译者 | 朱先忠
审校 | 重楼
简介
ChatGPT是一种GPT(生成式预训练转换器)机器学习(ML)工具,如今它让整个世界为之惊讶。它惊人的功能给普通用户、专业人士、研究人员,甚至它自己的创造者留下了深刻印象。此外,它能够成为一个加速一般任务完成进度的机器学习模型,并在特定领域的情况下表现出色,这一能力给人留下深刻的印象。我是一名研究人员,ChatGPT进行情绪分析(SA)的强大能力也让我非常感兴趣。
情绪分析是一种非常广泛的自然语言处理(NLP)。它有多种应用,因此可以应用于多个领域(如金融、娱乐、心理学等)。不过,有些领域使用的是特定的术语(例如金融领域)。因此,通用领域ML模型是否能够像特定领域模型一样强大,仍然是NLP中一个悬而未决的研究问题。
如果你问ChatGPT这个研究问题(这是本文的标题),那么它会给你一个谦逊的答案(继续,试试看)。但是,我亲爱的读者,我通常不愿在这方面扫你的兴;不过,你不知道这个ChatGPT的答案有多谦虚……
尽管如此,作为一名人工智能研究人员、行业专业人士和业余爱好者,我习惯于细调通用领域NLP机器学习工具(例如GloVe),以用于特定领域的任务。之所以会出现这种情况,是因为对于大多数领域来说,找到一种开箱即用的、不经微调就能做得足够好的解决方案并不常见。本文中,我将向你展示这种情况以后将不再成为常态。
在本文中,我通过讨论以下主题将ChatGPT与特定领域的ML模型进行比较:
- SemEval 2017任务5——一种特定领域的挑战
- 使用ChatGPT API实战性代码来标记一个数据集
- 与再现性细节比较的结论和结果
- 结论和结果讨论
- 扩展思索:如何在应用场景中进行比较
注1:本文给出的只是一个简单的动手实验,将有助于对于文章主题的了解,而不是一份详尽的科学调查。
注2:除非另有说明,否则所有图片均由作者提供。
1.SemEval 2017任务5——一种特定领域的挑战
SemEval(语义评估)是一个著名的NLP研讨会,研究团队在情感分析、文本相似性和问答任务方面进行科学竞争。组织者提供由注释者(领域专家)和语言学家创建的文本数据和黄金标准数据集,以评估每项任务的最先进解决方案。
特别是,SemEval 2017年的任务5要求研究人员对金融微博和新闻头条进行情绪分析,评分为-1(最负面)到1(最正面)。我们将使用当年SemEval的黄金标准数据集来测试ChatGPT在特定领域任务中的性能。子任务2数据集(新闻标题)使用两组句子(每个句子最多30个单词):训练集(1142个句子)和测试集(491个句子)。
考虑到这些数据集合,情绪得分和文本句子的数据分布如下所示。下图显示了训练集和测试集中的双峰分布。此外,该图表明数据集中积极的句子多于消极的句子。
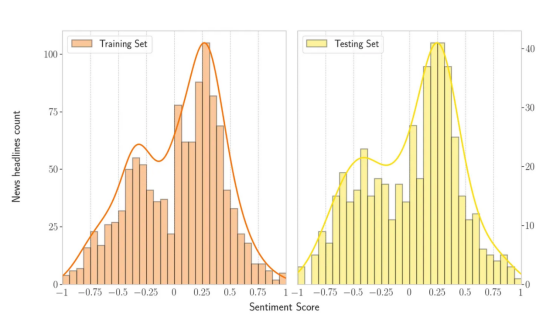
SemEval 2017任务5子任务2(新闻标题):考虑训练(左边——1142个句子)和测试(右边——491个句子)集的数据分布情绪得分。
对于这个子任务,获胜的研究团队(即在测试集中排名最好的团队)将他们的ML架构命名为Fortia FBK。受此次比赛发现的启发,我和一些同事写了一篇研究文章(评估金融文本中基于回归的情绪分析技术),在文章中我们实现了Fortia FBK版本,并评估了改进该架构的方法。
此外,我们还调查了使该体系结构成为制胜体系结构的因素。因此,我们对这一获胜架构(即Fortia FBK)的实现(源码在这里:https://bit.ly/3kzau8G)用于与ChatGPT进行比较。所采用的架构(CNN+GloVe+Vader)如下所示:
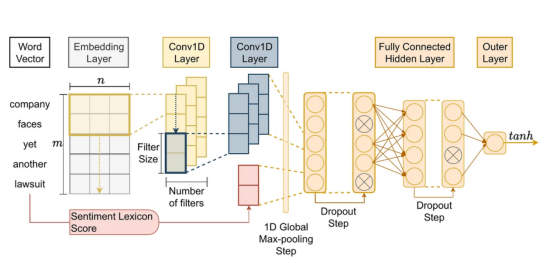
金融新闻领域的特定领域情绪分析ML模型,对应于研究文章“评估金融文本中基于回归的情绪分析技术”的开发架构。来源:作者硕士学位论文(Lima Paiva,F.C.,“在智能交易的强化学习中同化情绪分析”)。
2.使用ChatGPT API标记数据集
使用ChatGPT API的基本思路早已经在Medium网站上讨论过,用于合成数据。此外,您可以在ChatGPT API代码示例部分中找到情感标签示例(请注意,使用该API并不是免费的)。对于这个代码示例,请考虑使用SemEval的2017任务黄金标准数据集,您可以在链接https://bitbucket.org/ssix-project/semeval-2017-task-5-subtask-2/src/master/处获得该数据集。
接下来,要使用API一次标记多个句子,请使用如下这样的代码,其中我用黄金标准数据集的数据框中的句子准备一个完整的提示符,其中包含要标记的句子和情绪所指的目标公司。
def prepare_long_prompt(df):
initial_txt = "Classify the sentiment in these sentences between brackets regarding only the company specified in double-quotes. The response should be in one line with format company name in normal case followed by upper cased sentiment category in sequence separated by a semicolon:\n\n"
prompt = "\"" + df['company'] + "\"" + " [" + df['title'] + ")]"
return initial_txt + '\n'.join(prompt.tolist())然后,调用text-davinci-003引擎(GPT-3版本)的API。在这里,我对代码进行了一些调整,考虑到提示中的最大总字符数加上答案,最多必须是4097个字符。
def call_chatgpt_api(prompt):
#获取允许用于响应的最大令牌数量:基于api最大值为4097并考虑到提示文本的长度。
prompt_length = len(prompt)
max_tokens = 4097 - prompt_length
# 这个除以10的规则只是一个经验估计,不是一个精确的规则
if max_tokens < (prompt_length / 10):
raise ValueError(f'Max allowed token for response is dangerously low {max_tokens} and might not be enough, try reducing the prompt size')
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=0,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response.choices[0]['text']
long_prompt = prepare_long_prompt(df)
call_chatgpt_api(long_prompt)最终,在黄金标准数据集中对总共1633个句子(训练+测试集)执行此操作,您将得到以下ChatGPT API标记的结果。

SemEval 2017任务5子任务2(新闻标题)黄金标准数据集示例:使用ChatGPT API标记情绪。
2.1.ChatGPT及其API的规模问题
与其他任何API一样,ChatGPT的API应用也存在如下一些典型的要求:
- 需要调节的请求速率限制
- 25000个令牌的请求限制(即子字单元或字节对编码)
- 每个请求的最大长度为4096个令牌(包括提示+响应)
- 0.0200/1K代币的成本(注意:我完成所有任务后,花费从未超过2美元)
然而,这些只是处理大多数API时的典型需求。此外,请记住,在这个特定领域的问题中,每个句子都通过一个目标实体(即公司)来表达情感。因此,我不得不反复调整关键词,最终我才设计了一个提示模式,可以同时标记几个句子的情感,并使之后的处理结果变得容易。此外,还有其他限制影响了我之前展示的提示和代码。具体来说,我发现在多个句子中使用此文本API存在问题(>1000)。
- 再现性:只需对提示进行很少的更改(例如,添加或删除句子中的逗号或点),ChatGPT对情绪的情绪评估就可能会发生显著变化。
- 一致性:如果你没有明确指定模式响应,ChatGPT将变得非常有创意(即使你选择了一个非常低的随机性参数),从而导致很难处理结果。此外,即使指定了模式,它也可能输出不一致的输出格式。
- 不匹配:尽管它可以非常准确地识别你想在一句话中评估情绪的目标实体(例如公司),但在进行大规模评估时,它可能会混淆结果——例如,假设你输入10句话,其中第一句对应一家目标公司。尽管如此,其中一些公司还是出现在其他句子中或被重复出现。在这种情况下,ChatGPT可以使目标和句子情感不匹配,改变情感标签的顺序或提供少于10个标签。
- 偏见:目前,ChatGPT偏见的问题是众所周知的。还有一些关于如何改善这个问题的想法。然而,在此之前,请注意您正在学习使用有偏见的API。
所有这些问题都意味着,正确使用(有偏见的)API需要一条学习曲线。它需要一些微调才能得到我需要的东西。有时我不得不做很多试验,直到我以最低的一致性达到预期的结果。
在理想的情况下,你应该同时发送尽可能多的句子,原因有两个。首先,你想尽快拿到你的标签。其次,提示在成本耗费中被视为令牌,因此更少的请求意味着更少的成本花费。然而,我们遇到了每个请求有4096个令牌的限制。此外,考虑到我提到的问题,还存在另一个值得注意的API限制。那就是,一次过多的句子会增加不匹配和不一致的几率。因此,你应该不断增加和减少句子的数量,直到你找到一致性和成本的最佳点。如果你做得不好,你将在后处理结果阶段受到影响。
总之,如果你有数千个句子要处理,从一批六个句子和不超过10个提示开始,检查回答的可靠性。然后,慢慢增加数量以验证容量和质量,直到找到适合您任务的最佳提示和成本耗费。
3.结论和比较结果
3.1.比较细节
在ChatGPT的GPT-3版本中,它无法将情感归因于使用数值的文本句子(无论我尝试了多少)。然而,专家们在这个特殊的黄金标准数据集中将数字分数归因于句子情感。
因此,为了进行一次可行的比较,我必须:
- 将数据集得分分类为“正”、“中性”或“负”标签。
- 对特定领域的ML模型生成的分数也执行同样的操作。
- 定义一系列可能的阈值(步长为0.001),用于确定一个类别的起点和终点。然后,给定阈值TH,高于+TH的分数被认为是积极情绪,低于-TH的分数是消极情绪,介于两者之间的分数是中性情绪。
- 在阈值范围内进行迭代,并评估两个模型在每个点的准确性。
- 考虑到特定领域模型在训练集中具有不公平的优势,按集合(即训练或测试)调查它们的性能。
其中,上述步骤3的代码如下所示。复制整个比较过程的完整代码位于链接https://drive.google.com/drive/folders/1_FpNvcGjnl8N2Z_Az3FGGWQ4QxmutmgG?usp=share_link处。
def get_df_plot(df, th_sequence):
temp_list = []
for th in th_sequence:
converted_gold_arr = np.where((df['sentiment'] <= th) & (df['sentiment'] >= -th), 0, np.sign(df['sentiment']))
converted_model_arr = np.where((df['cnn-pred-sent'] <= th) & (df['cnn-pred-sent'] >= -th), 0, np.sign(df['cnn-pred-sent']))
df['sent_cat_value'] = converted_gold_arr.astype(np.int64)
df['cnn_pred_sent_cat_value'] = converted_model_arr.astype(np.int64)
corr_gold_chatgpt = df['chatgpt_sent_value'].corr(df['sent_cat_value'])
corr_gold_cnn = df['chatgpt_sent_value'].corr(df['cnn_pred_sent_cat_value'])
acc_gold_chatgpt = (df['chatgpt_sent_value']==df['sent_cat_value']).mean()
acc_gold_cnn = (df['chatgpt_sent_value']==df['cnn_pred_sent_cat_value']).mean()
temp_list.append([th, corr_gold_chatgpt, corr_gold_cnn, acc_gold_chatgpt, acc_gold_cnn])
return pd.DataFrame(data=temp_list, columns=['th', 'corr_gold_chatgpt', 'corr_gold_cnn', 'acc_gold_chatgpt', 'acc_gold_cnn'])
th_sequence = np.arange(0, 1.000001, 0.001)
df_plot = get_df_plot(df.copy(), th_sequence)3.2.结论:ChatGPT不仅可以获胜,而且可以打破竞争
最终结果显示在下图中,其中显示了在对数字黄金标准数据集进行分类时,随着阈值(x轴)的调整,两个模型的精度(y轴)是如何变化的。此外,训练集和测试集分别位于左侧和右侧。
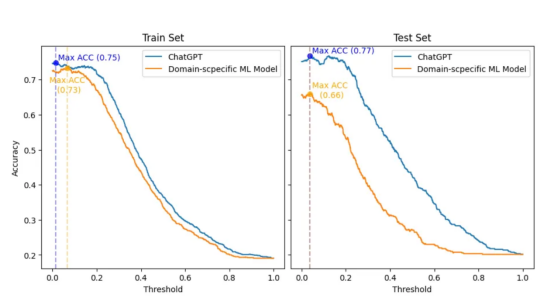
ChatGPT和领域特定ML模型之间的比较,该模型分别考虑了训练(左侧)和测试(右侧)集。该计算过程评估了精度(y轴)相对于阈值(x轴)的变化,用于对两个模型的数字黄金标准数据集进行分类。
首先,我必须承认:我没想到会有如此惊人的结果。因此,为了对ChatGPT公平起见,我复制了最初的SemEval 2017比赛设置,其中领域特定的ML模型将与训练集一起构建。然后,实际的排名和比较将只在测试集上进行。
然而,即使在训练集中,在最有利的情况下(阈值为0.066,而ChatGPT为0.014),领域特异性ML模型的精度也最多比ChatGPT的最佳精度(0.73相对于0.75)低2pp。此外,在训练和测试集中,ChatGPT在所有阈值上的精度都优于领域特异性模型。
有趣的是,两种模型的最佳阈值(0.038和0.037)在测试集中极其接近。在这个阈值下,ChatGPT的准确率比领域特定模型高出11pp(0.66比077)。此外,与领域特定模型相比,ChatGPT在阈值变化方面表现出更好的一致性。因此,可以看出,ChatGPT的准确性下降幅度要小得多。
在简历中,ChatGPT在准确性上大大优于领域特定ML模型。此外,从这里得到的想法是:ChatGPT可以针对特定任务进行微调。因此,想象一下ChatGPT会变得多么好。
3.3.调查ChatGPT情绪标签
我一直打算通过举例说明ChatGPT不准确的地方,并将其与领域特定模型进行比较,来进行更微观的调查。然而,由于ChatGPT的进展比预期的要好得多,所以我只得选择继续调查它错过了正确情绪的情况。
最初,我进行了与以前类似的评估,但现在立即使用完整的黄金标准数据集。接下来,我选择了阈值(0.016),用于将黄金标准数值转换为产生ChatGPT最佳精度(0.75)的正、中性和负标签。然后,我制作了一个混淆矩阵,其绘制结果如下:
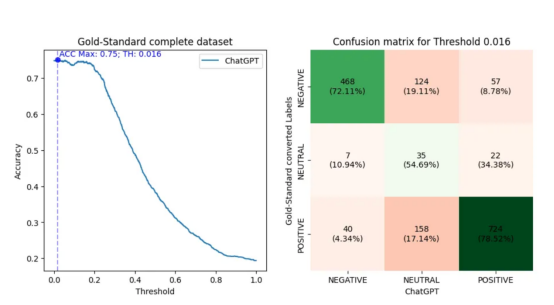
在图形左侧给出的是一条折线图,用于评估ChatGPT的准确性(y轴)相对于对数字黄金标准完整数据集进行分类的阈值(x轴)是如何变化的。在图形右侧给出的是正、中性和负标签对应的混淆矩阵,这里假设导致最大ChatGPT性能的阈值为0.016。此外,混淆矩阵还包含根据转换后的标签ChatGPT的命中和未命中的百分比。
回想一下,我在前一节中展示了积极得分比消极得分多的数据句子的分布。在混淆矩阵中,观察到考虑0.016的阈值,有922个(56.39%)阳性句子,649个(39.69%)阴性句子,64个(3.91%)中性句子。
此外,请注意,使用中性标签时,ChatGPT的准确性较低。这是意料之中的事,因为这些标签更容易受到阈值限制的影响。有趣的是,ChatGPT倾向于将这些中性句子中的大多数归类为阳性。然而,由于较少的句子被认为是中性的,这种现象可能与数据集中较大的积极情绪得分有关。
另一方面,当考虑其他标签时,ChatGPT显示出正确识别阳性类别比阴性类别多6个百分点的能力(78.52%对72.11%)。在这种情况下,我不确定这与每个分数谱段的句子数量有关。首先,因为每个类别类型的句子要多得多。其次,观察ChatGPT的未命中次数,这些未命中次数流向相反方向的标签(从正到负,反之亦然)。同样,ChatGPT在负面类别中犯了更多这样的错误,数量要少得多。因此,ChatGPT似乎对否定句比对肯定句更感困扰。
3.4.与人类专家的一些具体案例以及比较
我选择了几个在黄金标准(人类分数)和ChatGPT之间具有最显著特殊性的句子。然后,我使用之前建立的相同阈值将数字分数转换为情绪标签(0.016)。此外,据报道,ChatGPT的表现优于人类。因此,我调查了这些差异,并给出了我的裁决,我发现无论是人类还是ChatGPT都更准确。
此外,至少从2018年开始,美国国防高级研究计划局(DARPA)就深入研究了为人工智能决策带来可解释性的重要性。引人注目的是,ChatPGT展现了这样一种能力:它可以解释自己的决定。这种能力帮助我做出了裁决。下表显示了此检查结果。
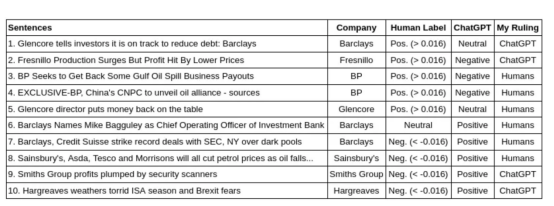
该表显示了黄金标准标签(使用0.016阈值从人类专家的分数转换而来)和ChatGPT之间不匹配的句子示例。此外,我给出了我最同意的裁决。
从我做出有利于人类专家裁决的案例开始。在第3句和第4句的情况下,ChatGPT应该意识到,收回支出和公司联盟在金融领域通常被认为是有益的。然而,在第7句的情况下,我要求它解释其决定,以下是ChatGPT的英文回答:
The positive sentiment towards Barclays is conveyed by the word “record,” which implies a significant accomplishment for the company in successfully resolving legal issues with regulatory bodies.
中文意思是:“记录”一词表达了对巴克莱银行的积极情绪,这意味着该公司在成功解决与监管机构的法律问题方面取得了重大成就。
就这句话而言,ChatGPT并不理解,尽管达成创纪录的交易通常是好的,但美国证券交易委员会是一个监管机构。因此,与美国证券交易委员会达成创纪录的交易意味着巴克莱和瑞士信贷必须支付创纪录的罚款。
接下来是第5句和第8句,这些都是非常艰难的判罚。这让我更明确一点,人类的评估是正确的。然而,事实上,ChatGPT根本猜不到这些。在第5句中,需要及时了解当时的情况,才能理解这句话代表了一个好的结果。对于第8句,需要知道油价下跌与特定目标公司的股价下跌相关。
然后,对于第6句,这是一个情绪得分为零的情况下所能得到的最中性的句子,ChatGPT对其决定英文解释如下:
The sentence is positive as it is announcing the appointment of a new Chief Operating Officer of Investment Bank, which is a good news for the company.
中文意思是:这句话很积极,因为它宣布任命投资银行新任首席运营官,这对公司来说是个好消息。
然而,这是一个笼统的、不太有见地的回应,并不能证明为什么ChatGPT认为任命这位高管是好的。因此,在这种情况下,我同意人类专家的意见。
有趣的是,我在第1、2、9和10句中对ChatGPT做出了有利的裁决。此外,仔细观察,人类专家应该更多地关注目标公司或整体信息。这在第1句中尤其具有象征意义,专家们应该认识到,尽管Glencore公司的情绪是积极的,但目标公司是刚刚撰写报告的巴克莱银行。从这个意义上说,ChatGPT更好地识别了这些句子中的情感目标和含义。
4.结论和结果讨论
如下表所示,实现这样的性能需要大量的财政和人力资源。
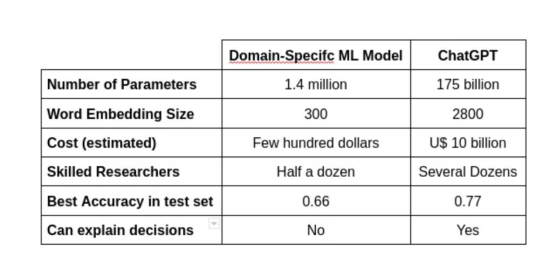
模型各方面的比较,如参数的数量、使用的单词嵌入大小、成本、构建它的研究人员数量、测试集中的最佳准确性,以及它的决定是否可以解释。
从这个意义上说,尽管ChatGPT的性能优于特定领域的模型,但最终的比较需要针对特定领域的任务对ChatGPT进行微调。这样做将有助于解决微调性能的收益是否超过努力成本的问题。
此外,文本模型中最重要的因素之一是单词嵌入的大小。这项技术自SemEval 2017版以来一直在发展。因此,这一部分中的一些更新可以显著提高特定领域模型的结果。
另一方面,随着生成文本模型和LLM的流行,一些开源版本可能有助于组装一个有趣的未来比较。此外,ChatGPT等LLM解释其决策的能力是一项杰出的、可以说是出乎意料的成就,可以彻底改变该领域。
5.扩展考虑:如何在应用场景中进行这种比较
不同领域的情绪分析是一项独立的科学研究。尽管如此,将情绪分析的结果应用于适当的场景可能是另一个科学问题。此外,当我们考虑金融领域的句子时,将情感特征添加到应用智能系统中会很方便。这正是一些研究人员一直在做的事情,我也在进行实验。
2021年,我和一些同事发表了一篇关于如何在应用场景中使用情绪分析的研究文章。在第二届ACM金融人工智能国际会议(ICAIF’21)上发表的这篇文章中,我们提出了一种将市场情绪纳入强化学习架构的有效方法。这个链接提供了实现该体系结构的源代码,下面显示了其整体设计的一部分。
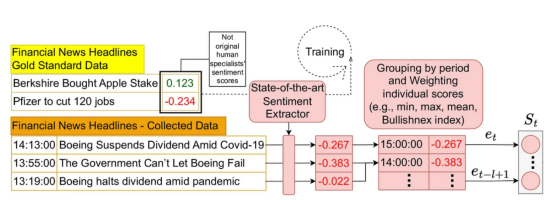
我们所构建的架构示例的一部分,说明如何将市场情绪纳入应用场景的强化学习架构中。资料来源:《智能交易系统:一种情绪感知强化学习方法》。第二届ACM金融人工智能国际会议论文集(ICAIF’21)。作者信息:Lima Paiva, F. C.; Felizardo, L. K.; Bianchi, R. A. d. C. B.; Costa, A. H. R.
该体系结构设计用于处理像黄金标准数据集中那样的数字情感分数。尽管如此,还是有一些技术(例如,Bullishanex指数)可以将分类情绪转换为适当的数值,这是由ChatGPT生成的。应用这样的转换可以在这样的体系结构中使用ChatGPT标记的情感。此外,这是在这种情况下你可以做什么的一个例子,也是我打算在未来的分析中做的。
5.1.我研究领域的其他论文(自然语言处理、强化学习有关)
- Lima Paiva, F. C.; Felizardo, L. K.; Bianchi, R. A. d. C. B.; Costa, A. H. R. Intelligent Trading Systems: A Sentiment-Aware Reinforcement Learning Approach. Proceedings of the Second ACM International Conference on AI in Finance (ICAIF ‘21).
- Felizardo, L. K.; Lima Paiva, F. C.; de Vita Graves, C.; Matsumoto, E. Y.; Costa, A. H. R.; Del-Moral-Hernandez, E.; Brandimarte, P. Outperforming algorithmic trading reinforcement learning systems: A supervised approach to the cryptocurrency market. Expert Systems with Applications (2022), v. 202, p. 117259.
- Felizardo, L. K.; Lima Paiva, F. C.; Costa, A. H. R.; Del-Moral-Hernandez, E. Reinforcement Learning Applied to Trading Systems: A Survey. arXiv, 2022.
本文中所使用的资源
主要引用文献
- Khadjeh Nassirtoussi, A., Aghabozorgi, S., Ying Wah, T., and Ngo, D. C. L. Text mining for market prediction: A systematic review. Expert Systems with Applications (2014), 41(16):7653–7670.
- Loughran, T. and Mcdonald, B. When Is a Liability Not a Liability ? Textual Analysis , Dictionaries , and 10-Ks. Journal of Finance (2011), 66(1):35–65.
- Hamilton, W. L., Clark, K., Leskovec, J., and Jurafsky, D. Inducing domain-specific sentiment lexicons from unlabeled corpora. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 595–605.
- Cortis, K.; Freitas, A.; Daudert, T.; Huerlimann, M.; Zarrouk, M.; Handschuh, S.; Davis, B. SemEval-2017 Task 5: Fine-Grained Sentiment Analysis on Financial Microblogs and News. Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017).
- Davis, B., Cortis, K., Vasiliu, L., Koumpis, A., Mcdermott, R., and Handschuh, S. Social Sentiment Indices Powered by X-Scores. ALLDATA, The Second Inter-national Conference on Big Data, Small Data, Linked Data and Open Data (2016).
- Ferreira, Taynan; Lima Paiva, F. C.; Silva, Roberto da; Paula, Angel de; Costa, Anna; Cugnasca, Carlos. Assessing Regression-Based Sentiment Analysis Techniques in Financial Texts. 16th National Meeting on Artificial and Computational Intelligence (ENIAC), 2019.
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Can ChatGPT Compete with Domain-Specific Sentiment Analysis Machine Learning Models?,作者:Francisco Caio Lima Paiva