译者 | 李睿
审校 | 重楼
自去年11月发布以来,ChatGPT吸引了全球各行业人士的注意力和想象力。人们将它用于各种任务和应用程序,而且它有可能改变流行的应用程序并创建新的应用程序。

但ChatGPT也引发了微软和谷歌等科技巨头之间的人工智能竞赛,使得该行业在大型语言模型(LLM)上的竞争更加激烈,并越来越降低了开放性。这些遵循指令的LLM的源代码、模型架构、权重和训练数据不对公众开放。它们中的大多数都可以通过商业API或黑盒网络应用程序获得。
ChatGPT、Bard和Claude等封闭式LLM有很多优势,包括容易获得尖端技术。但它们也对想要学习和更好地理解LLM的研究实验室和科学家带来了一些限制。对于想要创建和运行自己的模型的企业和组织来说,也很不方便。
幸运的是,在创建商业LLM的竞赛中,也有一个社区努力创建与最先进的LLM性能相匹配的开源模型。这些模型可以通过分享结果来帮助改进研究。他们还可以帮助防止一些资金充足的企业对LLM市场拥有太多的影响和权力。
LLaMa
最重要的开源语言模型之一来自Meta公司的人工智能研究实验室FAIR。今年2月,FAIR发布了LLaMA,这是一个LLM家族,有四种不同的大小:7亿个、13亿个、33亿个和650亿个参数(ChatGPT基于1750亿参数的InstructGPT模型)。
FAIR研究人员对1.4万亿令牌的LLaMA 65B和LLaMA 33B进行了训练,对1万亿令牌的最小模型LLaMA 7B进行了训练(GPT-3 175B是InstructGPT的基本模型,在4990亿个令牌上进行了训练)。
LLaMa不像ChatGPT那样是一个遵循指令的LLM。但LLaMA规模较小背后的想法是,在更多令牌上预训练的较小模型更容易重新训练,并更容易针对特定任务和用例进行微调。这使得其他研究人员可以通过人类反馈强化学习(RLHF)等技术对模型进行微调,使其具有类似ChatGPT的性能。
Meta公司以“专注于研究用例的非商业许可”发布了该模型。它只让学术研究人员、政府附属组织、民间社会和研究实验室根据具体情况访问该模型。人们为了了解可以查阅一些论文,并请求访问训练过的模型。
LLaMa模型在发布后不久就被泄露到网上,这实际上让所有人都可以使用它。
Alpaca

斯坦福大学的研究人员在今年3月发布了Alpaca,这是一种基于LLaMA 7B LLM之后的指令。他们在由InstructGPT生成的52,000个指令遵循示例的数据集上对LLaMA模型进行了微调。
研究人员使用了一种叫做自我指导的技术,在这种技术中,LLM生成指令、输入和输出样本来微调自己。自我指导从一小部分工作人员编写的例子开始,包括指导和输出。研究人员使用这些例子来提示语言模型生成类似的例子。然后他们审查和过滤生成的示例,将高质量的输出添加到种子池中,并删除其余的输出。他们重复这个过程,直到获得足够大的数据集来微调目标模型。
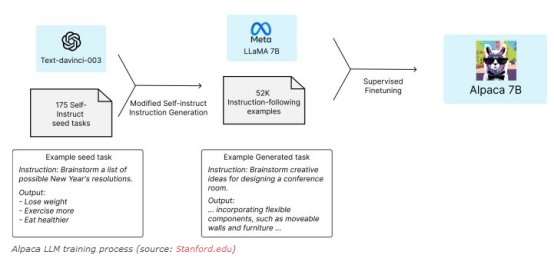
Alpaca的训练流程
根据他们的初步实验,Alpaca的表现与InstructGPT非常相似。
斯坦福大学的研究人员发布了整个自我指导的数据集,数据生成过程的细节,以及生成数据和微调模型的代码(由于Alpaca是基于LLaMA的,必须从Meta公司获取原始模型)。
其研究人员表示,其样品生成的微调成本不到600美元,这对于资金紧张的实验室和组织来说很适用。
然而,研究人员强调,Alpaca仅用于学术研究,禁止用于任何商业用途。它是由LLaMa创建的,这使得它受到与其基本模型相同的许可规则的约束。由于研究人员使用了InstructGPT来生成微调数据,因此他们必须遵守OpenAI公司的使用条款,该条款禁止开发与OpenAI公司竞争的模型。
Vicuna
加州大学伯克利分校、卡内基梅隆大学、斯坦福大学和加州大学圣地亚哥分校的研究人员发布了Vicuna,这是基于LLaMA的遵循指令的另一个LLM。Vicuna有70亿个和130亿个参数的两种大小。
研究人员使用Vicuna的训练代码和ShareGPT上的7万个例子对Vicuna进行了微调。ShareGPT是一个用户可以与ChatGPT分享对话的网站。他们对训练过程做了一些改进,以支持更长的对话场景。他们还使用了SkyPilot机器学习工作量管理器,将训练成本从500美元降至140美元左右。
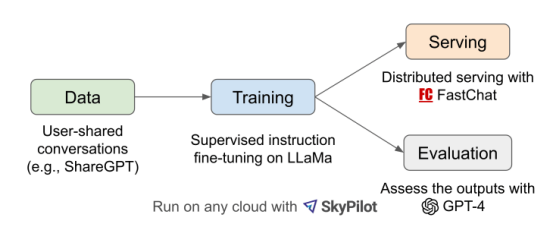
Vicuna的LLM训练流程
初步评估表明,Vicuna的表现优于LLaMA和Alpaca,也非常接近Bard和ChatGPT-4。研究人员发布了模型权重以及安装、训练和运行LLM的完整框架。还有一个非常有趣的在线演示,用户可以在其中测试和比较Vicuna与其他开源指令LLM。
Vicuna的在线演示是“仅供非商业用途的研究预览”。用户要运行自己的模型,必须首先从Meta获取LLaMA实例并对其应用权重增量。
Dolly
Databricks公司在今年3月发布了Dolly,这是EleutherAI的GPT-J 6B的微调版本。研究人员受到LLaMA和Alpaca研究团队所做工作的启发。训练Dolly的费用不到30美元,只需在一台计算机上花费30分钟训练。
EleutherAI基础模型的使用消除了Meta对LLaMA衍生LLM的限制。然而,Databricks根据Standford Alpaca团队通过ChatGPT生成的相同数据训练Dolly。因此,由于OpenAI公司对ChatGPT生成的数据施加了竞业限制,该模型仍然不能用于商业目的。
Databricks公司在今年4月发布了Dolly 2.0,这是一个基于EleutherAI的Pythia模型的具有120亿个参数的大型语言模型。这一次,Databricks公司在15000个示例数据集上对模型进行了微调,这些示例完全由人类生成。他们通过一个有趣的、游戏化的过程收集了这些例子,其中包括Databricks公司的5000名员工。
Databricks公司发布了训练有素的Dolly 2.0模型,它没有以前模型的条款限制,用户可以将它用于商业目的。Databricks公司还发布了15K指令遵循语料库,用于微调Pythia模型。机器学习工程师可以使用这个语料库来微调他们自己的LLM。
Open Assistant

Open Assistant是一个非常有趣的项目,这是一个类似于ChatGPT的语言模型,从一开始就以防止大公司垄断LLM市场为目的。
其研究团队将开放他们所有的模型、数据集、开发、数据收集等,这是一项全面、透明的社区努力结果。所有参与该项目的人员都是志愿者,致力于开放性。
观看其联合创始人兼团队负责人Yannic Kilcher的娱乐视频,可以了解Open Assistant的最佳方式。Kilcher长期以来一直直言不讳地批评OpenAI等公司采取的封闭方式。
Open Assistant有基于LLaMA和Pythia的不同版本。用户可以将Pythia版本用于商业目的。大多数模型可以在单个GPU上运行。
来自世界各地的13000多名志愿者帮助收集了用于微调基本模型的样本。该团队将很快发布所有数据以及一篇解释该项目的论文。经过训练的模型可以在Hugging Face上找到。该项目的GitHub页面包含用于训练模型和使用模型的前端的完整代码。
该项目还有一个网站,用户可以在那里与Open Assistant聊天并测试模型。它有一个任务仪表板,用户可以通过创建提示或标记输出来为项目做出贡献。
开源之美
最近推出开源LLM的努力为科技公司重振合作和共享权力的承诺做出了很大贡献,而这正是互联网最初的承诺。它展示了所有这些不同的社区如何相互帮助,共同推动这一领域的发展。
LLaMA的开源模型帮助推动了这场运动。Alpaca项目表明,创建调整指令的LLM不需要付出巨大的努力和成本。这反过来又激发了Vicuna项目的灵感,该项目进一步降低了训练和收集数据的成本。Dolly则朝着不同的方向努力,展示了社区主导的数据收集工作的好处,以解决商业模型的竞业限制要求。
当然,还有其他几个值得一提的模型,包括加州大学伯克利分校的Koala和LLaMA.cpp, LLaMA .cpp是LLaMA模型的C++实现,可以在ARM处理器上运行。在接下来的几个月,观察开源运动将如何发展以及它将如何影响LLM市场,将成为一件有趣的事情。
原文标题:A look at open-source alternatives to ChatGPT,作者:Ben Dickson