译者 | 朱先忠
审校 | 重楼
简介
最近,我们团队推出了一种称为自动梯度下降(AGD:automatic gradient descent)的优化器,它可以在不使用超参数的情况下训练ImageNet数据集。基于这一优化器算法,可以消除在模型训练时对昂贵且耗时的学习速率调整、学习速率衰减调度器等选项的需求。您可以在链接处找到我们发表的有关此算法的论文。
我与Jeremy Bernstein、Kevin Huang、Navid Azizan和Yisong Yue一起参与了这个项目。您可以参阅Jeremy先生的GitHub代码库以获得一个干净的Pytorch实现,也可以参阅我的GitHub代码库以获得具有更多功能的实验版本。下面的图1总结了我们提出的AGD算法与Adam和SGD两种优化算法之间的对比情况。
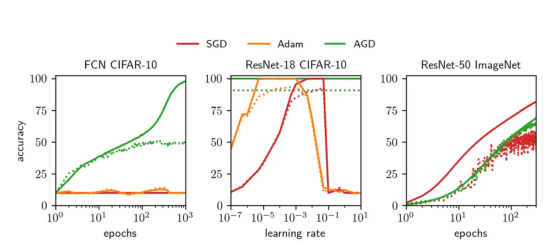
图1:实线显示训练精度,虚线显示测试精度
其中,左图展示的是与我们的方法相反的具有默认超参数的Adam和SGD算法在CIFAR-10数据集上的深度全连接网络(FCN)上不理想的表现。中间图展示的是Adam和SGD算法的学习率网格搜索对比情况。我们所开发的优化器的性能与经过充分调参后的Adam和SGD性能差不多。右图展示了我们所开发的AGD算法将ImageNet数据集训练到相当高的测试精度。
动机
任何训练过深度神经网络的人都可能有过不得不调整模型的学习速率的经历。这样做的目的无处乎:(1)确保训练的最大效率;(2)找到正确的学习率可以显著提高整体模型的泛化应用能力。当然,这个过程也会伴随着开发人员的巨大代价的付出。
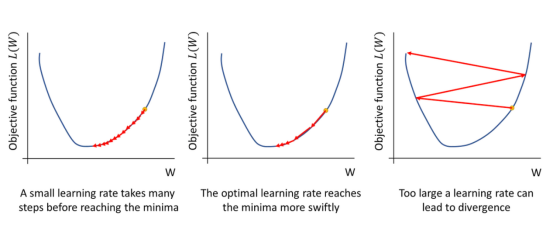
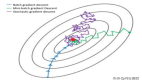
图2:为什么学习率对模型优化非常重要
为了最大限度地提高收敛速度,你总会想尽可能找到最佳学习率:这是很大的一个值!而且,目标函数中的非线性项可能会把你折磨得“死去活来”。
然而,对于SGD算法来说,最佳学习率在很大程度上取决于正在训练的体系结构。找到这个值通常需要一个代价高昂的网格搜索程序,需要涵盖许多数量级内容。此外,还需要选择和调整其他超参数,如动量和学习率衰减调度器。
为此,我们提出了一种称为自动梯度下降(AGD)的优化器,它不需要使用学习率就可以训练大范围的架构和数据集,可以在ImageNet数据集上从基础模型一直扩展训练到ResNet-50这样的复杂模型。这种算法消除了对任何超参数调整的需要(因为此算法不需要分析有效学习率和学习率衰减值),从而节省了计算成本,并大大加快了模型训练的过程。
为什么我们需要超参数呢?
究其原因,一个深度学习系统往往都是由许多相互关联的组件组成:架构、数据、损失函数和梯度等。这些组件的交互方式都是围绕着一种结构进行的;但是,到目前为止,还没有人确切地弄清楚这个结构。所以,我们需要进行大量的调整工作(例如学习率、初始化、调度器等),以确保快速收敛,并避免过度拟合。
然而,尽管完美地描述这些相互作用可以消除优化过程中的所有自由度;但是,目前这些自由度都是通过手动超参数调整来实现的。二阶方法中目前使用Hessian矩阵来表征目标对权重扰动的敏感性,并以这种方式去除自由度——然而,这种方法可能计算密集,因此对于大型模型来说并不实用。
我们团队通过分析这些相互作用的特征,最终找到了AGD优化方法:
- 对于给定的数据和架构,我们根据权重的变化来约束神经网络输出的变化。
- 我们将目标的变化(一次批运算中所有输入的总损失)与神经网络输出的变化联系起来。
- 我们将这些结果结合在一种所谓的多数最小化方法(majorise-minimise approach)中。我们对目标进行多数化——也就是说,我们推导出与目标相切的目标的上界。然后我们可以将这个上限降到最低,因为我们知道这会让我们的算法加快收敛。如图3所示,红色曲线表示目标函数的多数化,蓝色曲线表示目标函数。
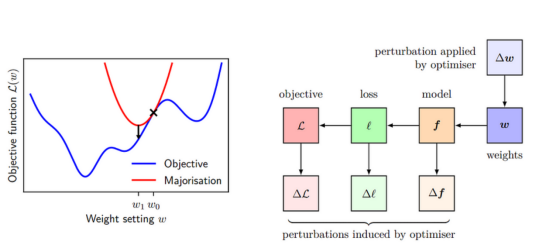
图3:左侧面板显示了多数最小化背后的基本思想
最小化目标函数(蓝色)是通过最小化一系列上限或多数(红色)来实现的。右侧面板显示了权重的变化如何导致函数的变化,进而导致单个数据点的损失的变化,从而导致目标的变化。我们用∆W来约束∆L,并用它来构建我们的多数化。
基于Pytorch框架的AGD算法实现
在本节中,我们将介绍我们所开发的AGD优化算法的所有关键部分基于Pytorch框架的实现代码。相应的草图推导可参考文后的附录A。
参数操作
我们所使用的参数化与传统PyTorch默认值略有不同。AGD算法可以在不借助参数化支持的情况下即可完成;不过,使用参数化可以简化分析过程。对于完全连接的层l,我们使用正交初始化,并进行适当的缩放以便使奇异值具有大小:sqrt((l的输入维度)/(l的输出维度))。
import math
import torch
from torch.nn.init import orthogonal_
def singular_value(p):
sv = math.sqrt(p.shape[0] / p.shape[1])
if p.dim() == 4:
sv /= math.sqrt(p.shape[2] * p.shape[3])
return sv
class AGD:
@torch.no_grad()
def __init__(self, net, gain=1.0):
self.net = net
self.depth = len(list(net.parameters()))
self.gain = gain #用于加速训练的可选用的超参数——在后面的任何实验中并不使用
for p in net.parameters():
if p.dim() == 1: raise Exception("Biases are not supported.")
if p.dim() == 2: orthogonal_(p)
if p.dim() == 4:
for kx in range(p.shape[2]):
for ky in range(p.shape[3]):
orthogonal_(p[:,:,kx,ky])
p *= singular_value(p)在此,我们之所以使用这种规范化,是因为它具有PyTorch默认参数化所没有的优秀特征,包括宽度稳定性、对激活函数中的抗爆炸式增长能力以及促进特征学习。这与Greg Yang和Edward Hu二人开发的muP库相似。
更新操作
这一步可以分成两个单独的部分。第一个是计算eta(η),即“自动学习率”,它实现对所有层的更新进行缩放。注意,Eta对梯度范数有对数依赖性——当梯度很小时,Eta近似为线性(就像标准优化器一样);但是,当它们非常大时,对数会自动执行一种梯度修剪。
@torch.no_grad()
def step(self):
G = 0
for p in self.net.parameters():
G += singular_value(p) * p.grad.norm(dim=(0,1)).sum()
G /= self.depth
eta = math.log(0.5 * (1 + math.sqrt(1 + 4*G)))
for p in self.net.parameters():
factor = singular_value(p) / p.grad.norm(dim=(0,1), keepdim=True)
p -= self.gain * eta / self.depth * factor * p.grad
return log使用eta乘以层的权重范数、乘以归一化梯度并除以深度来更新每个层。除以深度实现了按深度缩放。有趣的是,分析中没有使用梯度归一化,因为像Adam这样的其他优化器也启发式地引入了类似的想法。
实验
进行这些实验的目标是为了测试AGD优化算法的能力:(1)在广泛的体系结构和数据集上的收敛性能;以及(2)实现与调参后的Adam和SGD算法相当的测试精度。
接下来的图4显示了从完全连接网络(FCN)到ResNet-50网络的四种架构在从CIFAR-10到ImageNet的数据集上的学习曲线。我们将实线所示的AGD优化器与虚线所示的标准优化器进行比较(SGD基于ImageNet数据集,调优后的Adam对应于其他三种情况)。最上面一行显示了训练目标(损失)和自动学习率η。最下面一行显示了训练和测试的准确性。图5展示了在8层FCN上进行比较的AGD、调优后的Adam与调优后的SGD。我们看到所有三种算法的性能非常相似,达到了几乎相同的测试精度。
图6显示,AGD在较宽的深度(2至32)和宽度(64至2048)范围内训练FCN。图7显示了AGD对批次大小(从32到4096)和4层FCN的依赖性。无论批量大小,它似乎都会收敛到一个很好的最优值!
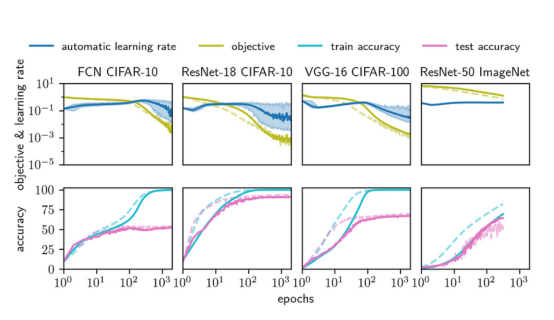
图4——四种架构上的AGD与Adam算法比较:CIFAR-10上的16层深的FCN、CIFAR-10的ResNet-18、CIFAR-100上的VGG-16和ImageNet-1k上的ResNet-50。AGD与超参数调优后的Adam保持合理的速度(这需要网格搜索几个数量级)!
这些实线表示AGD,虚线表示Adam(除了ImageNet,我们使用SGD)。最上面一行显示了训练目标(即损失)和训练期间自动学习率η的值。最下面一行显示了训练和测试的准确性。
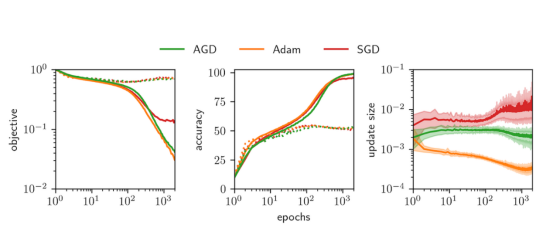
图5:具有均方误差损失的深度为8的FCN网络上的AGD、Adam与SGD算法比较
值得注意的是,Adam和SGD都调整了它们的学习率。在左边图形中,我们绘制了训练和测试目标函数(即损失)。中间图形显示了训练和测试的准确性。右边图形显示了每个训练周期期间权重的平均值、最小值和最大值变化。
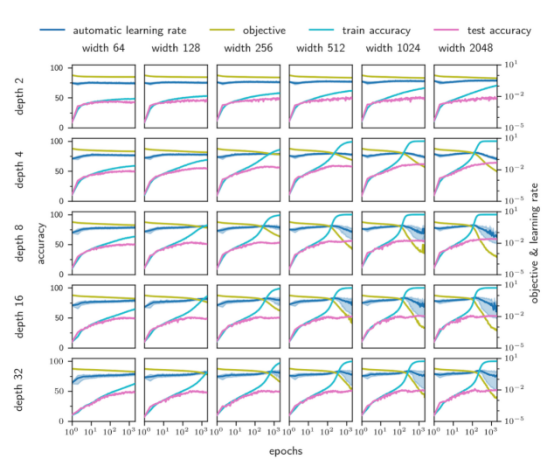
图6:AGD算法在很大的深度和宽度范围内能够自如地收敛。不过,较小的架构往往缺乏实现低损耗的能力,但AGD仍可以训练它们!
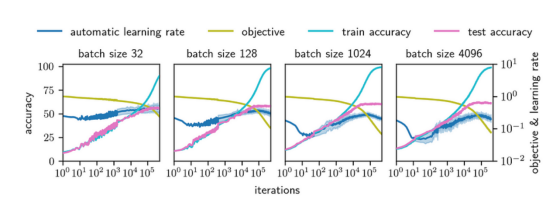
图7:为了检查AGD算法不仅适用于批量大小128,这里还提供了一个深度为4的FCN模型的批量大小选择
结论
总的来说,本文实现了一个“架构感知”类型优化器:自动梯度下降(AGD),它能够在指定的批量范围大小下训练成功从CIFAR-10数据集上的FCN等小型模型系统直到大型数据集ImageNet上的ResNet-50等大型模型系统,而无需手动进行超参数调整。
虽然使用AGD并没有从机器学习中完全删除所有的超参数,但剩下的超参数——批量大小和体系结构——通常能够实现均衡时间/计算方面的预算代价。
尽管如此,仍然有许多工作要做。例如,我们没有明确考虑由于批次大小而引入梯度的随机性。此外,我们也没有研究像权重衰减这样的规则化。虽然我们在增加对仿射参数(在批处理范数层中)和偏差项的支持方面做了一些工作,但我们还没有对其进行广泛的测试,也没有像本文引用的其他结果那样从理论上证明它是合理的。
也许最重要的是,我们仍然需要进行转换器(Transformer)所需的分析,并在NLP任务中测试AGD。在OpenWebText2上对GPT-2进行的初步实验表明,AGD在这种情况下也非常有效!
最后,如果你想尝试使用AGD算法的话,请查看Jeremy的GitHub代码以获得一个干净的版本,或者查看我的GitHub以获得支持偏置和仿射参数的开发版本!我们希望你会觉得这个算法有用。
附录A
最后,我们将在这里简要介绍一下我们论文证明过程中的一些重要步骤。这是为那些想看看此算法的主要思想是如何结合在一起的人设计的,而不需要经过我们论文中的完整证明。

其中,方程(1)明确规定了如何将数据集S上的总体目标分解为各个数据点。L表示损失,x表示输入,y表示目标,w表示权重。方程(2)显示了目标线性化误差的分解——在权重Δw发生变化的情况下,高阶项对损失ΔL(w)变化的贡献。目标的线性化误差很重要,因为它等于在权重w-bounding下扩展的损失中的高阶项的贡献,这将告诉我们在高阶项变得重要之前我们可以移动多远,并确保我们正在采取合理大小的步长实现收敛。
方程(2)中的RHS上的第一项是两个高维向量、模型的线性化误差和损耗相对于f(x)的导数之间的内积。由于没有明确的理由说明为什么这两个向量应该对齐,我们假设它们的内积为零。
将L(W+ΔW)加到方程(2)的每一侧,并注意到损失的线性化误差恰好是布雷格曼散度(Bregman Divergence),我们可以进一步简化符号表示:
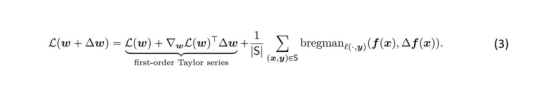
Bregman散度是两点之间距离的度量(在这种情况下,是神经网络两个不同参数选择的输出),用严格凸函数定义——在这种情况中,即损失函数。
对于均方误差损失来说,计算Bregman散度实际上是非常简单的。并且,我们容易得出如下表达:
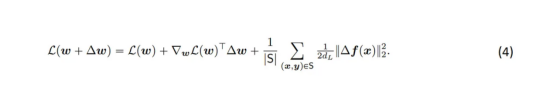
其中,d是网络的输出维度。我们现在可以断言存在以下缩放表达式。尽管所有这些都有点武断;但是,采用这种形式会使问题分析变得更加简单。
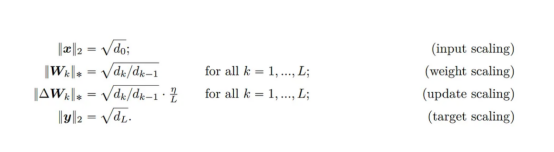
我们对网络输出的大小使用以下两个界限。其中,方程(5)限制了网络输出的大小,并且仅将(输入缩放)和(权重缩放)应用于完全连接的网络。方程(6)限制了f(x)的最大变化与权重W的变化。(6)中的第二个不等式在大深度下最紧,但在任何深度下都成立。
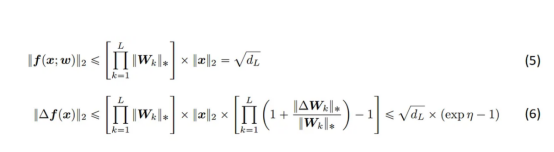
现在,我们将方程(6)代入方程(4),并将所有项显式展开,得到方程(7)。
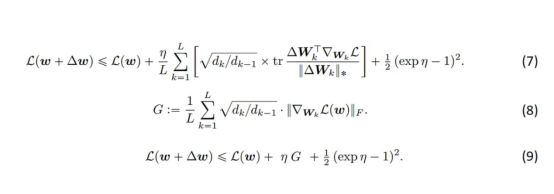
在关于梯度条件的附加假设下,我们可以用方程(8)中定义的G代替方程(7)中的和,这在本文中进行了详细讨论。最后,我们得到方程(9)——这是多数化——图3中的红线。我们通过对η进行微分来最小化多数化,并在exp(η)中求解由此产生的二次方,保留正解。于是,我们有了以下新的表达形式:
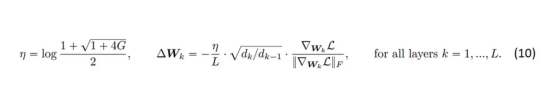
至此,就完成了我们对自动梯度下降的推导介绍。如果您有任何意见、问题或其他类型的反馈,请告诉我们。
最后需要说明的是,本博客中的所有图片都是由我们论文的作者制作的,图2受链接https://www.jeremyjordan.me/nn-learning-rate/文章中的图启发而制作的。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Train ImageNet without Hyperparameters with Automatic Gradient Descent,作者:Chris Mingard