5月16日,博通主办的AI网络研讨会在北京成功举办。来自国内外的互联网、运营商等设备厂商齐聚一堂,围绕博通在智算中心网络领域的最新技术、产品方案进行了研讨交流。与会者分享了各自在AI网络领域的优秀实践,这有助于促进客户、合作伙伴和学术界之间的交流与合作,共同推动业界技术的创新和发展。
锐捷网络受邀参会,面向下一代AI云服务的智算中心网络建设,重磅发布了锐捷网络AI Fabric智算中心网络解决方案,以其高吞吐、大带宽、高可用的特性,可应用于大数据处理、机器学习、AIGC多种业务场景,助力客户构建网卡级别的智算中心网络,支撑AI业务快速发展。

研发工程师与客户技术交流
在展会现场,锐捷网络展出了两款 AI Fabric 智算中心网络产品,分别是 400G NCP 交换机——RG-S6930-18QC40F1,以及 200G NCF 交换机——RG-X56-96F1。
- RG-S6930-18QC40F1 交换机的高度为 2U,提供 18 个 400G 的面板口,40 个 200G 的 Fabric 内联口,4 个风扇和 2 个电源。
- RG-X56-96F1 交换机的高度为 4U,提供 96 个 200G 的 Fabric 内联口,4 个风扇和 4 个电源。

左:NCF产品(RG-X56-96F1) 右:NCP产品(RG-S6930-18QC40F1)
在AI研讨会上,锐捷网络刘洋发表了《面向下一代AI云服务的智算中心网络》主题演讲。他认为随着人工智能生成内容的技术赋能,全球各大云服务商也推出了属于自己的大模型和对应的AI云服务,加速计算服务器的迅猛发展的同时,也加快了云用户对AI加速卡的部署进程。因此,如何在AI云服务这个业务模式中保持强有力的竞争力,提升集群的GPU效率变得尤为关键。在网络层面上,提升通信带宽利用率,降低动态时延以及实现无损的网络传输是提升业务效率、降低成本的关键指标。

锐捷网络解决方案经理刘洋演讲现场
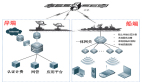
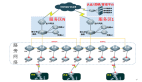
针对以上关键指标,锐捷网络推出了AI Fabric智算中心网络解决方案,AI Fabric方案基于高性能芯片技术,通过将数据流切分成等长的Cell并Hash到所有链路,最大化网络带宽利用率;基于VOQ+Credit的端到端流控机制实现与业务无关的无损自闭环网络,同时以NCP+NCF为基础模块横向扩展的三级网络架构,可以支撑18K~32K规模的GPU卡集群,助力下一代AI云服务的智算中心网络建设。
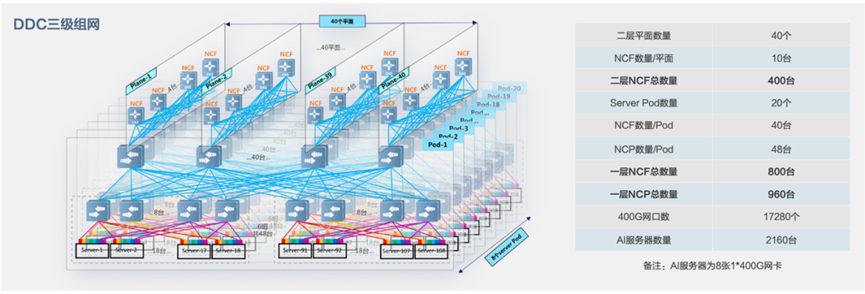
AI Fabric智算中心网络解决方案组网架构
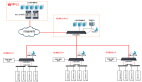
在研发 AI Fabric 智算中心网络解决方案的同时,锐捷网络打造了分布式 OS,旨在简化部署,提高系统可靠性。传统的 DDC (Distributed Disaggregated Chassis,分布式分散式机箱)由于控制面集中,一旦 NCC (Network Cloud Controller网络云控制器)失联,就会影响整个网络,从而影响整个业务流程。另外,由于版本不兼容,如果部分设备需要升级,就会面临巨大的运维难题。锐捷网络 AI Fabric 智算中心网络解决方案采用去中心化的分布式 OS,实现了控制面与管理面解耦。即使管理平台出现问题,也不会影响整个网络的运行。与此同时,它还解决了兼容性问题,设备可以独立升级,大幅降低了运维难度。

来自行业各界的客户、专家
作为下一代AI云业务智算中心网络建设者,锐捷网络致力于在智算数据中心领域提供高品质、高可靠性的整体网络解决方案和先进的产品,以满足客户对智算中心不断提高的需求,助力客户提升业务效率,降低成本。
未来,锐捷将持续精进AI Fabric智算中心网络解决方案,在降低时延、提高在网计算性能、实现端网融合等方面持续突破,打造高速互联、弹性可扩展、绿色节能的下一代AI云服务智算中心网络。此外,锐捷还在积极探索开发基于高性能芯片组网中的端网协同方案,结合智能网卡端到端网络性能的优化,与客户一起迈向AIGC智算时代。