












偏度(skewness)是用来衡量概率分布或数据集中不对称程度的统计量。它描述了数据分布的尾部(tail)在平均值的哪一侧更重或更长。偏度可以帮助我们了解数据的偏斜性质,即数据相对于平均值的分布情况。

有时,正态分布倾向于向一边倾斜。这是因为数据大于或小于平均值的概率更高,因此使得分布不对称。这也意味着数据不是均匀分布的。
偏度可以与其他描述性统计一起描述变量的分布。通过偏度也可以判断变量是否为正态分布。因为正态分布的偏度为零,是许多统计过程的假设。
偏度分类
分布可以有右偏度(或正偏度)、左偏度(或负偏度)或零偏度。右偏态分布在其峰值的右侧较长,而左偏态分布在其峰值的左侧较长。
1、零偏度
—当一个分布的偏度为零时,它是对称的。它的左右两边是镜像。正态分布的偏度为零,但不是只有正态分布的偏度为零。任何对称分布,如均匀分布或某些双峰分布,偏度都是零。
检查变量是否具有倾斜分布的最简单方法是将其绘制成直方图。
分布近似对称,观测值在峰值的左右两侧分布相似。因此分布的偏度近似为零。
在零偏度的分布中,平均值和中位数是相等的,也就是说:
mean = median
2、右偏(正偏)
右偏分布在其峰值的右侧比其左侧更长。右偏也被称为正偏。它表明在分布的极端一端有观测值,但它们相对较少。右偏分布的右侧有一条长尾。
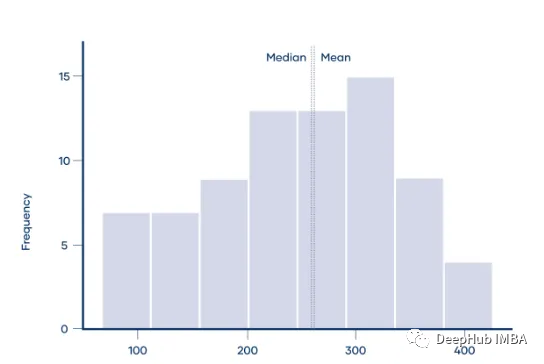
分布是右偏的,因为它在峰值右侧的时间更长。右偏分布的均值几乎总是大于中位数。这是因为极值(尾部的值)对均值的影响大于中位数。
mean > median
3、左偏(负偏)
左偏分布的峰值左侧比右侧更长。左偏分布的左侧有一条长尾。左偏也被称为负偏。

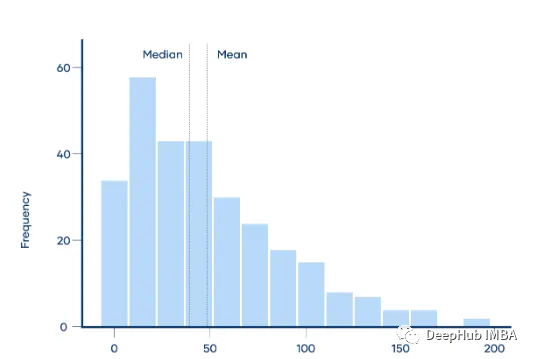
这个分布是左偏的,因为它在峰值的左侧更长。左偏分布的均值几乎总是小于中位数。
mean < median
偏度计算
有几个公式可以用来测量偏度。其中最简单的是皮尔逊中值偏度。它就是利用了上面我们说的偏态分布中均值和中位数不相等来计算的。

皮尔逊中位数偏度是计算均值和中位数之间有多少个标准差。
真实的观测很少有刚好为0的皮尔逊偏中值。因为如果数据的值接近于0,则可以认为它具有零偏度,但是在实际数据中很少有没有零偏度的分布数据。
例如,我们每年观测到的太阳黑子数量的Pearson中位数偏度:平均值= 48.6,中位数= 39,标准差= 39.5。那么公式如下:

如果该值介于:
- -0.5和0.5,值的分布几乎对称
- -1和-0.5之间为负偏斜,0.5到1之间为正偏斜。偏度适中。
- 如果偏度小于-1(负偏)或大于1(正偏),则数据是高度偏斜。
如何处理有偏度数据
如果你的统计过程需要正态分布并且你的数据是倾斜的,你通常有三个选择:
- 什么也不做:许多统计检验,包括t检验、方差分析和线性回归,对偏斜数据不太敏感。特别是如果偏斜是轻微或中度的,最好的办法就是忽略它。
- 数据转换:通过对数据应用某种变换,可以调整数据的分布形状,使其更接近对称分布。常见的数据转换方法包括取对数、开方、平方根等。这些转换可以减小或消除数据的偏度。
- 使用不同的模型:你可能想选择一个不假设正态分布的模型,非参数测试或广义线性模型可能更适合您的数据。比如说非参数方法:如果数据的偏度较大,而且无法通过简单的转换来纠正,可以考虑使用非参数统计方法。非参数方法不依赖于分布的假设,而是直接对数据进行分析,例如使用中位数作为代表性的位置测度,而不是平均值。
- 分组分析:如果数据集中存在明显的子群体,可以考虑对数据进行分组分析。通过将数据分成多个子群体,并对每个子群体进行单独的分析,可以更好地了解数据的特征和偏度情况。
- 针对特定问题采取相应的方法:根据具体的数据和分析目的,可以采用特定的方法来处理偏度数据。例如,在回归分析中,可以使用偏度稳定转换(skewness-stabilizing transformation)来调整数据的偏度,以满足回归模型的假设。
下表总结了一些常用数据变换:

总结
数据的偏度是用来衡量概率分布或数据集中不对称程度的统计量。它描述了数据分布的尾部在平均值的哪一侧更重或更长。通过计算偏度,可以更好地了解数据的分布特征,并在需要时采取适当的数据处理或分析方法。但是需要注意的是,偏度只是数据分布的一种度量,不能完全代表数据的整体特征,因此在分析数据时需要综合考虑其他统计指标和可视化方法。














