一、背景
Kafka中的实时数据是以Topic的概念进行分类存储,而Topic的数据是有一定时效性的,比如保存24小时、36小时、48小时等。
二、内容
2.1 案例分析
这里以i视频和vivo短视频实时数据为例,之前存在这样的协作问题:
数据上游内容方提供实时Topic(存放i视频和vivo短视频相关实时数据),数据侧对实时数据进行逻辑处理后,发送给下游工程去建库实时索引,当任务执行一段时间后,工程侧建索引偶尔会提出数据没有发送过去的Case,前期由于没有对数据做存储,在定位问题的时候会比较麻烦,经常需求查看实时日志,需要花费很长的时间来分析这些Case是出现在哪个环节。
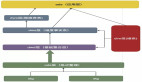
为了解决这个问题,我们可以将实时Topic中的数据,在发送给其他Topic的时候,添加跟踪机制,进行数据分流,Sink到存储介质(比如HDFS、Hive等)。这里,我们选择使用Hive来进行存储,主要是查询方便,支持SQL来快速查询。如下图所示:

在实现优化后的方案时,有两种方式可以实现跟踪机制,它们分别是Flink SQL写Hive、Flink DataStream写Hive。接下来,分别对这两种实现方案进行介绍和实践。
2.2 方案一:Flink SQL写Hive
这种方式比较直接,可以在Flink任务里面直接操作实时Topic数据后,将消费后的数据进行分流跟踪,作为日志记录写入到Hive表中,具体实现步骤如下:
- 构造Hive Catalog;
- 创建Hive表;
- 写入实时数据到Hive表。
2.2.1 构造Hive Catalog
在构造Hive Catalog时,需要初始化Hive的相关信息,部分代码片段如下所示:
// 设置执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env,settings);
// 构造 Hive Catalog 名称
String name = "video-hive-catalog";
// 初始化数据库名
String defaultDatabase = "comsearch";
// Hive 配置文件路径地址
String hiveConfDir = "/appcom/hive/conf";
// Hive 版本号
String version = "3.1.2";
// 实例化一个 HiveCatalog 对象
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version);
// 注册HiveCatalog
tEnv.registerCatalog(name, hive);
// 设定当前 HiveCatalog
tEnv.useCatalog(name);
// 设置执行SQL为Hive
tEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
// 使用数据库
tEnv.useDatabase("db1");在以上代码中,我们首先设置了 Flink 的执行环境和表环境,然后创建了一个 HiveCatalog,并将其注册到表环境中。
2.2.2 创建Hive表
如果Hive表不存在,可以通过在程序中执行建表语句,具体SQL见表语句代码如下所示:
-- 创建表语句
tEnv.executeSql("CREATE TABLE IF NOT EXISTS TABLE `xxx_table`(
`content_id` string,
`status` int)
PARTITIONED BY (
`dt` string,
`h` string,
`m` string)
stored as ORC
TBLPROPERTIES (
'auto-compaction'='true',
'sink.partition-commit.policy.kind'='metastore,success-file',
'partition.time-extractor.timestamp-pattern'='$dt $h:$m:00'
)")在创建Hive表时我们使用了IF NOT EXISTS关键字,如果Hive中该表不存在会自动在Hive上创建,也可以提前在Hive中创建好该表,Flink SQL中就无需再执行建表SQL,因为用了Hive的Catalog,Flink SQL运行时会找到表。这里,我们设置了auto-compaction属性为true,用来使小文件自动合并,1.12版的新特性,解决了实时写Hive产生的小文件问题。同时,指定metastore值是专门用于写入Hive的,也需要指定success-file值,这样CheckPoint触发完数据写入磁盘后会创建_SUCCESS文件以及Hive metastore上创建元数据,这样Hive才能够对这些写入的数据可查。
2.2.3 写入实时数据到Hive表
在准备完成2.2.1和2.2.2中的步骤后,接下来就可以在Flink任务中通过SQL来对实时数据进行操作了,具体实现代码片段如下所示:
// 编写业务SQL
String insertSql = "insert into xxx_table SELECT content_id, status, " +
" DATE_FORMAT(ts, 'yyyy-MM-dd'), DATE_FORMAT(ts, 'HH'), DATE_FORMAT(ts, 'mm') FROM xxx_rt";
// 执行 Hive SQL
tEnv.executeSql(insertSql);
// 执行任务
env.execute();将消费后的数据进行分类,编写业务SQL语句,将消费的数据作为日志记录,发送到Hive表进行存储,这样Kafka中的实时数据就存储到Hive了,方便使用Hive来对Kafka数据进行即席分析。
2.2.4 避坑技巧
使用这种方式在处理的过程中,如果配置使用的是EventTime,在程序中配置'sink.partition-commit.trigger'='partition-time',最后会出现无法提交分区的情况。经过对源代码PartitionTimeCommitTigger的分析,找到了出现这种异常情况的原因。
我们可以通过看
org.apache.flink.table.filesystem.stream.PartitionTimeCommitTigger#committablePartitionsorg.apache.flink.table.filesystem.stream.PartitionTimeCommitTigger#committablePartitions
中的一个函数,来说明具体的问题,部分源代码片段如下:
// PartitionTimeCommitTigger源代码函数代码片段
@Override
public List<String> committablePartitions(long checkpointId) {
if (!watermarks.containsKey(checkpointId)) {
throw new IllegalArgumentException(String.format(
"Checkpoint(%d) has not been snapshot. The watermark information is: %s.",
checkpointId, watermarks));
}
long watermark = watermarks.get(checkpointId);
watermarks.headMap(checkpointId, true).clear();
List<String> needCommit = new ArrayList<>();
Iterator<String> iter = pendingPartitions.iterator();
while (iter.hasNext()) {
String partition = iter.next();
// 通过分区的值来获取分区的时间
LocalDateTime partTime = extractor.extract(
partitionKeys, extractPartitionValues(new Path(partition)));
// 判断水印是否大于分区创建时间+延迟时间
if (watermark > toMills(partTime) + commitDelay) {
needCommit.add(partition);
iter.remove();
}
}
return needCommit;
}通过分析上述代码片段,我们可以知道系统通过分区值来抽取相应的分区来创建时间,然后进行比对,比如我们设置的时间 pattern 是 '$dt $h:$m:00' , 某一时刻我们正在往 /2022-02-26/18/20/ 这个分区下写数据,那么程序根据分区值,得到的 pattern 将会是2022-02-26 18:20:00,这个值在SQL中是根据 DATA_FORMAT 函数获取的。
而这个值是带有时区的,比如我们的时区设置为东八区,2022-02-26 18:20:00这个时间是东八区的时间,换成标准 UTC 时间是减去8个小时,也就是2022-02-26 10:20:00,而在源代码中的 toMills 函数在处理这个东八区的时间时,并没有对时区进行处理,把这个其实应该是东八区的时间当做了 UTC 时间来处理,这样计算出来的值就比实际值大8小时,导致一直没有触发分区的提交。
如果我们在数据源中构造的分区是 UTC 时间,也就是不带分区的时间,那么这个逻辑就是没有问题的,但是这样又不符合我们的实际情况,比如对于分区2022-02-26 18:20:00,我希望我的分区肯定是东八区的时间,而不是比东八区小8个小时的UTC时间2022-02-26 10:20:00。
在明白了原因之后,我们就可以针对上述异常情况进行优化我们的实现方案,比如自定义一个分区类、或者修改缺省的时间分区类。比如,我们使用TimeZoneTableFunction类来实现一个自定义时区,部分参考代码片段如下:
public class CustomTimeZoneTableFunction implements TimeZoneTableFunction {
private transient DateTimeFormatter formatter;
private String timeZoneId;
public CustomTimeZoneTableFunction(String timeZoneId) {
this.timeZoneId = timeZoneId;
}
@Override
public void open(FunctionContext context) throws Exception {
// 初始化 DateTimeFormatter 对象
formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:00");
formatter = formatter.withZone(ZoneId.of(timeZoneId));
}
@Override
public void eval(Long timestamp, Collector<TimestampWithTimeZone> out) {
// 将时间戳转换为 LocalDateTime 对象
LocalDateTime localDateTime = LocalDateTime.ofInstant(Instant.ofEpochMilli(timestamp), ZoneOffset.UTC);
// 将 LocalDateTime 对象转换为指定时区下的 LocalDateTime 对象
LocalDateTime targetDateTime = localDateTime.atZone(ZoneId.of(timeZoneId)).toLocalDateTime();
// 将 LocalDateTime 对象转换为 TimestampWithTimeZone 对象,并输出到下游
out.collect(TimestampWithTimeZone.fromLocalDateTime(targetDateTime, ZoneId.of(timeZoneId)));
}
}2.3 方案二:Flink DataStream写Hive
在一些特殊的场景下,Flink SQL如果无法实现我们复杂的业务需求,那么我们可以考虑使用Flink DataStream写Hive这种实现方案。比如如下业务场景,现在需要实现这样一个业务需求,内容方将实时数据写入到Kafka消息队列中,然后由数据侧通过Flink任务消费内容方提供的数据源,接着对消费的数据进行分流处理(这里的步骤和Flink SQL写Hive的步骤类似),每分钟进行存储到HDFS(MapReduce任务需要计算和重跑HDFS数据),然后通过MapReduce任务将HDFS上的这些日志数据生成Hive所需要格式,最后将这些Hive格式数据文件加载到Hive表中。实现Kafka数据到Hive的即席分析功能,具体实现流程细节如下图所示:

具体核心实现步骤如下:
- 消费内容方Topic实时数据;
- 生成数据预处理策略;
- 加载数据;
- 使用Hive SQL对Kafka数据进行即席分析。
2.3.1 消费内容方Topic实时数据
编写消费Topic的Flink代码,这里不对Topic中的数据做逻辑处理,在后面统一交给MapReduce来做数据预处理,直接消费并存储到HDFS上。具体实现代码如下所示:
public class Kafka2Hdfs {
public static void main(String[] args) {
// 判断参数是否有效
if (args.length != 3) {
LOG.error("kafka(server01:9092), hdfs(hdfs://cluster01/data/), flink(parallelism=2) must be exist.");
return;
}
// 初始化Kafka连接地址和HDFS存储地址以及Flink并行度
String bootStrapServer = args[0];
String hdfsPath = args[1];
int parallelism = Integer.parseInt(args[2]);
// 实例化一个Flink任务对象
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(5000);
env.setParallelism(parallelism);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// Flink消费Topic中的数据
DataStream<String> transction = env.addSource(new FlinkKafkaConsumer010<>("test_bll_topic", new SimpleStringSchema(), configByKafkaServer(bootStrapServer)));
// 实例化一个HDFS存储对象
BucketingSink<String> sink = new BucketingSink<>(hdfsPath);
// 自定义存储到HDFS上的文件名,用小时和分钟来命名,方便后面算策略
sink.setBucketer(new DateTimeBucketer<String>("HH-mm"));
// 设置存储HDFS的文件大小和存储文件时间频率
sink.setBatchSize(1024 * 1024 * 4);
sink.setBatchRolloverInterval(1000 * 30);
transction.addSink(sink);
env.execute("Kafka2Hdfs");
}
// 初始化Kafka对象连接信息
private static Object configByKafkaServer(String bootStrapServer) {
Properties props = new Properties();
props.setProperty("bootstrap.servers", bootStrapServer);
props.setProperty("group.id", "test_bll_group");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return props;
}
}注意事项:
- 这里我们把时间窗口设置小一些,每30s做一次Checkpoint,如果该批次的时间窗口没有数据过来,就生成一个文件落地到HDFS上;
- 另外,我们重写了Bucketer为DateTimeBucketer,逻辑并不复杂,在原有的方法上加一个年-月-日/时-分的文件生成路径,例如在HDFS上的生成路径:xxxx/2022-02-26/00-00。
具体DateTimeBucketer实现代码如下所示:
public class DateMinuteBucketer implements Bucketer<String> {
private SimpleDateFormat baseFormatDay = new SimpleDateFormat("yyyy-MM-dd");
private SimpleDateFormat baseFormatMin = new SimpleDateFormat("HH-mm");
@Override
public Path getBucketPath(Clock clock, Path basePath, String element) {
return new Path(basePath + "/" + baseFormatDay.format(new Date()) + "/" + baseFormatMin.format(new Date()));
}
}2.3.2 生成数据预处理策略
这里,我们需要对落地到HDFS上的文件进行预处理,处理的逻辑是这样的。比如,现在是2022-02-26 14:00,那么我们需要将当天的13:55,13:56,13:57,13:58,13:59这最近5分钟的数据处理到一起,并加载到Hive的最近5分钟的一个分区里面去。那么,我们需要生成这样一个逻辑策略集合,用HH-mm作为key,与之最近的5个文件作为value,进行数据预处理合并。具体实现代码步骤如下:
- 步骤一:获取小时循环策略;
- 步骤二:获取分钟循环策略;
- 步骤三:判断是否为5分钟的倍数;
- 步骤四:对分钟级别小于10的数字做0补齐(比如9补齐后变成09);
- 步骤五:对小时级别小于10的数字做0补齐(比如1补齐后变成01);
- 步骤六:生成时间范围;
- 步骤七:输出结果。
其中,主要的逻辑是在生成时间范围的过程中,根据小时和分钟数的不同情况,生成不同的时间范围,并输出结果。在生成时间范围时,需要注意前导0的处理,以及特殊情况(如小时为0、分钟为0等)的处理。最后,将生成的时间范围输出即可。
根据上述步骤编写对应的实现代码,生成当天所有日期命名规则,预览部分结果如下:

需要注意的是,如果发生了第二天00:00,那么我们需要用到前一天的00-00=>23-59,23-58,23-57,23-56,23-55这5个文件中的数据来做预处理。
2.3.3 加载数据
在完成2.3.1和2.3.2里面的内容后,接下来,我们可以使用Hive的load命令直接加载HDFS上预处理后的文件,把数据加载到对应的Hive表中,具体实现命令如下:
-- 加载数据到Hive表
load data inpath '<hdfs_path_hfile>' overwrite into table xxx.table partition(day='2022-02-26',hour='14',min='05')2.3.4 即席分析
之后,我们使用Hive SQL来对Kafka数据进行即席分析,示例SQL如下所示:
-- 查询某5分钟分区数据
select * from xxx.table where day='2022-02-26' and hour='14' and min='05'2.4 Flink SQL与 Flink DataStream如何选择
Flink SQL 和 Flink DataStream 都是 Flink 中用于处理数据的核心组件,我们可以根据自己实际的业务场景来选择使用哪一种组件。
Flink SQL 是一种基于 SQL 语言的数据处理引擎,它可以将 SQL 查询语句转换为 Flink 的数据流处理程序。相比于 Flink DataStream,Flink SQL 更加易于使用和维护,同时具有更快的开发速度和更高的代码复用性。Flink SQL 适用于需要快速开发和部署数据处理任务的场景,比如数据仓库、实时报表、数据清洗等。
Flink DataStream API是Flink数据流处理标准API,SQL是Flink后期版本提供的新的数据处理操作接口。SQL的引入为提高了Flink使用的灵活性。可以认为Flink SQL是一种通过字符串来定义数据流处理逻辑的描述语言。
因此,在选择 Flink SQL 和 Flink DataStream 时,需要根据具体的业务需求和数据处理任务的特点来进行选择。如果需要快速开发和部署任务,可以选择使用 Flink SQL;如果需要进行更为深入和定制化的数据处理操作,可以选择使用 Flink DataStream。同时,也可以根据实际情况,结合使用 Flink SQL 和 Flink DataStream 来完成复杂的数据处理任务。
三、 总结
在实际应用中,Kafka实时数据即席查询可以用于多种场景,如实时监控、实时报警、实时统计、实时分析等。具体应用和实践中,需要注意以下几点:
- 数据质量:Kafka实时数据即席查询需要保证数据质量,避免数据重复、丢失或错误等问题,需要进行数据质量监控和调优。
- 系统复杂性:Kafka实时数据即席查询需要涉及到多个系统和组件,包括Kafka、数据处理引擎(比如Flink)、查询引擎(比如Hive)等,需要对系统进行配置和管理,增加了系统的复杂性。
- 安全性:Kafka实时数据即席查询需要加强数据安全性保障,避免数据泄露或数据篡改等安全问题,做好Hive的权限管控。
- 性能优化:Kafka实时数据即席查询需要对系统进行性能优化,包括优化数据处理引擎、查询引擎等,提高系统的性能和效率。