是一个报告的示例,可以看到该报告可能包含上百个图表,且每个图表都会产生一到多个 SQL 查询,而整体并发 SQL 查询越多,整体查询也就越慢。通过对比 SQL 分析,可以发现大部分 SQL 只是 select 字段不一样,where 和 group by 等条件可能都一样,那么对于这种查询就可以进行查询合并。

图表查询的合并和优化是通过查询视图的构建来实现的。
首先我们以报告为粒度进行查询视图的构建,一份报告对应多个查询视图,一个查询视图可以承载多个图表的查询,查询视图的聚合规则包含:Filter、Dimensions、Sorters 等。
假设一个报告内 Query DSL 有 N 个,Query DSL View 有 M 个,那么 N/M 越大,查询视图的价值就越大。

接下来我们介绍一下查询视图的查询流程优化:
首先,前端输入一个 Query Data,我们会找到对应的原始的 Query DSL,然后生成对应的查询视图,然后进行重组生成一个新的 Query DSL,新的 Query DSL 返回数据的时候,也会对查询结果进行反向还原。
然后 Query DSL 会经过缓存模块进行处理,这里有一个好处就是,多个相似图表的缓存可以进行复用,从而减少缓存数据大小和预缓存次数。
如果没有命中缓存,请求会经过我们的查询拦截器,拦截器可以保证同一个查询视图的请求只会下发一次。
以上的整个过程对前端来说是透明的,前端无需感知整个查询过程。

下面是图表查询合并后的实践效果:
其中 13000 多个查询视图可以承载 84000 多个查询,也就是 N/M≈1:7。
其中每日落库查询量从 7000 次下降到 3000 次左右,效果比较明显。

四、图表查询的其他优化
1、维值加速
下图是一家客户的查询报告,可以看到其中筛选器数量非常多,并且是根据明细数据进行去重聚合的,其查询也相对频繁,查询出来的成员较少且是固定的,此时我们可以通过维值加速进行优化。

我们可以通过以下几种方式进行维值加速:
动态值:可以把被查询的字段绑定到单独的维表字段上,最终查询筛选器数据时实际上查的是对应维表的数据。
静态值:对于静态值,可以直接对查询字段设置枚举,例如:性别的男、女等。
总体思路是减少对于明细表高频且耗时的聚合查询。
2、分区筛选器优化
因为大部分数据源都具备分区概念,如果能命中分区索引,就可以减少全表扫描,从而提升查询速度。
这里的分区查询筛选器优化,是结合了有数数据中台元数据中心,去获取对应表的分区字段,从而生成分区筛选器。当图表在查询的时候,我们会动态的获取分区筛选器的最近分区,同时会进行分区筛选的强制下推,从而提升查询性能。

分区筛选器有以下两个特点:
第一是由建模人员决定是否使用分区筛选器,这样可以规范分析师的使用流程。
第二是报告必须继承模型分区筛选器,同时不能进行删除。

3、查询分级优化
查询分级优化主要从四个方面介绍:
(1)查询分流
针对不同场景使用不同查询引擎,比如使用 Impala 数据源时支持使用 Spark 进行抽取和导出 Excel 相关查询。
(2)高低优先级查询队列
控制同一个数据源的并发 SQL。
优先保障重点用户(例如老板等)的看数需求等。
(3)重点报告/普通报告
重点报告优先缓存。
重点报告支持单独切换数据连接,比如 Impala 数据源可以走不同的分组。
(4)VIP 查询服务
部分报告的查询走单独的后端服务;
资源隔离,保障可用性。

4、前端渲染优化
主要包括以下三个方面:
① 查询组件分级:例如图表及 topN 筛选器可以进行高优先级加载,图片和普通筛选器做低优先级加载。
② 局部渲染优化:优先渲染视窗内的组件,非可视区域进行懒加载。
③ 请求队列控制:前端做了请求队列的控制,减少查询并发,从而避免一个用户就把数据源资源吃光。

5、SQL 生成优化
第五个就是我们会对第一章的讲到的 Query DSL 去生成 SQL 这个过程也做了一些通用的优化,比如筛选条件等价下推,Join 条件筛选传递,动态模型剪枝等优化。这些优化都会对特定场景的查询有较大的优化效果,右边这个图是我们字段类型转换做筛选的优化效果图,虽然该字段做了类型转换,其实我们也可以背后让他用原始的类型进行筛选,提高查询效率。

6、MPP 查询加速
对于一些异构数据源,我们可以通过数据抽取、数据准备、物化视图等方式,将数据抽取到 MPP 数仓,达到查询加速的目的。

五、图表的性能查询分析和诊断
前面我们介绍了很多图表查询性能优化的方式和方法,但是并不能解决所有的性能问题,新的性能问题总是会不断的产生。同时,有数 BI 的图表查询链路也较长,性能排查过程耗时耗力。虽然我们提供了很多图表性能的优化手段,分析师具体该如何选择也是问题。
我们做性能分析和诊断的目标是:
① 帮助用户快速定位问题。
② 输出准确的方案。
③ 直接赋能用户自我解决问题。
这个功能在我们产品功能上叫做“数据医生”,下面是我们数据医生实现的方案:
① 第一步是根据性能统计,发现到底是哪个图表慢。
② 第二步是找到某个具体图表以后我们可以进行全链路 timeline 计算和分析。
③ 第三步结合我们诊断的规则库,推断具体问题原因。
④ 第四步针对不同的问题,给出不同的解决方案。

另外我们还专门做了一层统一的针对 SQL profile 的性能解析层,会把不同数据源的 profile 进行统一的抽象,比如统计 SQL 的资源消耗,分区、存储格式等表的元信息,另外会对 Join 或者 Scan 算子的性能进行定义和解析,目前我们已经适配了 Impala 和 Clickhouse 两种数据源,右边是我们针对这个抽象的 SQL 粒度的性能解析在产品上的诊断结果的体现,我们会告知用户哪些表的扫描数据比较慢,哪些 Join 节点的计算比较慢,这样用户就很方便的发现具体的问题。

数据医生自助帮助用户解决了基本的性能问题,释放了技术支持和开发的人力。同时我们的诊断规则和经验也在不断持续积累。

六、总结
最后来做一个简单的总结。
(1)性能是 BI 产品的有理保障和核心竞争力,性能是保障用户体验的根基。
(2)解决性能问题一定要从用户使用场景出发,具体问题具体分析。
(3)提效和易用:尽可能地赋能用户自助解决问题的能力,提升产品效率和易用性。

七、问答环节
Q1:缓存是行列级别的吗?
A1:我们的缓存是缓存一份图表的数据,所以一个图表看能有多份缓存,不同用户不同权限看到图表数据可能不一样,同时我们也会对相同权限的用户进行去重和合并。
Q2:MPP 查询负载打满后怎么处理?
A2:MPP 这边我们有专人进行维护,会对 MPP 数据库的查询进行监控和告警,同时我们也会对 MPP 进行一些治理,例如:发现一些大查询我们会进行拦截等。
Q3:查询合并只针对指标卡吗?还是所有图表类型都会进行合并?
A3:查询合并目前最主要还是指标卡的应用场景,其他场景我们后面也会慢慢支持。
Q4:请问数据存储最终是存储到 MPP 里面的吗?还是说支持外部?
A4:对于有数 BI 来说,我们的图表查询是落到 MPP 数仓里面。对于外部数仓来说,我们支持 ETL 数据准备能力,进行一个数据清洗,可以把我们的数据准备清洗到外部数据库,目前 ETL 外部数据库已经支持 MySQL、Doris 等,然后用户可以通过建立数据连接在有数 BI 上进行查询和分析。
Q5:目前的性能诊断的数据医生,对于优化性能最大的是哪种手段?
A5:对于数据医生来说,只是诊断工具,并不是用来提升性能的。具体性能的提升,还是要通过物化视图、维值加速、分区筛选等手段进行,物化视图目前的性能提升相对较大。
Q6:查询视图与物化视图如何区分与使用?
A6:查询视图其实是物化视图前面的部分,为了构建 Query DSL 的输入,请求的链路到达查询器,才会命中后面的物化视图。