译者 | 李睿
审校 | 重楼
开发人员追求数据驱动的管理,他们的目标是在数据平台开发中满足四个需求:监控和警报、查询和分析、仪表板和数据建模。出于这些目的,他们基于Greenplum和CDH构建了数据处理架构。其中最重要的部分是风险数据集市。
风险数据集市:Apache Hive
以下介绍风险数据集市是如何按照数据流工作的:
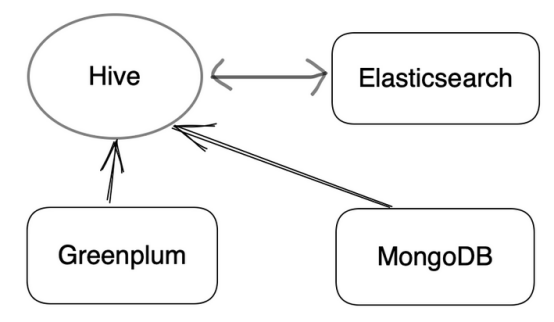
(1)业务数据被导入Greenplum进行实时分析以生成商业智能(BI)报告。这些数据的一部分也会进入Apache Hive进行查询和建模分析。
(2)风险控制变量在Elasticsearch中通过消息队列实时更新,同时Elasticsearch也将数据摄取到Hive中进行分析。
(3)将风险管理决策数据从MongoDB传递给Hive进行风控分析和建模。
这是风险数据集市的三个数据源。
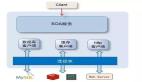
整个架构是用CDH 6.0构建的,其中的工作流程可分为实时数据流和离线风险分析。
- 实时数据流:来自Apache Kafka的实时数据将被Apache Flink清理,然后写入Elasticsearch。Elasticsearch会汇总接收到的部分数据,并将其发送给风险管理作为参考。
- 线下风险分析:基于CDH解决方案,利用Sqoop对其进行线下数据摄取。然后将这些数据与来自MongoDB的第三方数据放在一起。然后,经过数据清洗之后,将所有这些数据输入Hive中进行日常的批量处理和数据查询。
简要概述一下,这些组件支持数据处理平台的四个功能:
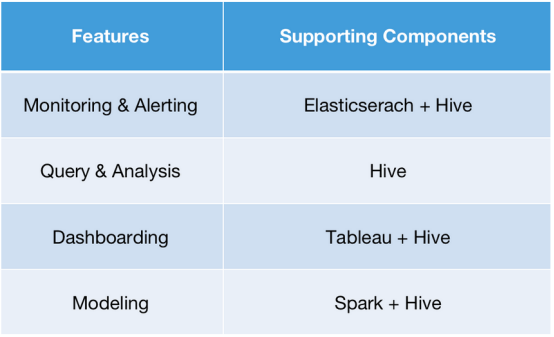
如上图所见,Apache Hive是这个架构的核心。但在实践中,Apache Hive执行分析需要几分钟,因此下一步是提高查询速度。
是什么拖慢了查询速度?
外部表中的巨大数据量
基于Hive的数据集市现在承载着超过300TB的数据。大约有2万个表和500万个字段。将它们全部放在外部表中是维护密集型的。此外,数据摄取可能是一个令人头疼的问题。
更大的平面表
由于风险管理中规则引擎的复杂性,企业在变量的推导上投入了大量的资金。在某些维度上,有数千个甚至更多的变量。因此,Hive中一些常用的平面表有超过3000个字段。因此,可以想象这些查询是多么耗时。
不稳定的接口
日常离线批处理产生的结果将定期发送到Elasticsearch集群 (这些更新中的数据量很大,接口调用可能会过期) 。这一过程可能导致高I/O并引入垃圾收集器抖动,从而进一步导致接口服务不稳定。
此外,由于风控分析师和建模工程师使用Hive和Spark,不断扩展的数据架构也拖累了查询性能。
统一查询网关
在此需要一个统一的网关来管理异构数据源。这就是为什么介绍Apache Doris的原因。
但这不会让事情变得更复杂吗?事实上并没有。
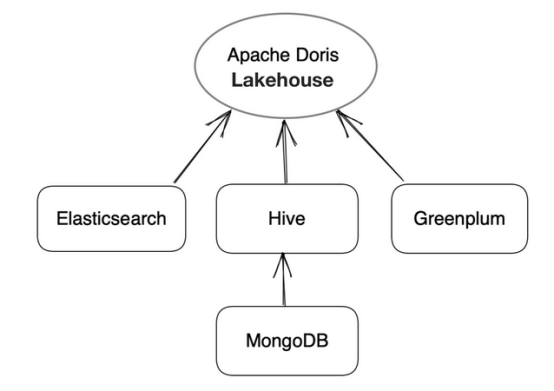
可以将各种数据源连接到Apache Doris,并简单地对其进行查询。这是由Apache Doris的多目录特性实现的:它可以与各种数据源接口,包括像Apache Hive、Apache Iceberg和Apache Hudi这样的数据湖,以及像MySQL、Elasticsearch和Greenplum这样的数据库。这恰好涵盖了工具箱。
在Apache Doris中创建Elasticsearch Catalog和Hive Catalog。这些目录映射到Elasticsearch和Hive中的外部数据,因此可以使用Apache Doris作为统一网关跨这些数据源执行查询。此外,使用Spark-Doris- connector来实现Spark和Doris之间的数据通信。所以基本上,用Apache Doris代替Apache Hive作为数据架构的中心枢纽。
这对数据处理效率有何影响?
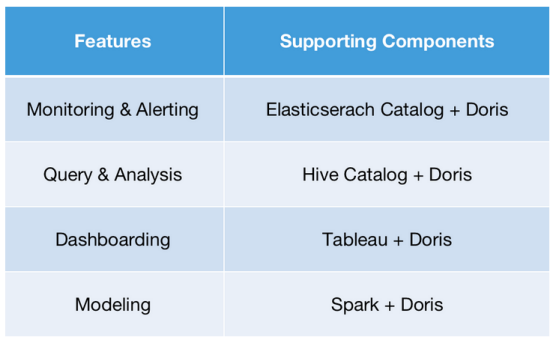
- 监控和警报:这是关于对实时数据的查询。使用Apache Doris中的Elasticsearch Catalog访问Elasticsearch集群中的实时数据。然后直接在Apache Doris中执行查询。它能够在几秒钟内返回结果,而不是使用Hive时的几分钟级别的响应时间。
- 查询和分析:在Hive中有20,000个表,所以将它们全部映射到Hive中的外部表是没有意义的。这需要花费一大笔维护费用。与其相反,利用Apache Doris 1.2的Multi Catalog特性。它支持目录级别的数据映射,因此可以简单地在Doris中创建一个Hive Catalog。然后再进行查询。这将查询操作从Hive的日常批量处理工作量中分离出来,从而减少资源冲突。
- 仪表板:使用Tableau和Doris提供仪表板服务。这将查询响应时间缩短到几秒和几毫秒,而在“Tableau + Hive”时则需要几分钟。
- 建模:使用Spark和Doris进行聚合建模。Spark-Doris-Connector允许数据的相互同步,因此来自Doris的数据也可以用于建模以进行更准确的分析。
生产环境中的集群监控
在生产环境中测试了这个新架构,为此建立了两个集群。
配置:
生产集群:4个前端+ 8个后端,m5d.16xlarge
备份集群:4个前端+ 4个后端,m5d.16xlarge
以下是监控板:
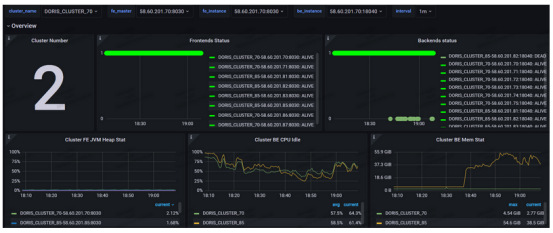
如上图所示,查询速度很快。预计它至少需要10个节点,但在实际情况中,主要通过Catalogs进行查询,因此可以用相对较小的集群大小来处理这个问题。兼容性也很好。它不会影响现有系统的其余部分。
快速数据集成指南
为了加速从Hive到Apache Doris 1.2.2的常规数据摄取,以下有一个解决方案:
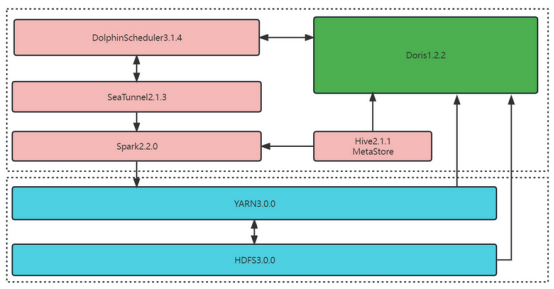
主要部件:
- Dolphin Scheduler 3.1.4
- SeaTunnel 2.1.3
对于当前的硬件配置,使用DolphinScheduler的Shell脚本模式,并定期调用SeaTunnel脚本。数据同步任务的配置文件:
SQL
env{
spark.app.name = “hive2doris-template”
spark.executor.instances = 10
spark.executor.cores = 5
spark.executor.memory = “20g”
}
spark {
spark.sql.catalogImplementation = “hive”
}
source {
hive {
pre_sql = “select * from ods.demo_tbl where dt=’2023-03-09’”
result_table_name = “ods_demo_tbl”
}
}
transform {
}
sink {
doris {
fenodes = “192.168.0.10:8030,192.168.0.11:8030,192.168.0.12:8030,192.168.0.13:8030”
user = root
password = “XXX”
database = ods
table = ods_demo_tbl
batch_size = 500000
max_retries = 1
interval = 10000
doris.column_separator = “\t”
}
}这一解决方案消耗更少的资源和内存,但在查询和数据摄取方面带来更高的性能。
更低的存储成本
- 之前:Hive中的原始表有500个字段。它按天划分为多个分区,每个分区有1.5亿条数据。在HDFS中存储需要810G存储空间。
- 之后:为了数据同步,使用SeaTunnel在YARN上调用Spark。它可以在40分钟内完成,并且摄取的数据只占用270G的存储空间。
更少的内存使用和更高的查询性能
- 之前:Hive中对上述表进行GROUP BY查询,占用720个内核,占用YARN 1.44T,响应时间为162秒。
- 之后:在Doris中使用Hive Catalog执行聚合查询,设置exec_mem_limit=16G,在58.531秒后收到结果。也尝试将表放入Doris,并在Doris本身进行同样的查询,只需要0.828秒。
其对应语句如下:
- Hive查询,响应时间:162秒。
SQL
select count(*),product_no FROM ods.demo_tbl where dt='2023-03-09'
group by product_no;- 在Doris中使用Hive Catalog查询,响应时间:58.531秒。
SQL
set exec_mem_limit=16G;
select count(*),product_no FROM hive.ods.demo_tbl where dt=’2023-03-09’
group by product_no;- 直接在Doris查询,响应时间:0.828秒。
SQL
select count(*),product_no FROM ods.demo_tbl where dt=’2023-03-09’
group by product_no;更快的数据摄取
- 之前:Hive的原始表有40个字段。它按天划分为多个分区,每个分区有11亿条数据。在HDFS中存储需要806G的存储空间。
- 之后:为了数据同步,使用SeaTunnel在YARN上调用Spark。可以在11分钟内完成(每分钟1亿条),并且所摄取的数据仅占用378G的存储空间。
结语
构建高性能风险数据集市的关键步骤是利用Apache Doris的Multi Catalog特性来统一异构数据源。这不仅提高了查询速度,而且还解决了以前的数据架构带来的许多问题。
- 部署Apache Doris允许将日常批处理工作负载与临时查询解耦,因此它们不必争夺资源。这将查询响应时间从几分钟缩短到几秒钟。
- 采用基于Elasticsearch集群构建数据摄取接口,这在传输大量离线数据时可能会导致垃圾收集器抖动。当将接口服务数据集存储在Doris上时,在数据写入过程中没有发现抖动,并且能够在10分钟内传输1000万行代码。
- Apache Doris已经在许多场景下进行了优化,包括平面表。与ClickHouse相比,Apache Doris 1.2在SSB-Flat-table基准测试中的速度快了一倍,在TPC-H基准测试中快了几十倍。
- 在集群扩展和更新方面,过去在修改配置后的恢复时间窗口很大。但是Doris支持热插拔和易于扩展,所以可以在几秒钟内重新启动节点,并最大限度地减少集群扩展对用户造成的干扰。
原文标题:Step-By-Step Guide to Building a High-Performing Risk Data Mart,作者:Jacob Chow