













译者 | 李睿
审校 | 重楼
本文将分析一种新的数据编排器:Dagster。在行业专家看来,这是第一代数据编排器,它使数据管道更接近关键业务流程,而这些将真正成为关键任务解决方案的业务数据流程。为了描述Dagster的功能和用例,将提供一些有关模式的场景和一些历史信息,这些信息对于理解它带来的业务价值是十分必要的。
在过去的十年中,有许多围绕着编排和编排模式的发展趋势。以下将提供这些模式的简单描述:
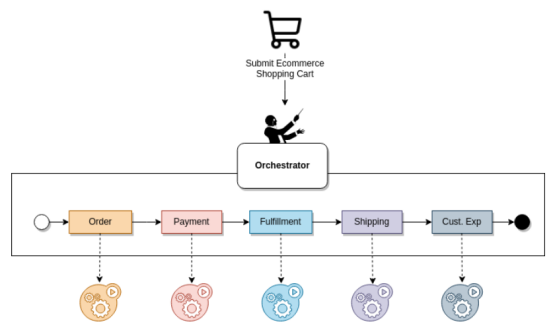
- 编排:它是一个由编排系统编排和集中的定义良好的工作流。编排系统就像一个乐队,乐队的指挥将设定节奏并指挥演奏人员正确演奏。编排有三个主要特点:
(1)提供集中式工作流,方便地可视化业务或数据流程。
(2)工作流由一个最关键的层管理。如果编排系统崩溃,就没有业务服务,就像没有乐队指挥,音乐会也不会取得成功一样。
(3)它们可以非常灵活地集成到不同的架构模式中,例如API、事件驱动、RPC或数据流程。
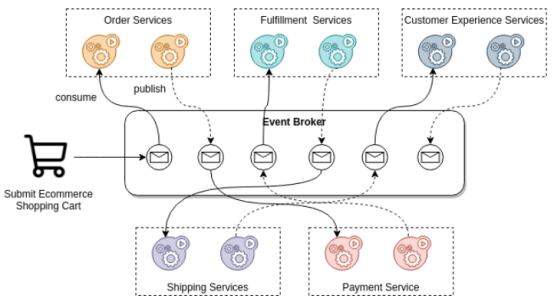
- 编排:它基于事件驱动或流架构,目标是架构中的每一个组件都可以独立工作,并有自己的责任来决定必须采取的行动。编排有三个主要特点:
(1)它必须基于事件驱动或流模式。
(2)没有单一和集中的层,因此不存在单点故障,除非只有单个消息代理。
(3)为理解流程提供更多的可扩展性、灵活性和复杂性。
编排器和业务流程管理软件一直接近业务层,这提高了它们在企业战略技术路线图中的受欢迎程度。第一代业务流程管理(BPM)出现在2000年左右,是面向软件工程师的技术。
在2014年到2018年期间,事件驱动和编排模式开始流行,首先是Netflix,然后是Apache Kafka等流媒体平台的出现。
与软件世界相比,数据世界的出现总是有些晚。尽管正朝着一个场景前进,但在这个场景中,操作和分析世界将不再是孤立的。当企业需要应用数据驱动的方法(数据是决策过程核心的一部分)时,分析层和操作层作为两种不同的思维工作的架构和团队拓扑就不起作用了。
数据世界发生了什么
当大数据的概念开始流行时,出现了第一批数据编排器,例如Apache Ozzie(2010年由雅虎公司开发),它基于DAG XML配置,是一个预定的工作流,专注于Hadoop生态系统。不久之后,基于Python的Apache Airflow(Airbnb在2015年推出)出现了。它提供了更多的功能,如从DAG XML配置迁移到编程配置,以及Hadoop生态系统之外的更多集成,但也是一个定时工作流系统。在两者的中间出现了Luigi(2012年由Spotify公司开发):基于Python,但面向管道而不是DAG,但包括有趣的软件最佳实践,例如A/B测试。
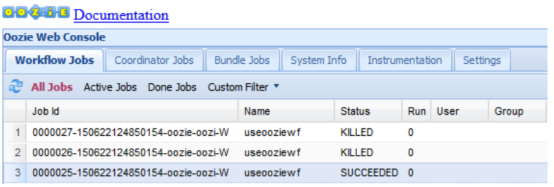
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.1">
...
<decision name="mydecision">
<switch>
<case to="reconsolidatejob">
${fs:fileSize(secondjobOutputDir) gt 10 * GB}
</case> <case to="rexpandjob">
${fs:fileSize(secondjobOutputDir) lt 100 * MB}
</case>
<case to="recomputejob">
${ hadoop:counters('secondjob')[RECORDS][REDUCE_OUT] lt 1000000 }
</case>
<default to="end"/>
</switch>
</decision>
...
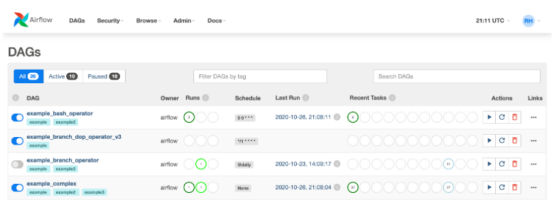
</workflow-app>Apache Airflow是第一个真正意义上的数据编排器,但在人们看来,它有一些改进之处,使其成为一个非常关注传统数据世界的产品,而不是关注数据正在成为企业决策中心的这一新现实。
- 其用户界面很差,完全面向数据工程师。
- 主要面向执行任务,而不知道这些任务是做什么的。
- 一切都是一项任务,增加了可维护性和理解性方面的复杂性。
- 2021年底引入了传感器的概念,传感器是一种特殊类型的运算符,用于等待外部事件,如Kafka事件、JMS消息或基于时间的事件。
import requests
from airflow.decorators import dag, task
@dag(
dag_id="example_complex",
schedule_interval="0 0 * * *",
start_date=pendulum.datetime(2022, 1, 1, tz="UTC"),
catchup=False,
dagrun_timeout=datetime.timedelta(minutes=60),
)
def ExampleComplex():
...
@task
def get_data():
...
@task
def merge_data():
...
dag = ProcessEmployees()所有这些编排解决方案的发展都有一个共同点:这些公司(雅虎、Airbnb或Spotify)在管理其数据管道的复杂性方面面临的挑战。
数据驱动:数据新时代
编码器工具的第一个版本非常注重数据工程师的经验,并基于传统的分析和操作平台架构,例如数据湖、数据中心或实验数据科学工作区。
行业专家表示,他们在2017年左右开始进入数据世界的旅程。在此之前,一直致力于接近业务流程并基于事件驱动解决方案的操作任务关键型解决方案。在那一刻发现了一些工具,例如Oozie或Airflow,它们是ETL工具,专注于计划任务/工作流,没有云计算解决方案,基于企业复杂的实施和维护,可扩展性差,用户体验差。
他们当时的第一个想法是,这些是现在必须满足的工具,但在未来几年不会使用。如今,数据驱动的方法已经改变了一切,每天分析和操作工作负载之间的界限都比以往任何时候都更加分散。有许多基于分析和操作工作负载的关键业务流程。这些关键流程中的许多可能与几年前的非关键数据管道非常相似。2020年,Zhamak Deghani发表了一篇关于数据网格原理的文章,她写了一句特别重要的话:“我确实相信,在未来的某个时刻,我们的技术会发展,使这两个层面更加紧密地结合在一起,但现在,我建议将它们的关注点分开。”
而专家的观点是,这些平台比他们想象的更接近,就业务价值而言,它们比数据网格本身的逻辑架构更容易在小范围内实现。例如,考虑时尚零售行业和关键流程,例如分配、电子商务或物流解决方案。多年前,所有这些流程都是可操作的,其中许多都使用了SAP或Oracle等传统应用程序,而如今,他们需要复杂的数据流程,包括大数据摄取、转换、分析和机器学习模型,以提供实时建议和需求预测,从而实现数据驱动的决策。
当然,需要传统的数据管道/工作流,基于独立操作和分析平台的传统解决方案将继续为一些报告、批分析流程、实验和其他分析创新提供价值。但如今还有其他类型的数据处理;具有不同需求并提供更多业务价值的业务数据流程。需要提供以下功能的数据解决方案:
- 更好的软件开发体验和数据代码管理,应用所有最佳实践,例如隔离环境、单元测试、A/B、数据合同等。
- 友好而丰富的集成生态系统,不仅在大数据世界中,而且在通用数据世界中。
- 基于云的解决方案,提供易于扩展、低维护和易于与IAM解决方案集成。
- 不仅为开发人员,而且为数据科学家、数据分析师、业务分析师和运营团队提供更好的用户体验。
Dagster简介
Dagster是一个数据流编排平台,它超越了人们所理解的传统数据编排器。该项目由Nick Shrock于2018年启动,是他在Facebook工作时发现的一种需求的结果。Dagster的目标之一是提供一种工具,消除管道开发和管道操作之间的障碍,但在这个过程中,开始将数据处理世界与业务流程联系起来。
Dagster与以前的解决方案相比有了显著的改进。
- 面向数据工程师、开发人员和数据/业务操作工程师:它的多功能性和抽象性允许以更面向开发人员的方式设计管道,应用软件最佳实践和管理数据,并将数据管道作为代码。
- 遵循数据工程的优先原则方法,完整的开发生命周期:开发、部署、监视和可观察性。
- 它包含了一个不同的新概念,即软件定义资产。资产是在Dagster中建模并持久化在数据存储库中的数据对象或机器学习。
- Dagit UI是一个基于Web的界面,用于查看Dagster对象并与之交互。这是一个非常直观,用户友好的界面,允许非常简单的操作。
- 这是一个开源的解决方案,同时提供SaaS云解决方案,加速解决方案的实施。
- 非常快速的学习曲线,使开发团队能够在早期交付价值。
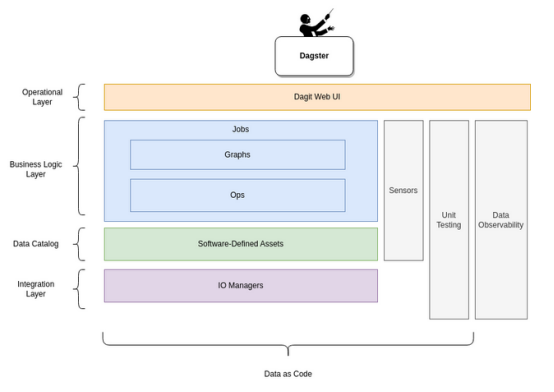
了解Dagster的概念
以下将解释一些基本概念,给出简单的定义,并通过示例构建简单的业务数据管道。
编排器的公共组件
在高层次上,这些是任何编排器的基本组件:
- 作业:主要执行单位和监控单位;用配置和参数实例化一个图。
- 操作:基本上它们是想要执行的任务,包含操作,可以执行简单的任务,例如执行数据库查询(摄取或检索数据),启动远程作业(Spark, Python等),或发送事件。
- 图:子图中相互连接的操作的集合,操作可以组合成一个图来完成复杂的任务。
软件定义资产
资产是持久存储中的对象,例如表、文件或持久机器学习模型。软件定义资产是一个Dagster对象,它将资产与用于生成其内容的功能和上游资产结合在一起。
这是Python中的声明性数据定义,允许:
- 将数据合同定义为代码,以及如何在管道中使用它们。
- 通过数据投影定义实体的组成,无论其物理结构如何。
- 将用于计算资产的业务逻辑与用于读取和写入持久存储的I/O逻辑解耦。
- 应用测试最佳实践,包括在编写单元测试时使用模拟的能力。
- 定义分区的能力为进程的运行和重新启动流程打开了一个可能性的世界。有时,只需要重新处理由于某种原因处理不正确或不完整的分区。
一个惊人的能力是能够使用外部工具,例如DBT、Snowflake、Airbyte、Fivetran和许多其他工具来定义资产。这是令人惊讶的,因为它能够融入全球平台,而不仅仅是大数据生态系统。
启动作业的选项
在这种情况下,最大的区别是这些传感器提供的功能:
- 调度:按固定时间间隔执行作业。
- 传感器:允许基于一些外部事件(如Kafka事件、S3中的新文件、特定资产具体化或数据分区更新)运行。
- 分区:允许基于资产数据子集的更改运行,例如,在特定时间窗口内的数据集中的记录。
- 回填:它提供了只在感兴趣的分区集上重新执行数据管道的能力。例如,重新启动管道,该管道将计算每个国家的商店销售的聚合,但只计算具有美国商店数据的分区。
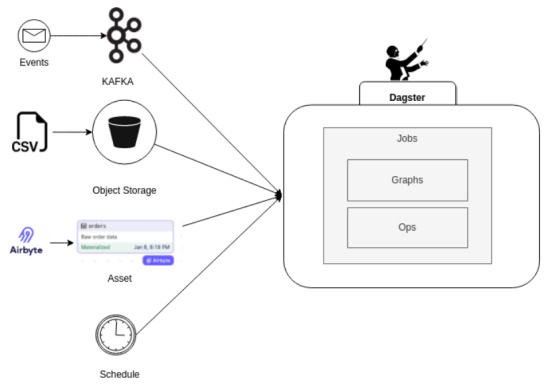
传感器、分区、回填、IO管理器和资产提供的功能的组合代表了数据管道编排世界中非常重要的范式转换。
IO管理器
它提供了与持久存储库的集成组件,允许持久化资产和操作输出,并将其加载到S3、Snowflake或其他数据存储库。
这些组件包含与架构中使用的每个外部通道的所有集成逻辑。可以使用现有的集成,扩展它们以包含特定的逻辑,或者开发新的逻辑。
谱系
资产的使用提供了谱系、数据可观测性和数据质量监控的基础层。在专家看来,数据沿袭是一个非常复杂和关键的方面,现在已经超越了传统的表,包括API、主题和其他数据源。虽然Dagster提供了强大的功能,但它应该是平台整体谱系中的另一个来源,而不是真相的来源。
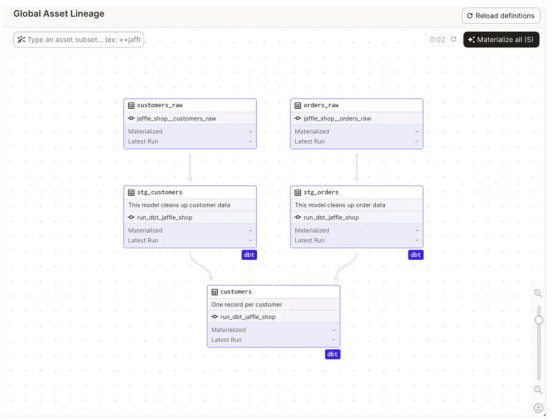
调试和可观察性
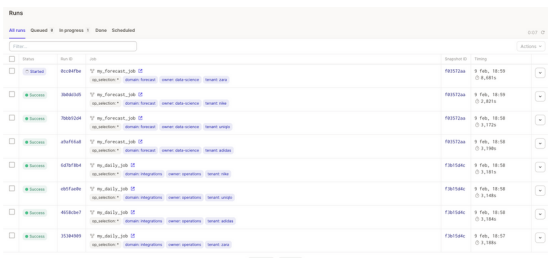
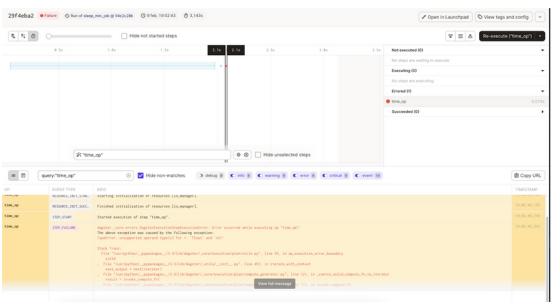
Dagster的另一个与众不同的功能是,当使用软件定义资产时,它提供了数据可观察性。数据操作员或数据工程师有几个特征来分析数据管道:
- 管道状态,操作状态和定时。
- 带有错误和信息跟踪的日志。
- 资产可以包括显示信息的元数据和访问数据物化的链接。它甚至提供了将相关信息发送到不同渠道的能力,例如在S3中的报告中的松弛、事件或持久性。
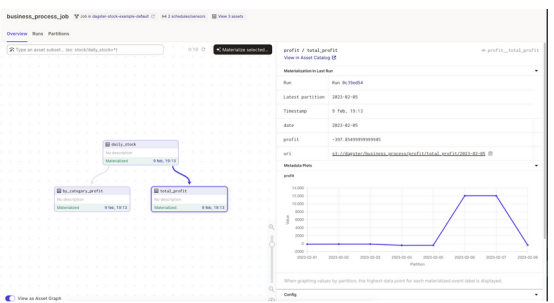
这些功能允许工程师拥有自我自主权,而不会将编排器视为一个黑盒。
元数据
Dagster允许在所有级别添加元信息,最重要的是,数据操作或任何其他操作用户都可以访问它。拥有元数据是非常重要的,但它也必须是可用的,这就是Dagster发挥重要作用的地方。
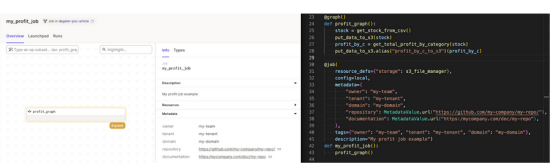
操作团队有较少的过程环境和更多的认知变化,因为他们不参与开发,但同时管理多个生产流。一旦数据工作流成为业务关键任务的一部分,就必须提供这些元信息。
关键业务流程的Dagster
Dagster允许拥有一个面向数据处理的工具,可以在关键路径上将其集成到业务流程中,以提供最大的业务价值。考虑一下从仓库到商店或其他渠道(如合作伙伴或电子商务)的库存补充零售过程。这是一个从配送仓库到商店补充物品的过程,目标是在正确的地方以最优的数量提供正确的产品,以满足客户的需求。
- 通过确保所有渠道都有产品,避免缺货,改善客户体验。
- 通过避免补充销售概率低的产品来提高盈利能力。
- 这是一个业务流程,其中分析和机器学习模型有很多影响。可以将其定义为数据驱动的业务流程。
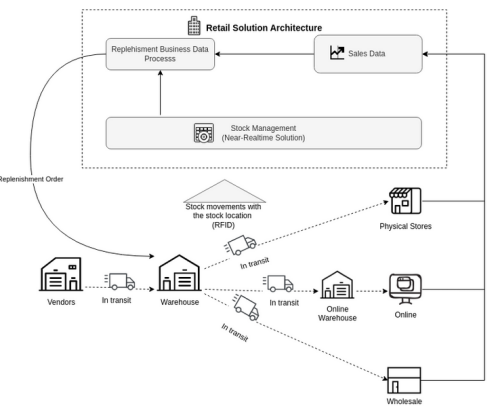
库存补充是一个复杂的业务关键操作过程,以需求预测和库存清单为主要支柱:
- 需求预测需要一个先进的机器学习过程,基于历史数据来预测未来需求。
- 库存清单提供了每个地点(如商店、仓库、分销商等)的可用库存数量。
- 销售根据定价、降价等指标提供有关产品需求的信息。
- 这些流程可以每周、每天或一天多次启动,这取决于是否从中央仓库或例如靠近实体店的仓库进行补货。
这个流程需要一些近乎实时更新的信息,但它是以批处理或微批处理模式运行的数据过程。Dagster是第一个真正支持在操作层从纯操作角度交付业务价值的数据编排器。
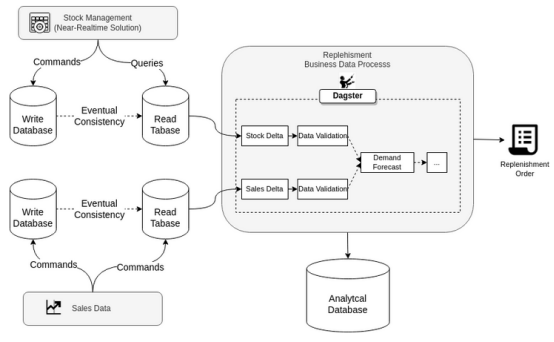
Dagster的常用案例
Dagster中还有其他更传统的用例,例如:
- 具有不同来源的数据管道,并作为分析系统(如数据仓库或数据湖)的目的地。
- 机器学习训练模型。
- 整合机器学习模型的分析过程。
当然,Dagster代表了上述相同标准的这类过程的演变。
结论
预计未来几年将是数据世界令人兴奋的几年,并且正在不断发展,特别是在工具的构建方面,这些工具能够对业务产生更真实、更紧密的影响。Dagster是朝着这个方向迈出的又一步。
而面临的挑战不是新的数据架构或复杂的分析系统,挑战在于尽快提供真正的业务价值。风险在于认为Dagster这样的工具和数据网格这样的架构会给自己带来价值。这些工具提供了多年前所没有的功能,并允许设计满足客户需求的功能。
人们需要从所犯的错误中吸取教训,运用持续改进和批判性思维的方法来做得更好。Dagster是一个很好的工具和伟大的创新,就像Dbt、Apache Kafka、DataHub Data Catalog等其他工具一样,但如果相信一个工具可以解决所有的需求,那么将构建新一代的庞然大物。
Dagster虽然是一个很好的产品,但它只是补充解决方案以增加价值的另一部分。
原文标题:Dagster: A New Data Orchestrator To Bring Data Closer to Business Value,作者:Miguel Garcia


















