一、摘要
上篇文章中,我们有介绍到对象属性复制相关的工具,这些工具所进行的对象拷贝,其实都是浅拷贝模式。
可能有的同学会发出疑问,什么叫浅拷贝?
我们都知道,Java 中的数据类型分为值类型(基本数据类型)和引用类型,值类型包括 byte、short、 int、long、float、double、boolean、char 等简单数据类型,引用类型包括类、接口、数组等复杂类型。
根据数据类型的不同,在进行属性值拷贝的时候,如果是值类型,复制的是属性值,如果是复杂类型,比如对象,复制的内容可能是属性对应的内存引用地址。
因此,在 Java 中对于复杂类型的数据,也分为**浅拷贝(浅克隆)与深拷贝(深克隆)**方式,区别如下:
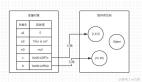
- 浅拷贝:将原对象或原数组的引用直接赋给新对象或者新数组,新对象只是原对象的一个引用,也就是说不管新对象还是原对象,都是引用同一个对象
- 深拷贝:创建一个新的对象或者数组,将原对象的各项属性的值拷贝过来,是“值”而不是“引用”,两者对象是不一样的
对于概念的解释,可能也很难理解,下面我们简单的通过几个案例向大家介绍!
二、案例实践
2.1、浅拷贝
首先我们新建两个对象,其中User关联Account对象,内容如下:
public class User {
/**
* 用户ID
*/
private Long userId;
/**
* 账户信息
*/
private Account account;
//...get、set
@Override
public String toString() {
return "User{" +
"userId=" + userId +
", account=" + account +
'}';
}
}public class Account {
/**
* 账号余额
*/
private BigDecimal money;
//...get、set
@Override
public String toString() {
return "Account{" +
"money=" + money +
'}';
}
}使用Spring BeanUtils工具进行对象属性复制,操作如下:
// 定义某用户,账户余额 100块
Account sourceAccount = new Account();
sourceAccount.setMoney(BigDecimal.valueOf(100));
User sourceUser = new User();
sourceUser.setUserId(1L);
sourceUser.setAccount(sourceAccount);
// 进行对象属性拷贝
User targetUser = new User();
BeanUtils.copyProperties(sourceUser, targetUser);
System.out.println("修改嵌套对象属性值前的结果:" + targetUser.toString());
//修改原始对象账户余额为200
sourceAccount.setMoney(BigDecimal.valueOf(200));
System.out.println("修改嵌套对象属性值后的结果:" + targetUser.toString());输出结果如下:
修改嵌套对象属性值前的结果:User{userId=1, account=Account{money=100}}
修改嵌套对象属性值后的结果:User{userId=1, account=Account{money=200}}从结果上可以很明显的得出结论:当修改原始的嵌套对象Account的属性值时,目标对象的Account对象对应的值也跟着发生变化。
很显然,这与我们预期想要的对象属性拷贝是想违背的,我们所期待的结果是:原始对象值即使发生变化,目标对象的值也不应该发生变化!
面对这种情况,怎么处理呢?
我们可以把对象Account单独拉出来,进行一次属性值拷贝,然后再进行封装,比如操作如下:
// 定义某用户,账户余额 100块
Account sourceAccount = new Account();
sourceAccount.setMoney(BigDecimal.valueOf(100));
User sourceUser = new User();
sourceUser.setUserId(1L);
sourceUser.setAccount(sourceAccount);
// 拷贝 Account 对象
Account targetAccount = new Account();
BeanUtils.copyProperties(sourceAccount, targetAccount);
// 拷贝 User 对象
User targetUser = new User();
BeanUtils.copyProperties(sourceUser, targetUser);
targetUser.setAccount(targetAccount);
System.out.println("修改嵌套对象属性值前的结果:" + targetUser.toString());
//修改原始对象账户余额为200
sourceAccount.setMoney(BigDecimal.valueOf(200));
System.out.println("修改嵌套对象属性值后的结果:" + targetUser.toString());输出结果如下:
修改嵌套对象属性值前的结果:User{userId=1, account=Account{money=100}}
修改嵌套对象属性值后的结果:User{userId=1, account=Account{money=100}}即使Account对象数据发生变化,也不会改目标对象的数据,与预期结果一致!
现在的情况是User只有一个嵌套对象Account,假如像这样的对象有十几个呢,采用以上方式显然不可取。
这个时候深拷贝,该登场了!
2.2、深拷贝
Java 的深拷贝有两种实现方式,第一种是通过将对象序列化到临时文件,然后再通过反序列化方式,从临时文件中读取数据,操作案例如下!
首先所有的类,必须实现Serializable接口,推荐显式定义序列化 ID。
public class User implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 用户ID
*/
private Long userId;
/**
* 账户信息
*/
private Account account;
//...get、set
@Override
public String toString() {
return "User{" +
"userId=" + userId +
", account=" + account +
'}';
}
}public class Account implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 账号余额
*/
private BigDecimal money;
//...get、set
@Override
public String toString() {
return "Account{" +
"money=" + money +
'}';
}
}// 定义某用户,账户余额 100块
Account sourceAccount = new Account();
sourceAccount.setMoney(BigDecimal.valueOf(100));
User sourceUser = new User();
sourceUser.setUserId(1L);
sourceUser.setAccount(sourceAccount);
//把对象写入文件中
try {
FileOutputStream fos = new FileOutputStream("temp.out");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(sourceUser);
oos.flush();
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
//从文件中读取对象
User targetUser = null;
try {
FileInputStream fis = new FileInputStream("temp.out");
ObjectInputStream ois = new ObjectInputStream(fis);
targetUser = (User) ois.readObject();
fis.close();
ois.close();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("修改嵌套对象属性值前的结果:" + targetUser.toString());
//修改原始对象账户余额为200
sourceAccount.setMoney(BigDecimal.valueOf(200));
System.out.println("修改嵌套对象属性值后的结果:" + targetUser.toString());输出结果:
修改嵌套对象属性值前的结果:User{userId=1, account=Account{money=100}}
修改嵌套对象属性值后的结果:User{userId=1, account=Account{money=100}}通过序列化和反序列化的方式,可以实现多层复杂的对象数据拷贝。
因为涉及到需要将数据写入临时磁盘,性能可能会有所下降!
2.3、json 序列化和反序列化
对于对象深度拷贝,还有第二种方式,那就是采用 json 序列化和反序列化相关的技术来实现,同时性能也比将数据写入临时磁盘的方式要好很多,并且不需要显式实现序列化接口。
json 序列化和反序列化的底层思想是,将对象序列化成字符串;然后再将字符串通过反序列化方式成对象。
以jackson工具库为例,具体使用方式如下!
首先导入相关的jackson依赖包!
<!--jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.9.8</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.9.8</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.8</version>
</dependency>其次,编写统一Json处理工具类!
public class JsonUtil {
private static final Logger log = LoggerFactory.getLogger(JsonUtil.class);
private static ObjectMapper objectMapper = new ObjectMapper();
static {
// 序列化时,将对象的所有字段全部列入
objectMapper.setSerializationInclusion(JsonInclude.Include.ALWAYS);
// 允许没有引号的字段名
objectMapper.configure(JsonParser.Feature.ALLOW_UNQUOTED_FIELD_NAMES, true);
// 自动给字段名加上引号
objectMapper.configure(JsonGenerator.Feature.QUOTE_FIELD_NAMES, true);
// 时间默认以时间戳格式写,默认时间戳
objectMapper.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, true);
// 忽略空bean转json的错误
objectMapper.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
// 设置时间转换所使用的默认时区
objectMapper.setTimeZone(TimeZone.getDefault());
// 反序列化时,忽略在json字符串中存在, 但在java对象中不存在对应属性的情况, 防止错误
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
objectMapper.configure(MapperFeature.ACCEPT_CASE_INSENSITIVE_PROPERTIES, true);
//序列化/反序列化,自定义设置
SimpleModule module = new SimpleModule();
// 序列化成json时,将所有的long变成string
module.addSerializer(Long.class, ToStringSerializer.instance);
module.addSerializer(Long.TYPE, ToStringSerializer.instance);
// 自定义参数配置注册
objectMapper.registerModule(module);
}
/**
* 对象序列化成字符串
* @param obj
* @param <T>
* @return
*/
public static <T> String objToStr(T obj) {
if (null == obj) {
return null;
}
try {
return obj instanceof String ? (String) obj : objectMapper.writeValueAsString(obj);
} catch (Exception e) {
log.warn("objToStr error: ", e);
return null;
}
}
/**
* 字符串反序列化成对象
* @param str
* @param clazz
* @param <T>
* @return
*/
public static <T> T strToObj(String str, Class<T> clazz) {
try {
return clazz.equals(String.class) ? (T) str : objectMapper.readValue(str, clazz);
} catch (Exception e) {
log.warn("strToObj error: ", e);
return null;
}
}
/**
* 字符串反序列化成对象(数组)
* @param str
* @param typeReference
* @param <T>
* @return
*/
public static <T> T strToObj(String str, TypeReference<T> typeReference) {
try {
return (T) (typeReference.getType().equals(String.class) ? str : objectMapper.readValue(str, typeReference));
} catch (Exception e) {
log.warn("strToObj error", e);
return null;
}
}
}最后,在相关的位置引入即可。
// 定义某用户,账户余额 100块
Account sourceAccount = new Account();
sourceAccount.setMoney(BigDecimal.valueOf(100));
User sourceUser = new User();
sourceUser.setUserId(1L);
sourceUser.setAccount(sourceAccount);
// json序列化、反序列化
User targetUser = JsonUtil.strToObj(JsonUtil.objToStr(sourceUser), User.class);
System.out.println("修改嵌套对象属性值前的结果:" + targetUser.toString());
//修改原始对象账户余额为200
sourceAccount.setMoney(BigDecimal.valueOf(200));
System.out.println("修改嵌套对象属性值后的结果:" + targetUser.toString());输出结果:
修改嵌套对象属性值前的结果:User{userId=1, account=Account{money=100}}
修改嵌套对象属性值后的结果:User{userId=1, account=Account{money=100}}与预期一致!
三、小结
本文主要围绕对象的浅拷贝和深拷贝,从使用方面做了一次简单的内容总结。
浅拷贝下,原对象和目标对象,引用都是同一个对象,当被引用的对象数据发生变化时,相关的引用者也会跟着一起变。
深拷贝下,原对象和目标对象数据是两个完全独立的存在,相互直接不受影响。
至于当前对象数据,是应该走浅拷贝还是深拷贝模式好,完全取决于当前业务的需求,没有绝对的好或者不好!
如果当前对象需要深拷贝,推荐采用 json 序列化和反序列化的方式实现,相比通过文件写入的方式进行序列化和反序列化,操作简单且性能高!