













最近一个综述论文 “Trajectory-Prediction With Vision: A Survey ”,来自现代和安波福的公司Motional;不过它参考了牛津大学的综述文章“Vision-based Intention and Trajectory Prediction in Autonomous Vehicles: A Survey ”。
预测任务基本分为两部分:1)意图,这是一项分类任务,为智体预先设计一组意图类;通常将其视为一个监督学习问题,需要标注智体可能的分类意图;2)轨迹,需要预测智体在后面未来帧中的一组可能位置,称为路点;这构成了智体之间以及智体和道路之间的交互。
之前行为预测模型分类为三种:基于物理的、基于机动的和交互-觉察模型。基于物理的模型构成了动力学方程,为不同类别的智体建模人工设计的运动。这种方法无法对整个场景的隐态进行建模,并且往往一次只关注一个特定的智体。然而,在深度学习之前的时代,这种趋势曾经是SOTA。基于机动的模型是基于智体预期运动类型的模型。交互-觉察的模型通常是一种基于机器学习的系统,对场景中的每个智体进行逐对推理,并为所有动态智体生成交互-觉察的预测。在场景中附近不同智体目标之间存在高度相关性。对复杂的智体轨迹注意模块进行建模,可以更好泛化。
行为预测可以是隐含的,表现为未来轨迹的形式,也可以是显式的,预测未来的行动或事件。智体的意图可能受到以下因素的影响:a)智体自己的信念或意愿(通常不会被观察到,因此难以建模);b) 社会交互,可以用不同的方法进行建模,如社交池化、图神经网络、注意力等;c) 环境约束,如道路布局,可通过高清(HD)地图进行编码;d) 背景信息,形式为RGB图像帧、激光雷达点云、光流、分割图等。另一方面,轨迹预测本质上更具挑战性——与意图这种分类问题不同,轨迹预测是一个回归(连续)问题。
轨迹和意图需要从交互-觉察入手。举个例子,如果激进地试图进入交通拥挤的高速公路,一辆过来的车可能会有点刹车,这是一个合理的假设。一般来说,轨迹预测可以在图像视角(也称为透视图)或BEV中建模;最好在BEV空间进行。原因是,可以以网格的形式为感兴趣区域(RoI)分配一个专用的距离范围。然而,由于透视图中的消失线,图像视角在理论上可以具有无限的RoI。因为运动更线性地建模,所以在BEV空间中对遮挡进行建模更容易。根据姿态估计(自车的平移和旋转)可以很容易地进行自车运动补偿。此外,这个空间保留了智体的运动和尺度,即不管离自车有多远,周围车辆将占据相同数量的BEV像素;但图像视角的情况并非如此。为了预测未来,需要对过去有一个了解。这通常可以通过跟踪来完成,也可以用历史聚合BEV特征来完成。
下图是预测模型的一些组件和数据流框图:
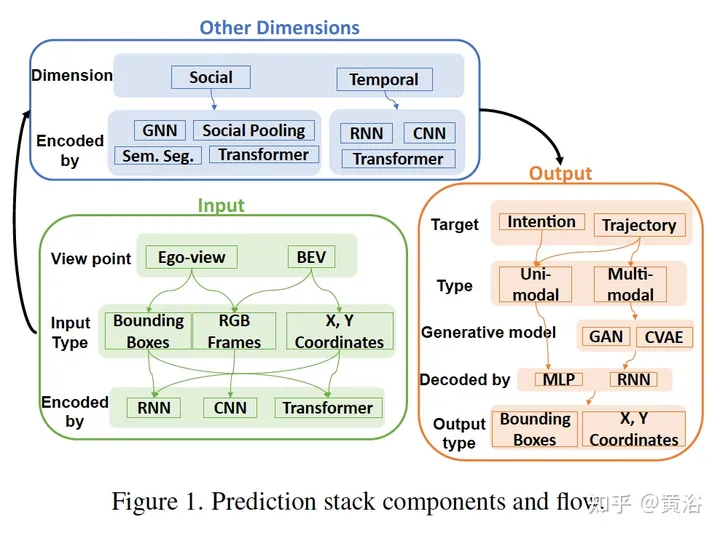
下表是预测模型的总结:

以下基本从输入/输出入手讨论预测模型:
1)Tracklets:感知模块预测所有动态智体的当前状态。这种状态包括3-D中心、维度、速度、加速度等属性。跟踪的作用是利用这些数据并将其临时关联,这样每个跟踪器都能保存所有智体的状态历史。现在,每个tracklet都表示该智体过去的运动。这是一种最简单的预测模型形式,因为它只包含稀疏的轨迹作为输入。一个好的跟踪器能够跟踪一个智体,即使在当前帧中被遮挡。传统的跟踪器是基于非机器学习的网络,因此使用这种方法很难实现端到端模型。
2)原始传感器数据:这是一种端到端方法,模型获取原始传感器数据信息,并直接预测场景中每个智体的轨迹预测。这种方法可能有也可能没有辅助输出及其损失来监督复杂的训练。这一类方法的缺点是,用于输入的信息密集,计算上昂贵。此外,由于将三个问题结合在一起,即感知、跟踪和预测;模型变得很难开发,甚至更难收敛。
3)摄像头-vs- BEV:BEV方法处理来自顶视类似地图的数据,摄像头预测算法从自车角度感知世界,由于多种原因,后者通常比前者更具挑战性;首先,从BEV感知可以获得更广阔的视野和更丰富的预测信息,相比之下摄像头的视野较短,这限制了预测范围,因为汽车无法做视野以外规划;此外,摄像头更容易被遮挡,因此与基于相机的方法相比,BEV方法受到的“部分可观察性”挑战更少;其次,除非激光雷达数据可用,否则单目视觉使算法难以推断关注智体的深度,这是预测其行为的重要线索;最后,摄像头正在移动,这需要处理关注智体的运动和自车的运动,这与静态BEV不同;提一句:作为一种缺点,BEV表征方法仍然存在累积错误的问题;尽管在处理相机视图方面存在固有的挑战,但它仍然比BEV更实用,其实汽车很少能访问显示道路上BEV和关注智体位置的摄像头。结论是,预测系统应该能够从自车的角度看待世界,包括激光雷达和/或立体相机,其数据以3D方式感知世界可能是有利的;另一个重要的相关点是,每次若必须包括关注智体的位置以进行预测时,最好使用边框位置,而不是纯粹的中心点,因为前者的坐标隐含自车和行人之间的相对距离变化以及相机自运动;换句话说,随着智体接近自车,边框变得更大,提供了对深度的附加(尽管是初步的)估计。
4)自运动预测:自车运动进行建模生成更准确的轨迹。另外一些方法使用深度网络或动力学模型对关注智体的运动进行建模,利用从数据集输入计算的额外量,如姿势、光流、语义图和热图。
5)时域编码:由于驾驶环境是动态的,有许多活动智体,因此有必要在智体时间维度进行编码可建立一个更好的预测系统,将过去发生的事情与未来通过现在发生的事情联系起来;了解智体的来源有助于猜测智体下一步可能会去哪里,大多数基于摄像头的模型处理较短的时间范围,而对于较长的时间范围处理,预测模型需要一个更复杂的结构。
6) 社交编码:为了应对“多智体”的挑战,大多数性能最好的算法使用不同类型的图神经网络(GNN)来编码智体之间的社会交互;大多数方法分别对时间和社会维度进行编码——要么从时间层面开始,然后考虑社会层面,要么相反顺序;有一种基于Transformer的模型,可以同时对两个维度进行编码。
7)基于预期目标的预测:行为意图预测与场景上下文一样,通常会受到不同预期目标的影响,并且应该通过解释来推断;对于以预期目标为条件的未来预测,这个目标会被建模为未来状态(定义为目的地坐标)或智体期望的运动类型;神经科学和计算机视觉的研究表明,人通常是目标-导向的智体;此外在做出决策的同时,人遵循一系列连续级的推理,最终制定出短期或长期计划;基于此,这个问题可分为两类:第一类是认知性的,回答智体要去哪里的问题;第二个是任意性的,回答这个智体如何实现其预期目标的问题。
8)多模态预测:由于道路环境是随机的,一个先前的轨迹可以展开不同的未来轨迹;因此,解决“随机弹性(stocasticity)”挑战的实用预测系统会对问题的不确定性进行建模;尽管存在离散变量的潜空间建模的方法,但多模态仅应用于轨迹,完全显示其在意图预测方面的潜力;采用注意力机制,可用于计算加权。





























