概述
Facebook Velox 是一个针对 SQL 运行时的 C++ 库,旨在统一 Facebook 各种计算流,包括 Spark 和 Presto,使用推的模式、支持向量计算。
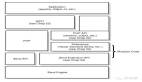
Velox 接受一棵优化过的 PlanNode Tree,然后将其切成一个个的线性的 Pipeline,Task 负责这个转变过程,每个 Task 针对一个 PlanTree Segment。大多数算子是一对一翻译的,但是有一些特殊的算子,通常出现在多个 Pipeline 的切口处,通常来说,这些切口对应计划树的分叉处,如 HashJoinNode,CrossJoinNode, MergeJoinNode ,通常会翻译成 XXProbe 和 XXBuild。但也有一些例外,比如 LocalPartitionNode 和 LocalMergeNode 。

逻辑计划翻译成物理计划,可调整 Pipeline 并发度
为了提高执行的并行度,Velox 引入了 LocalPartitionNode 节点,可以将一个 Pipeline 进行多线程(每个线程一个实例)并行运行,并且互斥的消费数据。其中每个实例称为 Driver。该算子在输入计划树里并没有分叉(即没有多个 source),但在翻译成物理算子时,会在此节点处进行切开,并在切口前后改变执行的并行度,对应的物理算子是LocalPartition 和 LocalExchange。

调整并发度算子,一个逻辑算子翻译成两个物理算子
还有一个特殊节点,称为 LocalMergeNode,该对输入有要求:必须有序,然后会进行单线程的归并排序,从而使输出全局有序。也因此,由其而切开的消费 Pipeline 一定是单 Driver 的。翻译成算子,对应两个 CallbackSink 和 LocalMerge。

Merge 算子,也是一种逻辑翻译成两种物理算子
总结一下,上述五个 PlanNode,HashJoinNode,CrossJoinNode, MergeJoinNode ,LocalPartitionNode ,LocalMergeNode 在翻译时会造成切口,即将逻辑 PlanTree 切成多个物理 Pipeline,因此在切口处会将一个逻辑算子翻译成多个物理算子,分到不同 Pipeline 上。每个 Pipeline 会有一个从 0 开始的编号:Pipeline ID,是全局粒度的。
并且,可以由 LocalPartitionNode 来按需改变每个 Pipeline 并行度,其中 Pipeline 的每个线程由一个 Driver 来执行。每个 Driver 也有一个从 0 开始的编号:Driver ID,是 Pipeline 粒度的。
其他 PlanNode 到算子的翻译基本都是一对一的,感兴趣的可以看官方文档的这个页面:Plan Nodes and Operators。
下面展开一些细节。
Splits
Velox 允许应用层(即 Velox 的使用方)以 Splits (每个算子的输入片段称为 Split)的方式给 Pipeline 喂数据,可以流式的喂,因此有两个 API:
- Task::addSplit(planNodeId, split) :喂一份数据给 Velox
- Task::noMoreSplits() :通知 Velox 我喂完了。
Velox 会使用一个队列在缓存这些 Splits 数据。在数据喂完之前的任意一个时刻,Pipeline 的叶子算子(对的,外部喂数据只能发生在叶子节点,如 TableScan,Exchange 和 MergeExchange)都可以从队列中取数据,对应 API 是 Task::getSplitOrFuture(planNodeId) ,返回值有两种:
- 如果队列中有数据,则返回一个 Split
- 如果队列中无数据,但还没有收到喂完的信号,则返回一个 Future (类似于一个欠条,之后有数据之后,会凭该欠条兑付)。

Task 是 PlanTree Segment 执行单位,可以通过 Splits 方式流式喂数据
Join Bridges and Barriers
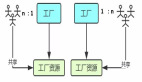
Join (HashJoinNode 和 CrossJoinNode)会翻译成 XXProbe 和 XXBuild 两个算子,并且通过一个共享的 Bridge 来沟通数据,两侧 Pipeline 都可以通过 Task::getHashJoinBridge() 函数来根据 PlanNodeId 获取该共享的 Bridge。
为了提高 build 速度,build 侧 Pipeline 通常使用多个 Driver 并发执行。但由于只有一个 Bridge,每个 Driver 在结束时可以调用 Task::allPeersFinished() (内部是使用一个 BarrierState 的结构来实现的)来判断自己是否为最后一个 Driver,如果是,则将所有 Driver 的输出进行合并后送到 Bridge。
当然,在 RIGHT and FULL OUTER join 情况下,Probe 侧也需要将没有 match 上的数据喂给 Bridge,此时也需要由最后一个 Driver 来负责这件事,于是同样需要调用 Task::allPeersFinished() 函数。

使用 Bridge 对 Join 两侧 Pipeline 进行数据桥接(Build->Probe)
下面来详细看下 Join 类算子的切分细节。以 HashJoin 为例,Task 在切分 PlanTree 时,会将逻辑上的一个 HashJoin 算子,转化成物理上的一对算子:HashProbe 和 HashJoin,并且使用异步机制进行通知:在 HashJoin 完成后,通知 HashProbe 所在 Pipeline 继续执行,在此之前,后者是阻塞等待的。

Join 两侧 Pipeline 是可以调整并发度的
如上图,每个 Pipeline 在实例化(逻辑 PlanNode 转物理 Operator)的时候,可以生成多份,进行并发执行,互斥的消费数据。并且,每个 Pipeline 的并行粒度可以不一样,如上图 Probe Pipeline 实例化了两份,而 Build Pipeline 实例化了三份。并且,Build Pipeline 组中最后一个运行完的 Pipeline 负责将数据通过 Bridge 发送给 Probe Pipeline。
Exchange Clients
Velox 使用 Exchange Clients 来获取远程 worker 的数据。分两个步骤:
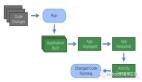
第一步,Pipeline 中第一个 Driver (driverId == 0) 的 Exchange 算子从 Task 中获取一个 Split,并且初始化一个共享 Exchange Client。
第二步,Exchange Client 会为上游每个 Task 构造一个 Exchange Source,并行的拉取每个上游 Task 同一个 Partition (图中是 Partition-15)数据,然后将其放在 Client 的队列 Queue 中。Exchange 的每个 Driver 都会去队列中拉取这些数据。
如何从上游 Task 拉取数据的逻辑,需要由用户自定义实现 ExchangeSource 和 ExchangeSource::Factory 。每个 ExchangeSource 接受一个上游 Task 的字符串 ID、Partition 编号和一个队列作为参数。然后会从上游 Task 中拉取该 Partition 的数据,并且放到队列中。

向上游 Task 远程(跨进程)拉取数据,也叫 MaterializePage
Local Exchange Queues
Local exchange 用于在一个 Task 内部调整数据并发度,会被翻译成两个物理算子:LocalPartition 和 LocalExchange。其中,LocalPartition 在生产侧 Pipeline,LocalExchange 在消费侧 Pipeline。
中间通过 LocalExchangeQueues 来沟通生产者和消费者,这些队列在 Task 类中。对于每个消费者(也即 LocalExchange 侧 Driver)Task 都会构建一个 LocalExchangeQueue 队列;每个生产者 (LocalPartition)可以访问所有队列。在产生一条数据是,会对其按照某种方式进行 Partition,然后写到对应队列中。这个过程类似于 MapReduce 中的 Shuffle 阶段。

本地改变并发度时,使用一个队列进行数据沟通
具体来说,Local Exchange 可以有几种方式改变并行度。如一改多、多改一。多改一,典型的例子如,并行 sort:先切成多个分片每个分片分别 sort,后通过 Local Exchange 进行 merge sort。不仅单个 Pipeline 的多个 Driver 在进行数据合并时可以用 Local Exchange,多个 Pipeline 的合并也可以用 Local Exchange,不妨称之为多并一。典型例子有,Union All,将多个数据集合并起来。

多改一

多并一
一改多通常用在,在经历了某些必须使用单线程的算子后(比如一些 Shuffle 算子),重新对数据分片提高并发度,使用多线程运行。

一改多
Local Merge Sources
LocalMerge 算子和 LocalExchange 算子类似,但对并发数和输入都有限定。其所在 Pipeline 只会单线程运行,但会接受多线程运行的 Pipeline 的输入。并且要求所有输入有序,然后将输入进行归并,保证输出是有序的。
LocalMerge 算子通过 Task::getLocalMergeSources() 来获取所有待 Merge 的 sources。因此,每个 LocalMergeNode 会初始化给定并发数个 LocalMergeSource。
Merge Join Sources
MergeJoin 算子提供了某种接受右侧输入的方法。Task 会在右侧 Pipeline 增加一个 CallbackSink 算子,来汇集数据。左侧算子可以通过 Task::getMergeJoinSource() 接口来获取该 CallbackSink 的输出。
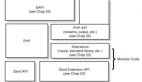
扩展性
Velox 允许用户自定义 PlanNode 和 Operator,以及 Join 相关的 Operator 和 Bridge。自定义 Operator 可以访问 task 中的 splits 并使用 barriers。
但 Exchange clients, local exchange queues 和 local merge sources、 merge join sources 等状态由于不是通用的,因此访问不了。
总结
小节一下,Task 负责将由 PlanNode 组成的 PlanTree 翻译成由 Operator 组成的 Pipeline,并且对 Pipeline 进行并发运行。在此期间,Task 会维护 Operator 间的共享状态、协调 Operator 间的运行依赖。这些共享状态包括:
- Splits
- Join bridges and barriers
- Exchange clients
- Local exchange queues
- Local merge sources
- Merge join sources
上述的每个状态都是和特定 PlanNode 关联的(即不是全局范围的,而是和 PlanNode 绑定的),因此 Opeator 需要使用 PlanNodeID 来访问相关状态。前两个状态是所有算子都有的,因此自定义算子可以访问到,后几个状态是某些算子特有的,因此自定义算子访问不到。