想了解如何在 Kubernetes 上自动扩展您的 Kinesis Data Streams 消费者应用程序,以便您可以节省成本并提高资源效率?该博客提供了有关如何做到这一点的分步指南。
通过利用 Kubernetes 自动扩展 Kinesis 消费者应用程序,您可以受益于其内置功能,例如 Horizontal Pod Autoscaler。
什么是 Amazon Kinesis 和 Kinesis Data Streams?
Amazon Kinesis是一个用于实时数据处理、摄取和分析的平台。Kinesis Data Streams是一种无服务器流数据服务(Kinesis 流数据平台的一部分,还有Kinesis Data Firehose、Kinesis Video Streams和Kinesis Data Analytics。
Kinesis Data Streams 可以弹性扩展并持续适应数据摄取率和流消费率的变化。它可用于构建实时数据分析应用程序、实时仪表板和实时数据管道。
让我们首先概述 Kinesis Data Streams 的一些关键概念。
Kinesis Data Streams:高级架构
- Kinesis 数据流是一组分片。每个分片都有一系列数据记录。
- 生产者不断将数据推送到 Kinesis Data Streams,消费者实时处理数据。
- 分区 键用于按流中的分片对数据进行分组。
- Kinesis Data Streams 将属于一个流的数据记录分成多个分片。
- 它使用与每个数据记录关联的分区键来确定给定数据记录属于哪个分片。
- 消费者从 Amazon Kinesis Data Streams 获取记录,对其进行处理,并将结果存储在 Amazon DynamoDB、Amazon Redshift、Amazon S3 等中。
- 这些消费者也称为 Amazon Kinesis Data Streams 应用程序。
- 开发可以处理来自 KDS 数据流的数据的自定义消费者应用程序的方法之一是使用Kinesis Client Library ( KCL)。
Kinesis 消费者应用程序如何横向扩展?
Kinesis Client Library 确保有一个记录处理器为每个分片运行并处理来自该分片的数据。KCL通过处理与分布式计算和可扩展性相关的许多复杂任务,帮助您使用和处理来自 Kinesis 数据流的数据。它连接到数据流,枚举数据流中的分片,并使用租约来协调分片与其消费者应用程序的关联。
记录处理器为其管理的每个分片实例化。KCL从数据流中拉取数据记录,将记录推送到相应的记录处理器,检查点处理记录。更重要的是,当工作实例计数发生变化或数据流重新分片(分片被拆分或合并)时,它会平衡分片-工作关联(租约)。这意味着您可以通过简单地添加更多实例来扩展您的 Kinesis Data Streams 应用程序,因为KCL它将自动平衡实例之间的分片。
但是,当负载增加时,您仍然需要一种方法来扩展您的应用程序。当然,您可以手动执行此操作或构建自定义解决方案来完成此操作。
这是Kubernetes 事件驱动的自动缩放(KEDA) 可以提供帮助的地方。是一个基于 Kubernetes 的事件驱动的自动伸缩组件,可以像 Kinesis 一样监控事件源,并根据需要处理的事件数量来KEDA伸缩底层Deployment(和s)。Pod
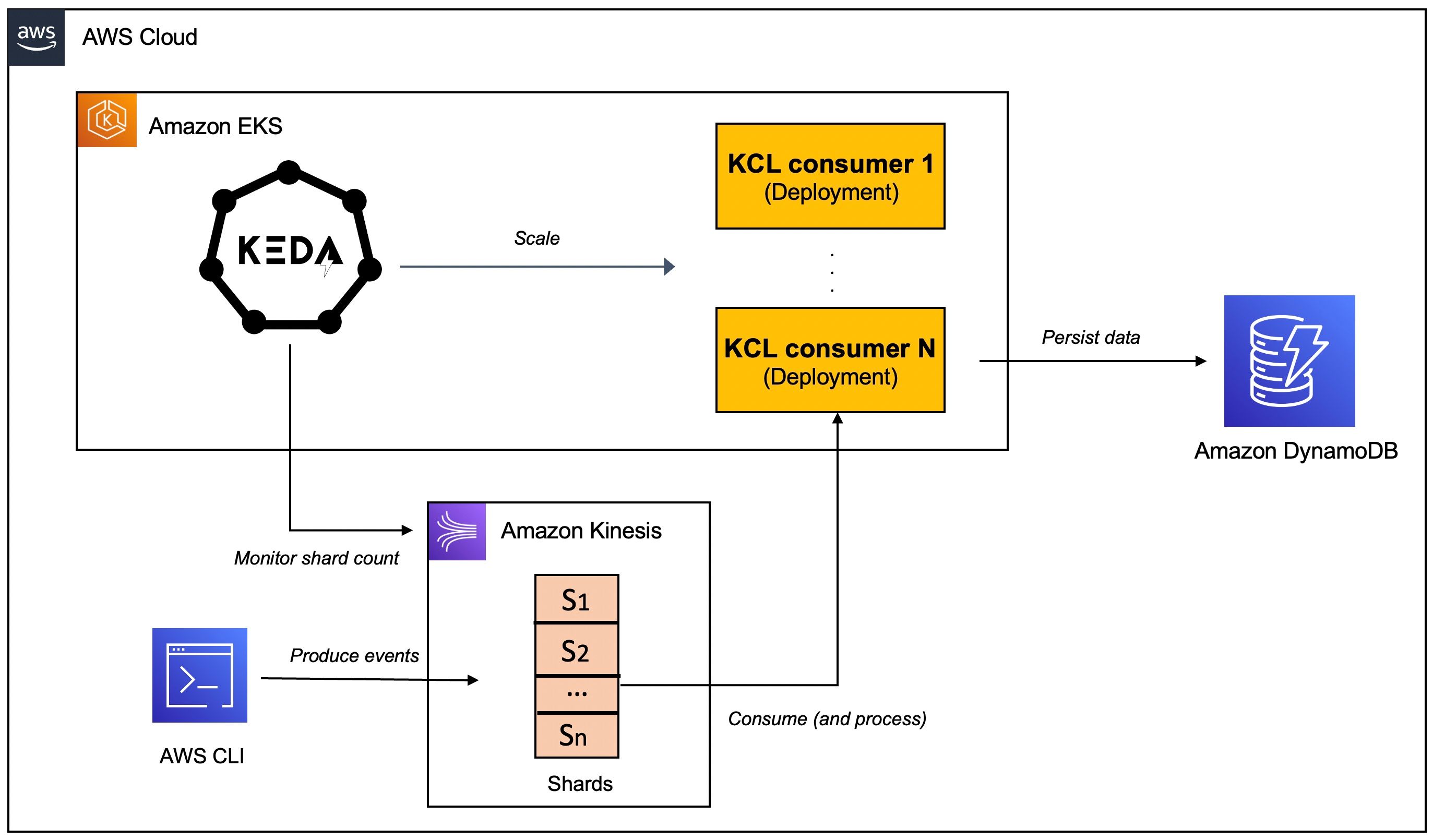
为见证自动缩放的运行,您将使用一个 Java 应用程序,该应用程序使用 Kinesis Client Library ( KCL) 2.x 使用来自 Kinesis Data Stream 的数据。它将部署到Amazon EKS上的 Kubernetes 集群,并使用KEDA. 该应用程序包括ShardRecordProcessor处理来自 Kinesis 流的数据并将其保存到 DynamoDB 表的实现。我们将使用 AWS CLI 为 Kinesis 流生成数据并观察应用程序的扩展。
之前,我们深入了解,这里是KEDA.
什么是科达?
KEDA是一个开源 CNCF 项目,它建立在原生 Kubernetes 原语(例如 Horizontal Pod Autoscaler)之上,可以添加到任何 Kubernetes 集群。以下是其关键组件的高级概述(您可以参考KEDA 文档进行深入研究):
- 该keda-operator-metrics-apiserver组件KEDA充当Kubernetes 指标服务器,为 Horizontal Pod Autoscaler 公开指标
- KEDA Scaler与外部系统(例如 Redis)集成以获取这些指标(例如,列表的长度),以根据需要处理的事件数量驱动 Kubernetes 中任何容器的自动缩放。
- 组件的作用keda-operator是activate和deactivateDeployment;即,缩放到零和从零开始。
您将看到Kinesis Stream KEDA 缩放器正在运行,它根据 AWS Kinesis Stream 的分片数进行缩放。
现在让我们继续本文的实际部分。
先决条件
除了 AWS 账户外,您还需要安装AWS CLI、kubectl、Docker、 Java 11 和Maven。
设置 EKS 集群、创建 DynamoDB 表和 Kinesis 数据流
您可以通过多种方式创建Amazon EKS 集群。我更喜欢使用eksctl CLI,因为它提供了便利。使用以下方法创建 EKS 集群eksctl非常简单:
有关详细信息,请参阅Amazon EKS 入门 – eksctl文档。
创建一个 DynamoDB 表来保存应用程序数据。您可以使用 AWS CLI 通过以下命令创建表:
使用 AWS CLI创建一个包含两个分片的 Kinesis 流:
克隆此 GitHub 存储库并将其更改为正确的目录:
好的,让我们开始吧!
在 EKS 上设置和配置 KEDA
出于本教程的目的,您将使用YAML 文件部署KEDA. 但您也可以使用Helm 图表。
安装KEDA:
验证安装:
配置 IAM 角色
KEDA 操作员和 Kinesis 消费者应用程序需要调用 AWS API。由于两者都将作为 EKS 中的 s 运行Deployment,我们将使用IAM 服务账户角色 (IRSA)来提供必要的权限。
在这种特殊情况下:
- KEDA运算符需要能够获取 Kinesis 流的分片计数:它通过使用DescribeStreamSummaryAPI 来实现。
- 应用程序(具体来说是 KCL 库)需要与 Kinesis 和 DynamoDB 交互:它需要一堆IAM 权限才能这样做。
为 KEDA 操作员配置 IRSA
将您的 AWS 账户 ID 和 OIDC 身份提供商设置为环境变量:
JSON为角色创建一个包含可信实体的文件:
现在,创建 IAM 角色并附加策略(查看policy_kinesis_keda.json文件了解详细信息):
关联 IAM 角色和服务帐户:
您需要重新启动KEDA操作员Deployment才能生效:
为 KCL 消费者应用程序配置 IRSA
首先创建一个 Kubernetes 服务帐户:
JSON为角色创建一个包含可信实体的文件:
现在,创建 IAM 角色并附加策略(查看policy.json文件了解详细信息):
关联 IAM 角色和服务帐户:
核心基础设施现已准备就绪。让我们准备并部署消费者应用程序。
将 KCL 消费者应用程序部署到 EKS
您首先需要构建 Docker 镜像并将其推送到Amazon Elastic Container Registry (ECR)(有关Dockerfile详细信息,请参阅 )。
构建 Docker 镜像并将其推送到 ECR
部署消费者应用程序
更新consumer.yaml以包含您刚刚推送到 ECR 的 Docker 映像。清单的其余部分保持不变:
创建Deployment:
KCL 应用程序自动缩放在 KEDA 中的应用
现在您已经部署了消费者应用程序,KCL库应该开始行动了。它要做的第一件事是在 DynamoDB 中创建一个“控制表”——这应该与 KCL 应用程序的名称相同(在本例中为 )kinesis-keda-demo。
进行初始协调和创建表可能需要几分钟时间。您可以检查消费者应用程序的日志以跟踪进度。
租约分配完成后,检查表并记下leaseOwner属性:
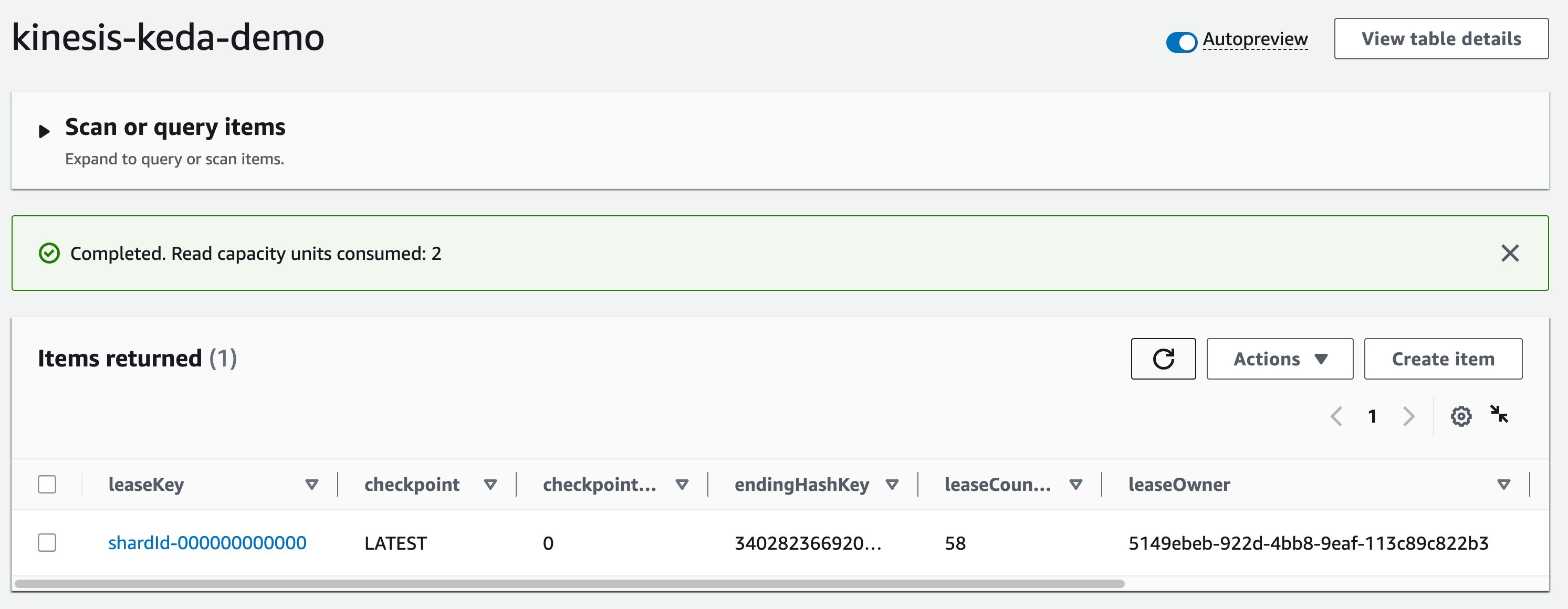
现在,让我们使用 AWS CLI 将一些数据发送到 Kinesis 流。
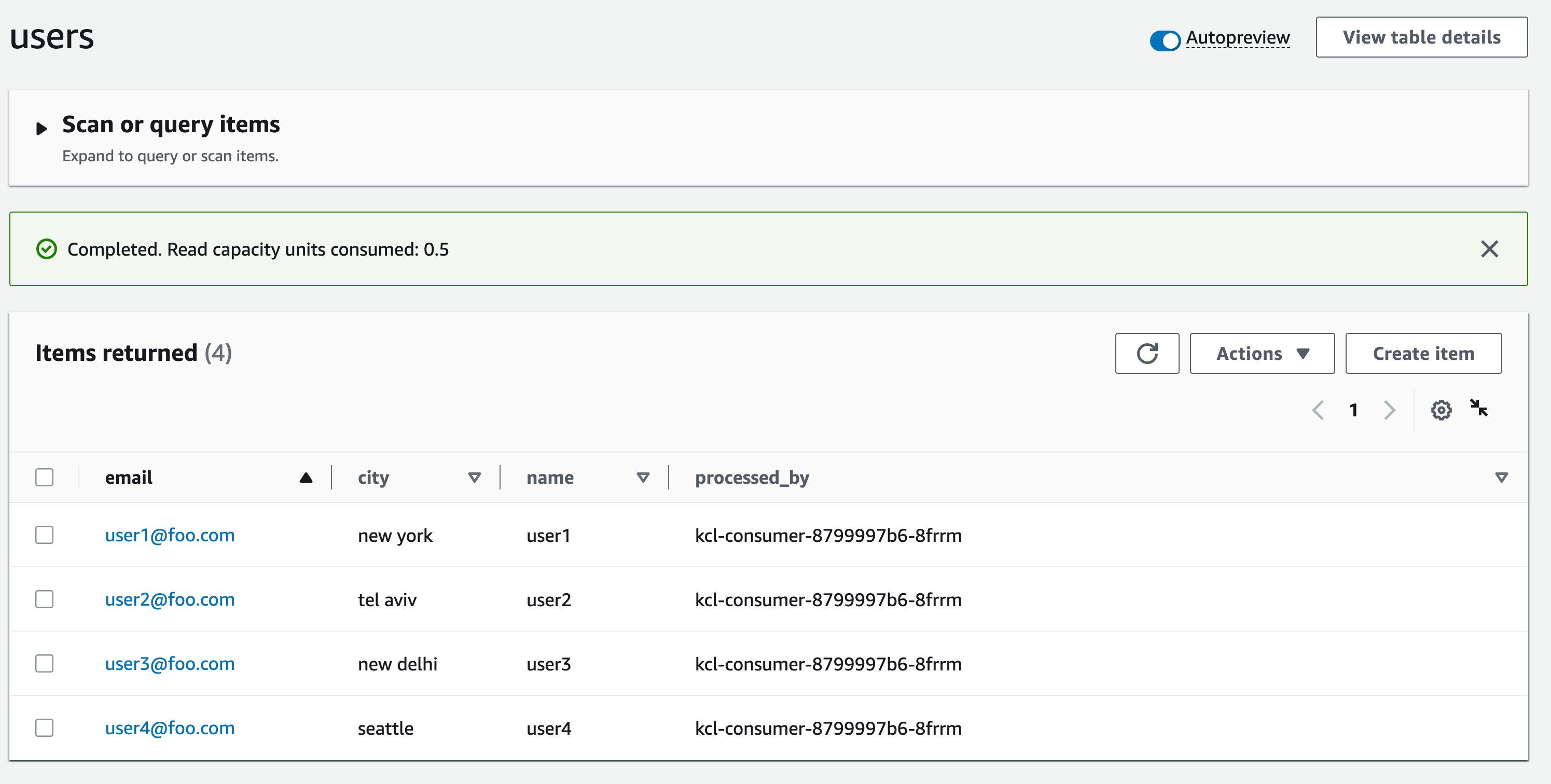
KCL 应用程序将每条记录保存到目标DynamoDB表(在本例中已命名users)。您可以检查表格以验证记录。
注意到processed_by属性的值了吗?它与 KCL 消费者相同Pod。这将使我们更容易验证端到端的自动缩放过程。
为 Kinesis 创建 KEDA 定标器
这是ScaledObject定义。请注意,它的目标是kcl-consumer Deployment(我们刚刚创建的那个)并且shardCount设置为1:
创建KEDAKinesis 缩放器:
验证 KCL 应用程序自动缩放
Pod我们从我们的一个 KCL 应用程序开始。但是,多亏了KEDA,我们现在应该看到第二次Pod出现了。
我们的应用程序能够自动缩放到两个,因为我们在定义中Pods指定了。这意味着Kinesis 流中的每个分片都会有一个。shardCount: "1"ScaledObjectPod
检查kinesis-keda-demo控制表DynamoDB:您应该看到leaseOwner.
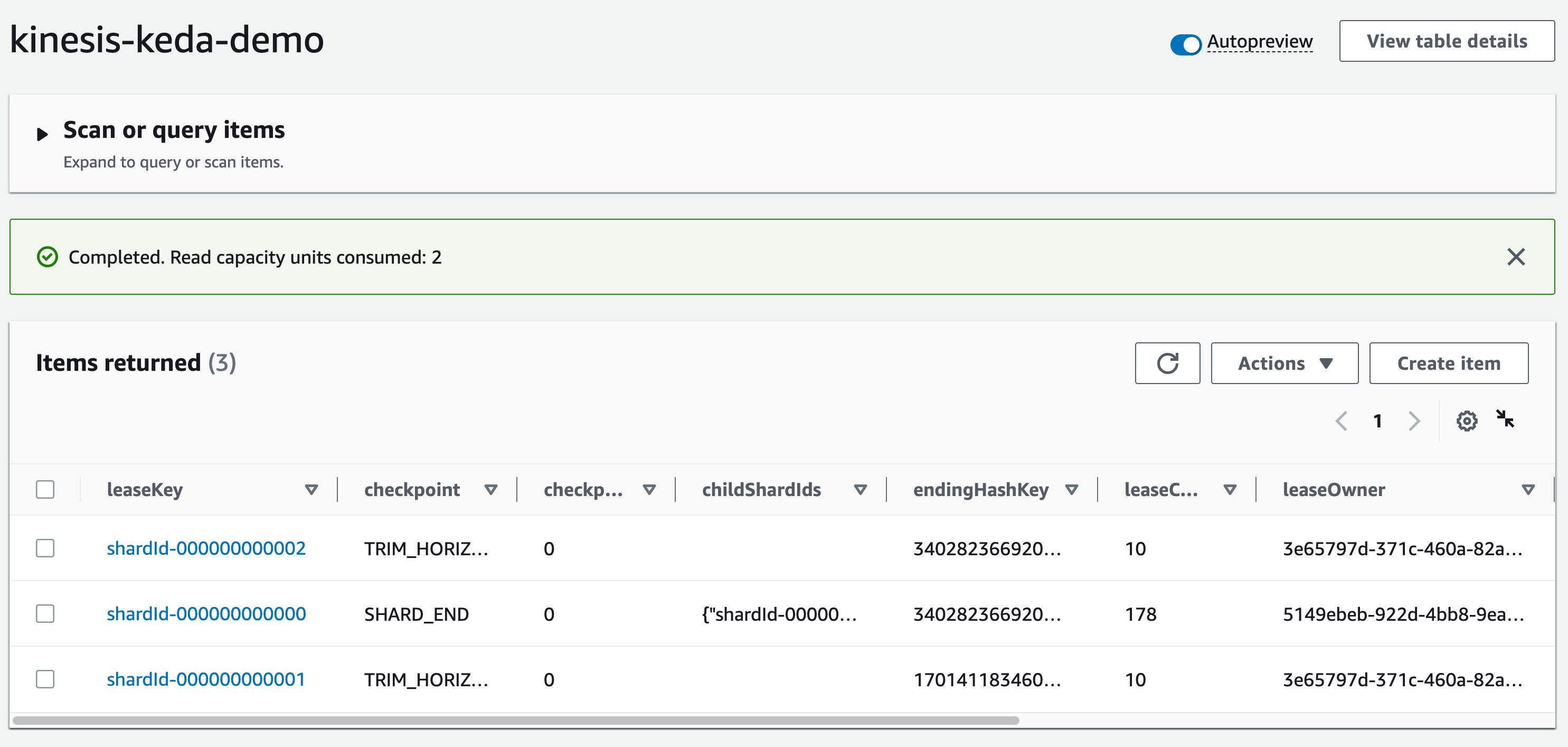
让我们向 Kinesis 流发送更多数据。
验证属性的值processed_by。由于我们已经扩展到两个Pods,每个记录的值应该不同,因为每个记录都Pod将处理来自 Kinesis 流的记录子集。
增加 Kinesis 流容量
让我们将分片数量从两个扩展到三个,并继续监控KCL应用程序的自动扩展。
一旦 Kinesis 重新分片完成,KEDA缩放器将开始行动并将 KCL 应用程序扩展到三个Pods。
kinesis-keda-demo和之前一样,在控制表中确认Kinesis shard lease已经更新DynamoDB。检查leaseOwner属性。
继续向 Kinesis 流发送更多数据。正如预期的那样,Pods 将共享记录处理,这将反映在表processed_by中的属性中users。
缩小
到目前为止,我们只在一个方向上进行了扩展。当我们减少 Kinesis 流的分片容量时会发生什么?亲自尝试一下:将分片数从三个减少到两个,看看 KCL 应用程序会发生什么。
验证端到端解决方案后,您应该清理资源以避免产生任何额外费用。
删除资源
删除 EKS 集群、Kinesis 流和 DynamoDB 表。
结论
在本文中,您学习了如何使用KEDA自动缩放KCL使用来自 Kinesis 流的数据的应用程序。
您可以根据您的应用要求配置 KEDA 定标器。例如,您可以将Kinesis 流中的每三个分片设置为shardCount一个3。Pod然而,如果你想维护一个一对一的映射,你可以设置为shardCount并1会KCL处理分布式协调和租约分配,从而确保每个Pod记录处理器都有一个实例。这是一种有效的方法,可让您扩展 Kinesis 流处理管道以满足应用程序的需求。