译者 | 李睿
审校 | 重楼
什么是人体姿势估计?
人体姿态估计是检测和估计图像或视频中人物姿态的过程。它包括检测人物身体的关键点或关节,例如头部、肩膀、肘部、手腕、臀部、膝盖和脚踝,并估计它们在图像中的位置。这可以使用各种计算机视觉技术来完成,例如特征检测和机器学习算法。
估计人体姿势的方法
自上而下的方法
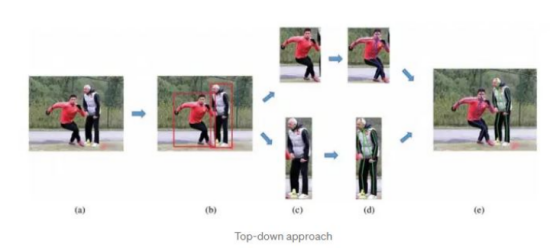
在自上而下的人体姿势估计方法中,人工智能算法首先检测图像或视频帧中的人物,然后通过分析被检测到的人物的身体部位及其相互之间的关系来估计人物姿势。
这种方法通常包括检测人物的头部、躯干和四肢,然后使用这些信息来估计人物的姿势。它还可能涉及使用关于人物的身体比例和身体上关键点(例如关节)的位置的信息来改进姿势估计。
自上而下的方法可以有效地估计图像或视频帧中人物的姿势,但在处理遮挡或同一帧中的多个人物时可能不太有效。它们也可能比自下而上的方法计算更密集,自下而上的方法通过分析图像或视频帧的局部特征来估计人体姿态。
自下而上的方法
在一种自下而上的人体姿势估计方法中,首先分析图像或视频帧中的局部特征,例如边缘和角落,然后使用这些信息来检测和跟踪人物身体的各个部位,最后组合检测到的身体部位以估计帧中单人或多人的姿势。
自下而上的方法通常比自上而下的方法更快、更有效,因为它们不需要对人物进行初步检测,也不需要使用关于身体比例和身体关键点的信息。然而,它们可能不如自上而下的方法准确,特别是在局部特征不明确或人物姿势变化很大的情况下。
自下而上的方法对同一帧中的遮挡和多人的检测更加有效,因为它们不依赖于人物的整体检测。然而,他们可能很难准确地估计人物的姿势是部分或完全遮挡。
自下而上方法的工作方式
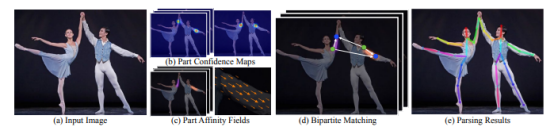
姿态估计的组件
上图显示了从图像中估计一个人的姿势所涉及的不同组件。以下详细介绍每个组件。
组件置信度图
人体姿态估计的第一步是检测图像或视频中人体关节的位置。这通常是通过结合机器学习算法和计算机视觉技术来完成的。一种流行的方法是使用卷积神经网络(CNN)将图像中的像素分类为不同的身体部位。卷积神经网络(CNN)是在一个带注释的图像的大型数据集上训练的,其中包括关于身体关节的位置和方向的信息。
部位关联字段
部位关联字段(PAF)是人体不同部位之间关系的表示。它用于建模人体部位之间的连接,并提供一种估计图像或视频帧中的人物姿势的方法。部位关联字段(PAF)通常表示为一个2D数组,数组中的每个元素表示人体部位连接到图像中特定位置的可能性。部位关联字段(PAF)通常是使用卷积神经网络(CNN)或其他机器学习模型生成的,这些模型是在各种姿势的带注释的图像或视频的大型数据集上训练的。
为了生成部位关联字段(PAF),卷积神经网络(CNN)处理输入图像并生成一组特征图,然后通过一系列卷积层和池化层来提取关于人体部位之间关系的相关信息。例如,为了估计人物手臂的姿势,算法可能会使用部位关联字段(PAF)根据肘关节的存在来确定肩关节的可能位置,然后使用该信息来估计手臂其余部分的姿势。部位关联字段(PAF)被广泛应用于人体姿态估计,因为它们能够捕捉身体部位之间的复杂关系,并且可以比其他方法更有效地处理遮挡和可变姿态。然而,生成它们可能需要大量的计算,并且可能需要大量的带注释的图像或视频数据集进行训练。
双方的匹配
用于确保同一图像中一个人的关键点与另一个人的关键点不匹配。这是通过计算关键点之间的汉明距离并根据最小距离进行映射来实现的,其中流行的算法是匈牙利算法。
解析结果
该过程的最后一步是解析结果,包括显示图像中每个人身的图像关键点。这有助于每个人的人体姿势的可视化。
在Python中进行人体姿势估计
谷歌发布了一个易于导入和运行的名为Mediapipe的框架,该框架支持多种编程语言。本文将展示如何使用Mediapipe训练过的姿态估计模型。姿态估计模型经过优化,可以在轻量级设备上运行。用户可以使用该程序输入包含人类的图像,并估计图像中人类的姿势并解释结果。
安装Mediapipe
pip install mediapipe读取图像并将图像转换为矩阵
Python
#Read an image
img = cv2.imread("image.jpg")将图像从RGB转换为BGR,以一种可以被Mediapipe接受的方式。
Python
# Run MediaPipe Pose and draw pose landmarks.
with mp_pose.Pose(static_image_mode=True, min_detection_cnotallow=0.5, model_complexity=2) as pose:
# Convert the BGR image to RGB and process it with MediaPipe Pose.
results = pose.process(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))将世界坐标转换为图像坐标。
Python
# Print nose landmark.
image_hight, image_width, _ = img.shape
if not results.pose_landmarks:
continue
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y * image_hight})'
)类中带有landmark变量的结果对象的坐标存储在世界坐标中,而不是精确的图像坐标中。上面代码片段中的print语句显示了转换并打印图像上的实际坐标。
结果可视化
Python
# Draw pose landmarks.
print(f'Pose landmarks of {name}:')
annotated_image = raw_img.copy()
mp_drawing.draw_landmarks(
annotated_image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
cv2.imshow(annotated_image)
cv2.waitKey(0)上面的代码将有助于可视化的人物的姿态与骨架关键点。
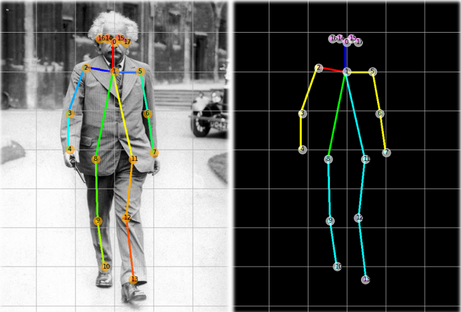
解读结果
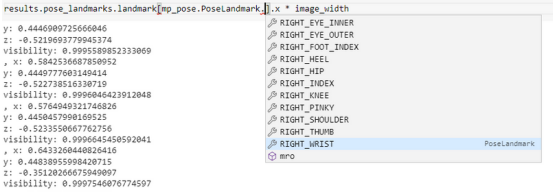
上图显示了人体每个点的坐标存储位置。在业务用例中,如果可以检索精确的坐标来重用以解决业务问题,例如使用头部坐标来估计特定健身运动的次数或检查手部坐标以查看游泳时划水的角度,那么姿势估计是有用的。
完整的代码
Python
#Import all dependencies
#Source - https://google.github.io/mediapipe/solutions/pose.html
import cv2 #For all image processing related information
import math
import numpy as np #For matrix operations
import mediapipe as mp #Importing the library to run pose estimation
#Read an image
raw_img = cv2.imread("image.jpg")
img = cv2.cvtColor(raw_img, cv2.COLOR_BGR2RGB)
# Run MediaPipe Pose and draw pose landmarks.
with mp_pose.Pose(static_image_mode=True, min_detection_cnotallow=0.5, model_complexity=2) as pose:
# Convert the BGR image to RGB and process it with MediaPipe Pose.
results = pose.process(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# Print nose landmark.
image_hight, image_width, _ = img.shape
if not results.pose_landmarks:
continue
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y * image_hight})'
)
# Draw pose landmarks.
print(f'Pose landmarks of {name}:')
annotated_image = raw_img.copy()
mp_drawing.draw_landmarks(
annotated_image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
cv2.imshow(annotated_image)
cv2.waitKey(0)姿态估计在国际足联2022年世界杯中的应用

姿态估计应用比较广泛,它被用于各种业务案例中。其中一些是在医疗保健、零售、健身和体育领域。最近举办的国际足联2022年世界杯也使用了姿态估计技术,通过使用视觉传感器和硬件传感器来识别球员越位。
判断越位是足球比赛中的一项规则,要求进攻球员在传球前必须落后于对手球队的最后两名球员,这两名球员通常是守门员和后卫。判罚越位的错误可能会发生,因为比赛进行得很快,裁判员必须离得很近才能判断是否越位。此外,助理裁判可能无法做出准确的决定,可能导致错误的判罚。主裁判和助理裁判的错误会给输球的球队造成损失,这些错误通常涉及越位判罚和判断进球是否准确。根据研究,裁判在大约20%~26%的越位判罚中会犯错误。以下深入了解国际足联如何使用姿势估计来识别越位。
鹰眼摄像头

2022年世界杯在每个球场使用12个鹰眼摄像头,并放置在球场周围。摄像头在现场进行校准,以识别本地坐标和全局坐标。来自摄像头的帧也有手动标记的线条,以帮助识别足球场地上的线条。
足球传感器

除了用于跟踪球员在场上运动的12个摄像头之外,传感器通常被放置在足球内部,以帮助准确跟踪它的位置。在足球里使用传感器可以让系统以很高的精度跟踪它的运动,即使它在高速运动。
在足球上使用传感器的一个原因是为了提高人工智能系统在场上检测球位置的准确性。仅靠摄像头可能不足以在任何时候准确跟踪球的运动,特别是在足球快速移动或被场上球员或其他物体部分遮挡的情况下。通过使用传感器,该系统可以更准确地检测到足球的位置和运动,即使是在具有挑战性的条件下。
传感器还可以用来测量足球的其他特性,例如速度和旋转速度,这对某些类型的比赛(例如任意球和点球)很重要。通过准确跟踪这些特征,人工智能系统可以为视频助理裁判(VAR)提供额外的信息,这些信息可能对足球比赛中的决策有用。
视频助理裁判(VAR)
它包括一个被称为视频助理裁判(VAR)箱的控制室,可以访问足球比赛的所有摄像头视图,以及一个视频助理裁判(VAR)团队,他们与场上的主裁判保持不断的沟通。
人工智能裁判:将一切结合在一起
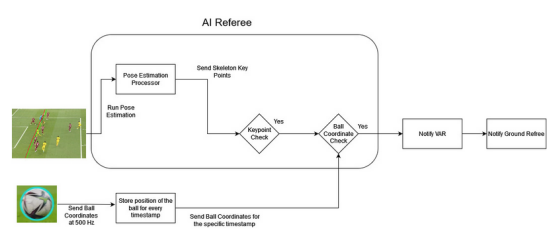
鹰眼摄像头的每一帧都经过姿势估计处理器进行处理,它预测帧中球员的骨架关键点。与此同时,用时间戳连续记录足球的坐标。关键点检查器将进攻球员(试图进球的球员)和防守球员(试图阻止进球的对方球员)的预测关键点进行比较。如果进攻球员的关键点比进攻和防守球员的关键点都更靠近球门线,就可能出现越位情况。如果关键点检查器确定可能存在越位情况,它将从特定的时间戳中检索进攻球员的坐标,并检查是否越位。如果所有条件都满足,并且越位情况得到确认,则决定将被发送给视频助理裁判(VAR)团队。视频助理裁判(VAR)团队可以查看录像,并为场内裁判提供更多的信息,以帮助他们做出更明智的决定。
结论
在本文中,你学习了使用深度学习的姿态估计的概念,使用谷歌Mediapipe实现姿态估计,以及已经解决了现实问题的姿态估计的应用。
原文标题:Deep Learning-Based Pose Estimation,作者:Sumedh Datar