












在设计应用程序时,我们经常会遇到这样的场景:检查某个元素是否存在于集合中。例如,当创建一个新的电子邮件帐户时,你需要输入一个电子邮件地址。系统会告诉你电子邮件地址是否已被占用。如果已经参加,你将测试不同的,直到找到可用的。
在后端,系统会根据数百万个现有电子邮件地址检查你的电子邮件地址,以检查是否存在匹配项。并且系统会在几分之一秒内回答你。传统的索引线性搜索无法快速给出结果。哈希映射可以完成这项工作,但它会占用大量内存空间。
布隆过滤器是上述用例的最佳解决方案。它的最佳场景实践如下:
- 需要快速检查某个项目是否在列表中。
- 列表很大,内存空间有限。
什么是布隆过滤器?
布隆过滤器(Bloom filter)是一种概率数据结构,由 Burton Howard Bloom 于 1970 年设计,用于检查元素是否是集合的成员。
布隆过滤器提供的快速查找有一个陷阱——误报。误报是指集合中不存在某个元素,但系统告诉你它存在的情况。不过误报的概率通常比较低。
布隆过滤器如何工作?
布隆过滤器是m位的位向量,最初全部设置为 0。
例如,下面是一个 12 位布隆过滤器。所有位最初都是 0。位下方的数字表示该位的索引。索引从 0 开始到m-1(在本例中为 11)。

要将元素添加到布隆过滤器,我们需要k个哈希函数。每个要加入布隆过滤器的元素都会经过k个哈希函数,得到k个固定大小的哈希值。
接下来,我们对每个哈希值(在我们的例子中是哈希值 % 12 )取m的模,以获得小于或等于 m-1 的索引。通过操作获得的索引中存在的位在位向量中设置为 1。使用相同的方法继续将每个元素添加到布隆过滤器。
除了向过滤器添加元素外,我们还可以检查它们是否存在与过滤器中。为了检查元素是否存在,我们使用与上述相同的过程对元素执行哈希和取模。获得索引后,检查这些索引中存在的位的值,以推断该元素是否存在。通过下面的示例,来更好地理解这个概念。
请注意,你只能将元素添加到布隆过滤器或检查元素是否存在与过滤器中。添加后,无法从过滤器中删除元素。
例子
假设我们有一个 12 位布隆过滤器和 3 个哈希函数 h1(x)、h2(x)、h3(x)。首先,我们将向布隆过滤器添加元素。接下来,我们将检查过滤器中是否存在元素。
向过滤器添加元素
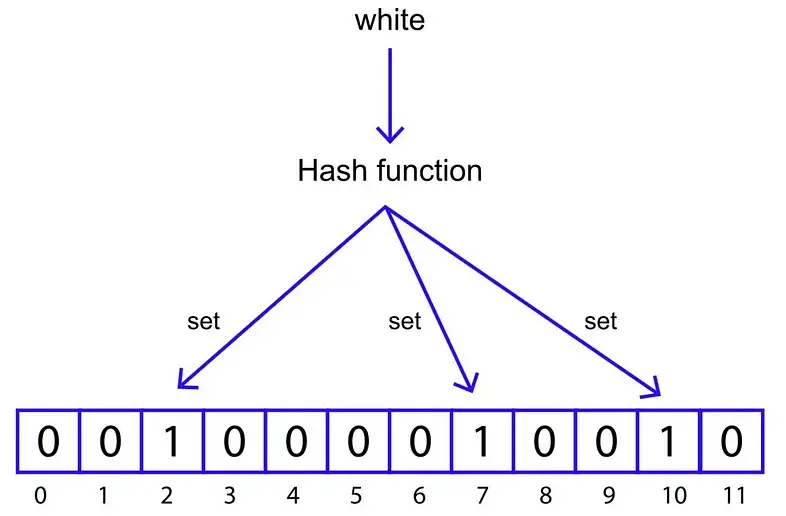
把字符串“white”添加到空的布隆过滤器中。
将它提供给我们示例中的三个哈希函数,并取 12 的模作为结果,如下:
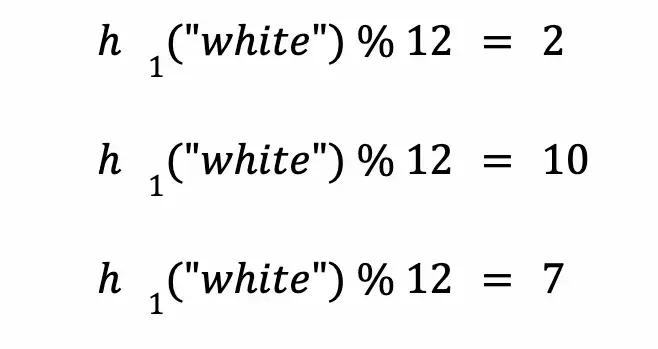
将索引 2、10 和 7 处的位设置为 1。布隆过滤器将变成这样:
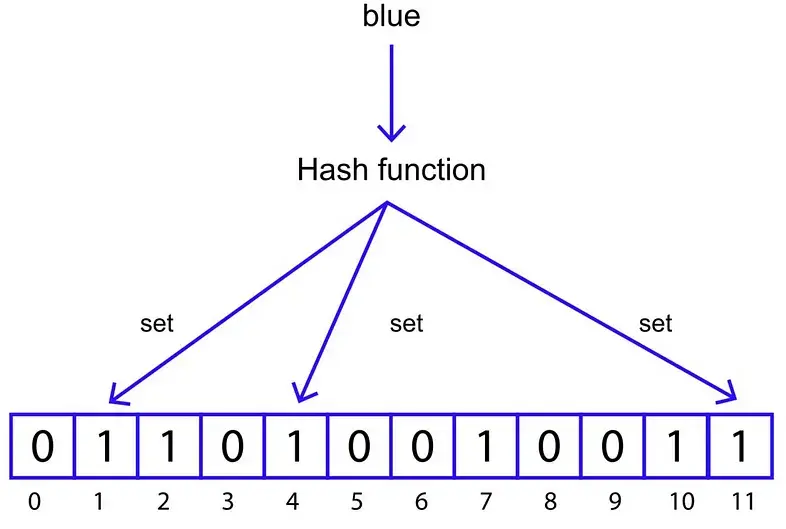
接下来,添加另一个元素“blue”。
将字符串提供给三个散列函数并取模,我们得到另外 3 个要设置的索引:
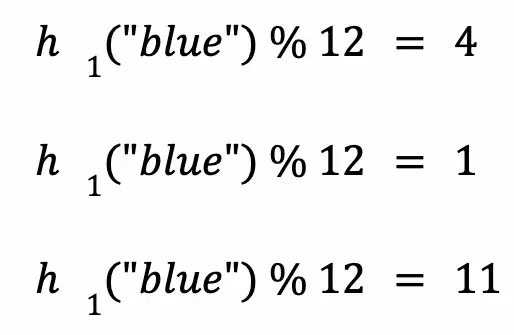
索引 4、1 和 11 处的位也将设置为 1。现在布隆过滤器如下所示:
检查元素是否在过滤器中
现在我们的布隆过滤器有一些元素(本例中为“white”和“blue”)。让我们检查集合中是否存在元素“purple”。
对“purple”执行相同的操作,找到它的哈希值并取模:
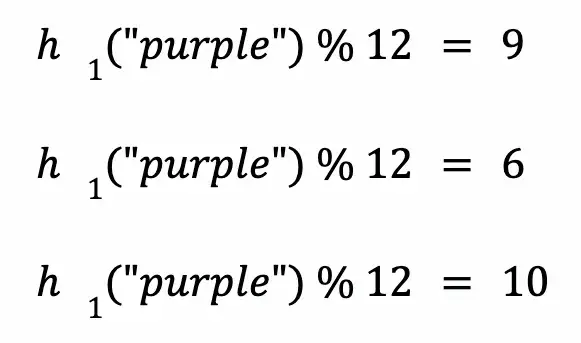
检查上面计算的索引处的位值。如果所有三个索引的位都是 1,我们可以说过滤器中可能存在“purple”。如果这些索引处的至少一位为 0,我们可以说过滤器中不存在“purple”。
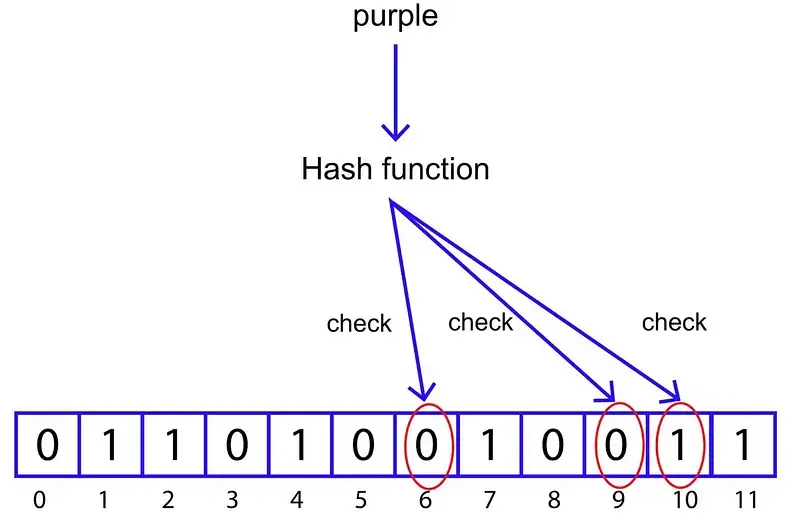
由于上图中索引 6 和 9 的位为 0,我们知道“purple”不在过滤器中。
接下来,我们检查过滤器中是否有“blue”。
对“blue”执行哈希函数和取模来获得索引:
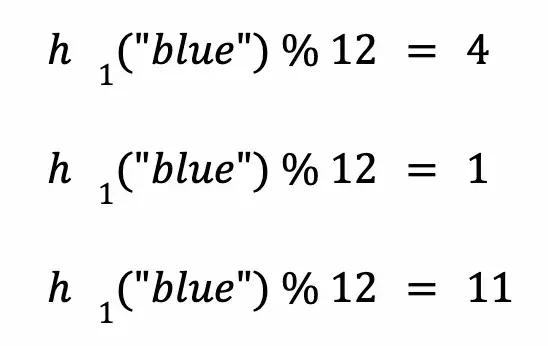
接下来,检查上述索引处的位值:
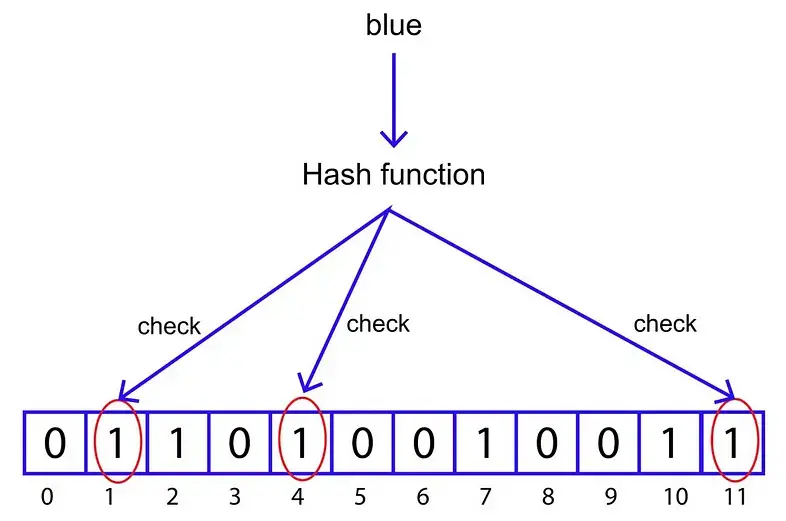
所有三个位置的位都已设置,那么元素“blue”可能出现在过滤器中。
布隆过滤器为什么会出误报?
我们之前提到布隆过滤器有时会给出误报结果。这就是为什么如果布隆过滤器在检查元素是否存在时给出肯定结果,我们只能说元素“可能”存在于集合中。为什么这样?为什么结果不是 100% 准确?
让我们用一个例子来证明一下。
布隆过滤器中有“white”和“blue”两个元素时,状态如下:

让我们检查一下过滤器中是否存在“black”。对“black”进行哈希和取模,如下:
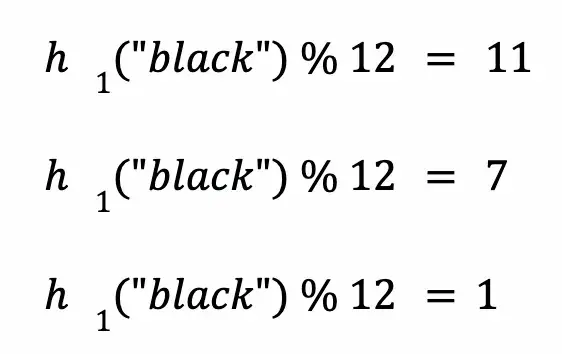
接下来,检查布隆过滤器中索引 11、7 和 1 处的内容。
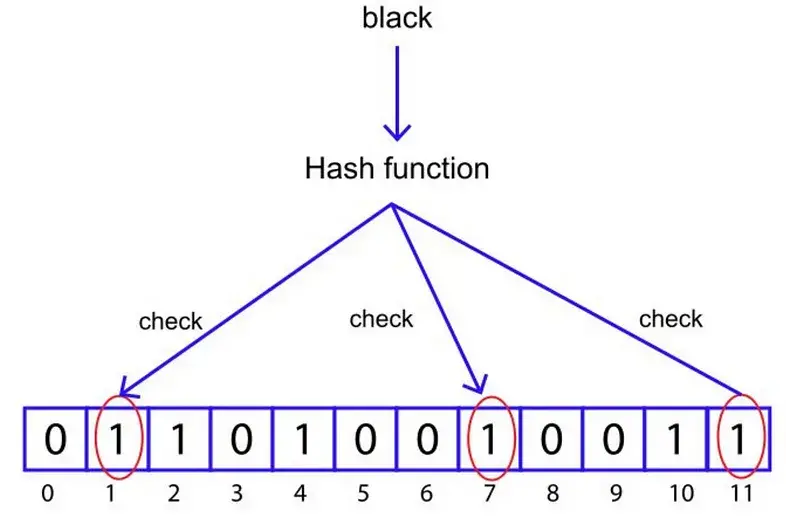
可以看到,所有三个索引处的位均是1。所以布隆过滤器告诉我们集合中可能存在“black”。
但是,由于我们只向过滤器添加了“white”和“blue”,我们一开始就知道“black”不存在!因此布隆过滤器在这种情况下给出了“误报”。
产生误报的过程是这样的:当“white”被添加到过滤器时,索引 7 的位被设置,而当“blue”被添加到过滤器时,索引 1 和 11 的位被设置。现在,当算法看到 11、7 和 1 的位已设置时,它判断“black”可能在过滤器中。
减少误报
如果应用程序需要较低的误报概率,可以通过一些方法来控制它。增加位数组的大小和散列函数的数量可以提高结果的效率并降低误报的概率。
然而,增加哈希函数的数量也会增加布隆过滤器的插入和查找操作的延迟。布隆过滤器的时间复杂度为 O(k),其中 k 是涉及的哈希函数的数量。
布隆过滤器的应用
作为一种可以快速检查元素成员关系且节省空间的数据结构,布隆过滤器具有众多应用。这里有些例子:
- 缓存系统:在缓存系统中,布隆过滤器可以用来快速判断某个对象是否存在于缓存中,从而避免查询数据库或外部服务。
- 网络爬虫:在网络爬虫中,布隆过滤器可以用来过滤已经抓取过的URL,从而避免重复抓取。
- 反垃圾邮件:在反垃圾邮件系统中,布隆过滤器可以用来过滤已知的垃圾邮件地址,从而避免将邮件发送到这些地址。
- 分布式系统:在分布式系统中,布隆过滤器可以用来维护分布式哈希表的键值对,从而避免向所有节点广播查询请求。
- 数据库优化:在数据库中,布隆过滤器可以用来加速模糊查询,例如在大型电话号码列表中查找以特定数字开头的号码。
结论
到现在为止,希望你能更好地理解什么是简单的布隆过滤器、它是如何工作的,以及关于如何将其应用于现实生活用例的一些想法。基本设计可能会有所不同,具体取决于应用程序的要求。例如,计数布隆过滤器可以在需要删除元素的应用程序中实现。























