大家好,我是Echa。
最近这段时间小编陆续收到粉丝们的私信,提到的最多的问题就是有没有非常优秀的开源项目推荐,有没有AI相关的开源项目推荐,有没有的ChatGPT开源项目推荐等等。说句话实话,优化开源项目不是那么容易能找到,不是百里挑一,那也是几十挑一。即使找到了还得自身要了解,而且还得抽空搭建部署成功后,才整理出来分享给粉丝们。
小编也是随着粉丝们的意愿,百忙之中精选了9个优秀的Github 开源项目,希望对大家学习有所帮助。
全文大纲
- transformers 提供了数以千计的预训练模型
- Open Chat Video Editor 是开源的短视频生成和编辑工具
- yuzu 是基于 C++ 的 Switch 模拟器
- Ryujinx 是基于 C# 的任天堂 Switch 模拟器
- Chat2DB 一个集成了AIGC的数据库客户端工具
- privateGPT 你的私人 GPT
- WebCPM 一个使用中文预训练模型进行互动网页搜索的项目
- gpt4free 变相「开源」GPT-4
- ChatGPT-Prompt-Engineering-for-Developers-in-Chinese 面向开发者的 ChatGPT 提示词工程
transformers 提供了数以千计的预训练模型
官网:https://huggingface.co
Github:https://github.com/huggingface/transformers

Hugging Face 官网
Hugging Face,作为 AI 开源圈最为知名的「网红」创业公司,成立仅几年,便在 GitHub 开源了诸多实用开源项目,受到了不少开发者的赞赏。
其中影响力最大的,也被很多人称为初代 GPT 的 Transformers,截至今天,GitHub Star 累积将近 10 万。
这几年,在 Hugging Face 平台上面诞生了无数实用的 AI 预训练模型、数据集。数量之多,品质之高,将其说是 AI 界的 GitHub 也不为过。
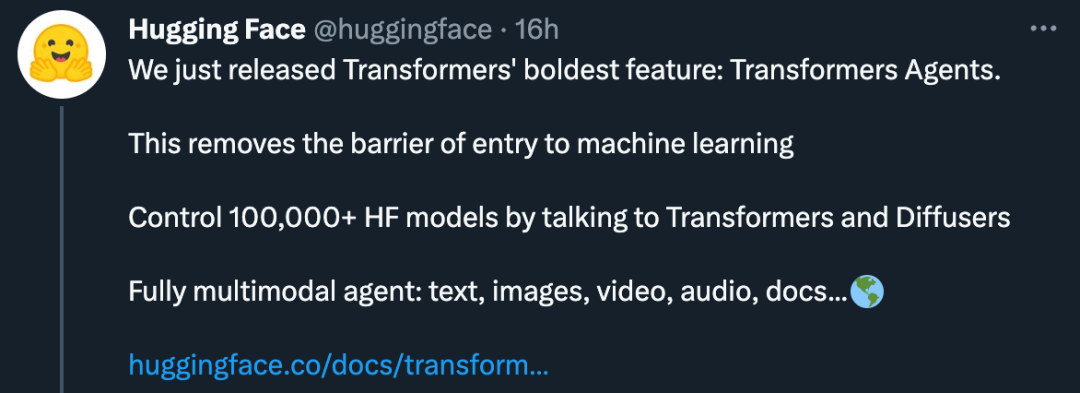
今天凌晨,Hugging Face 重磅推出 Transformers Agents,在 AI 技术圈再次掀起波澜!
所有人都可以基于该功能,轻松使用 OpenAssistant、StarCoder、OpenAI 等大语言模型,快速创建一个 AI 智能代理。
Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成。它的宗旨是让最先进的 NLP 技术人人易用。
Transformers 提供了便于快速下载和使用的API,让你可以把预训练模型用在给定文本、在你的数据集上微调然后通过 model hub 与社区共享。同时,每个定义的 Python 模块均完全独立,方便修改和快速研究实验。
Transformers 支持三个最热门的深度学习库: Jax, PyTorch 以及 TensorFlow — 并与之无缝整合。你可以直接使用一个框架训练你的模型然后用另一个加载和推理。

为什么要用 transformers?
- 便于使用的先进模型:
- NLU 和 NLG 上表现优越
- 对教学和实践友好且低门槛
- 高级抽象,只需了解三个类
- 对所有模型统一的API
- 更低计算开销,更少的碳排放:
- 研究人员可以分享已训练的模型而非每次从头开始训练
- 工程师可以减少计算用时和生产环境开销
- 数十种模型架构、两千多个预训练模型、100多种语言支持
- 对于模型生命周期的每一个部分都面面俱到:
- 训练先进的模型,只需 3 行代码
- 模型在不同深度学习框架间任意转移,随你心意
- 为训练、评估和生产选择最适合的框架,衔接无缝
- 为你的需求轻松定制专属模型和用例:
- 我们为每种模型架构提供了多个用例来复现原论文结果
- 模型内部结构保持透明一致
- 模型文件可单独使用,方便魔改和快速实验
什么情况下我不该用 transformers?
- 本库并不是模块化的神经网络工具箱。模型文件中的代码特意呈若璞玉,未经额外抽象封装,以便研究人员快速迭代魔改而不致溺于抽象和文件跳转之中。
- Trainer API 并非兼容任何模型,只为本库之模型优化。若是在寻找适用于通用机器学习的训练循环实现,请另觅他库。
- 尽管我们已尽力而为,examples 目录中的脚本也仅为用例而已。对于你的特定问题,它们并不一定开箱即用,可能需要改几行代码以适之。

Transformers Agents 里面提供了诸多实用的工具,包括目前 AI 技术应用广泛的文档问答、文本转语音、文本生成图像、网站内容总结、图像分割等一系列工具。
开发者只需完成工具链组装,即可实现许多强大的功能。
比如,你可以通过它,快速实现这么一个功能:
用脚本根据链接,自动抓取某篇文章内容,并生成摘要,再将其翻译成任意一种语言,让 AI 朗读稿件,有需要的话,你还可以让代理为你生成一张配图。
一个基于 AI 能力,可快速报道各种新鲜资讯的播客系统,便能横空出世!
如下图:

transformers 实现流程图
Open Chat Video Editor
Github:https://github.com/SCUTlihaoyu/open-chat-video-editor
Open Chat Video Editor 是基于 AI 的短视频创作工具,解放你的生产力。基于 ChatGPT、Alpaca 等大模型,可以将短文本、网页链接一键转成短视频。
如下图是技术框架图:整体流程是将短文本输入到模型,来生成文案。通过图像搜索、图像 AI 生成技术来寻找配图,通过视频搜索、视频生成等技术来找合适的视频片段,最终通过语音合成、BGM 匹配、字幕合成打造一个短视频作品。
Open Chat Video Editor是开源的短视频生成和编辑工具,整体技术框架如下:
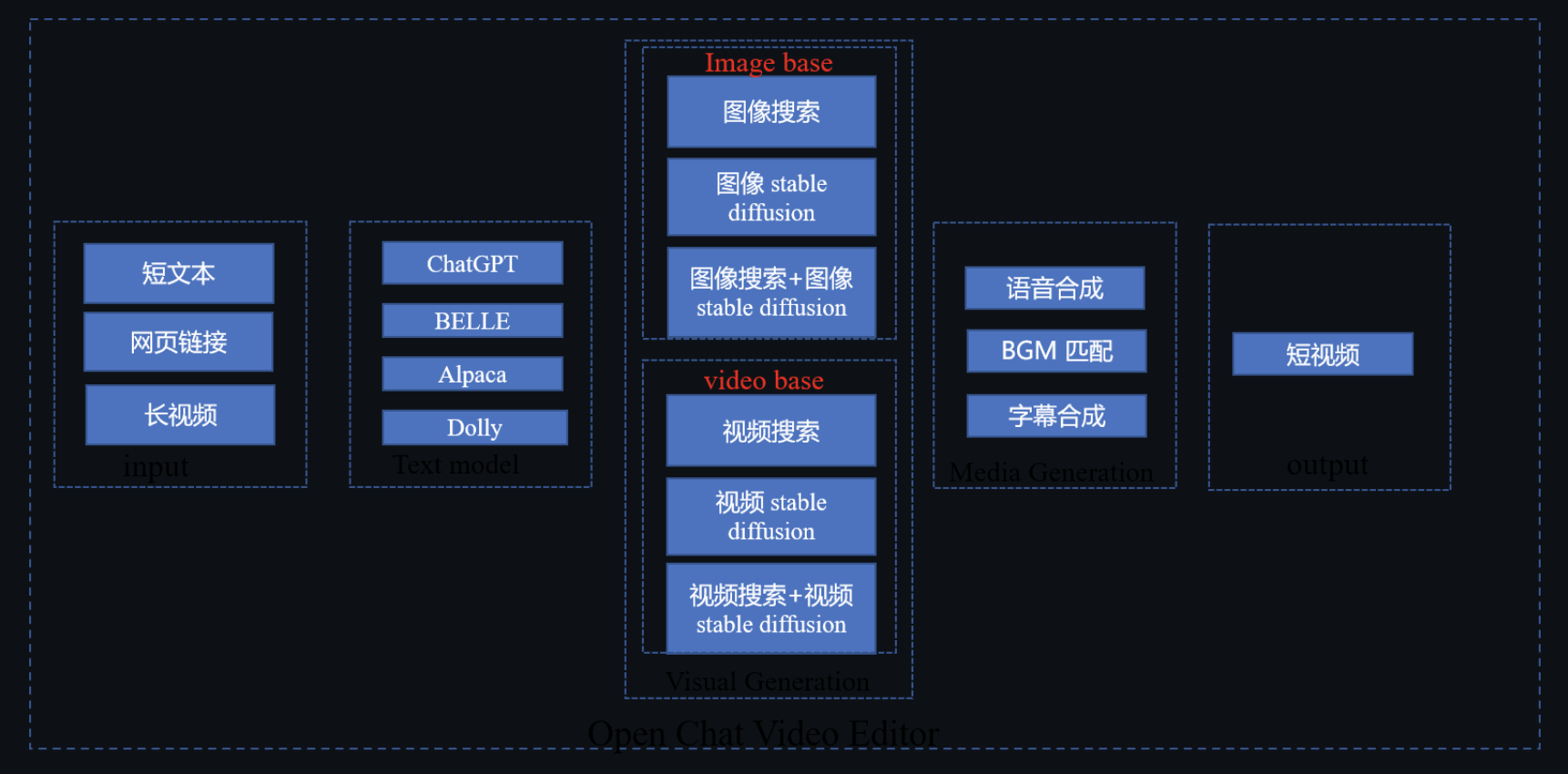
Open Chat Video Editor 技术框架
特性
- windows、linux不同系统更方便的install指引
- 创建docker,方便大家一键使用
- 能够在线直接快速体验的url
- 在短视频文案数据上对文本模型finetune,支持更多的文案风格
- finetune SD模型,提升图像和视频的生成效果
目前具有以下特点:
- 1)一键生成可用的短视频,包括:配音、背景音乐、字幕等。
- 2)算法和数据均基于开源项目,方便技术交流和学习
- 3)支持多种输入数据,方便对各种各样的数据,一键转短视频,目前支持:
- 短句转短视频(Text2Video): 根据输入的简短文字,生成短视频文案,并合成短视频
- 网页链接转短视频(Url2Video): 自动对网页的内容进行提取,生成视频文案,并生成短视频
- 长视频转短视频(Long Video to Short Video): 对输入的长视频进行分析和摘要,并生成短视频
- 4)涵盖生成模型和多模态检索模型等多种主流算法和模型,如: Chatgpt,Stable Diffusion,CLIP 等
文本生成上,支持:
- ChatGPT
- BELLE
- Alpaca
- Dolly 等多种模型
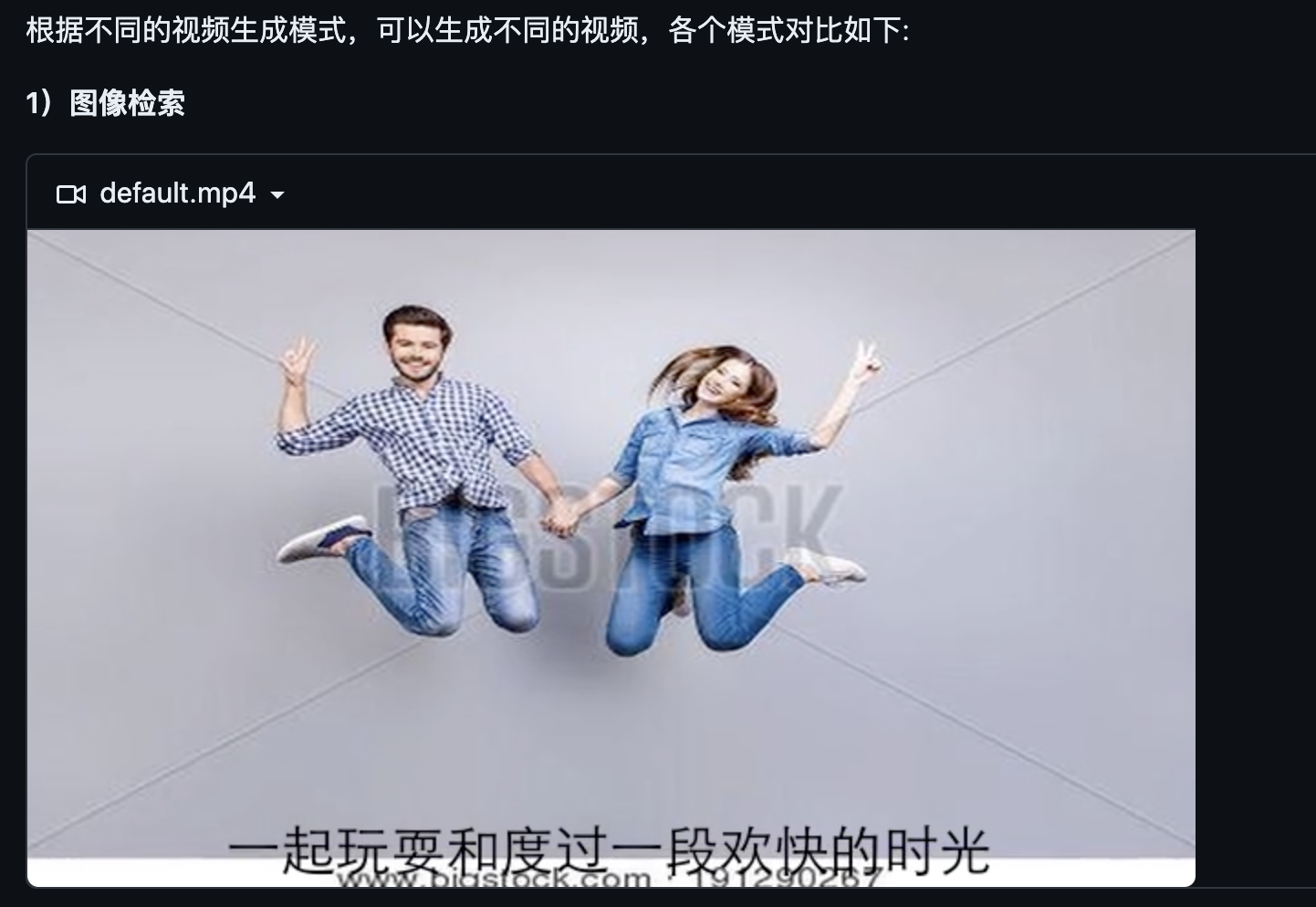
视觉信息生成上,支持图像和视频两种模态,生成方式上,支持检索和生成两种模型,目前共有6种模式:
- 图像检索
- 图像生成(stable diffusion)
- 先图像检索,再基于stable diffusion 进行图像生成
- 视频检索
- 视频生成(stable diffusion)
- 视频检索后,再基于stable diffusion 进行视频生成
效果图如下:
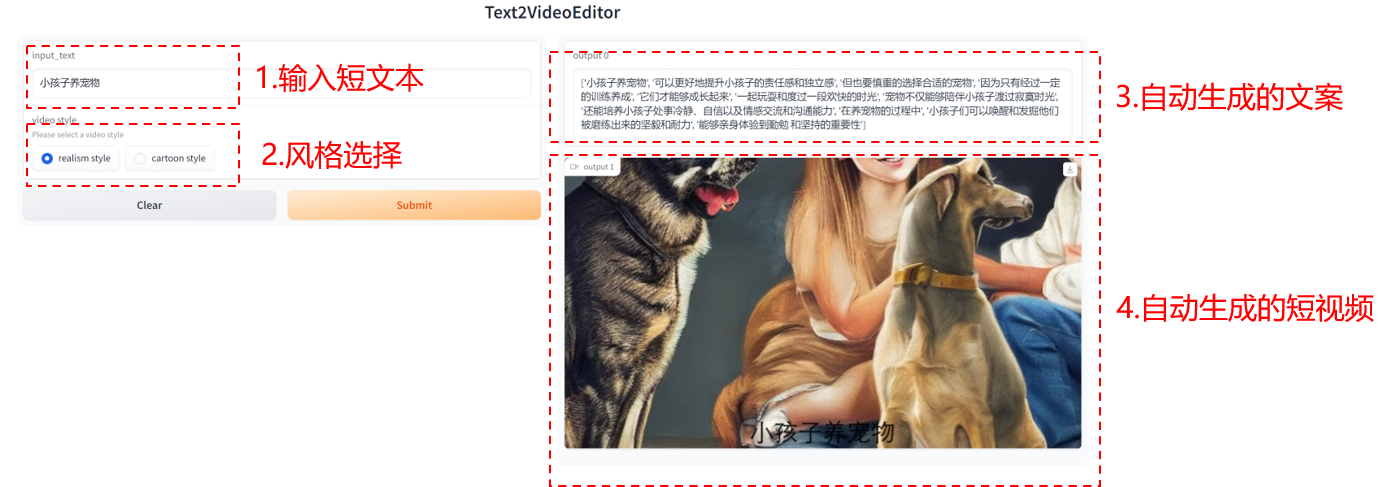
短句转短视频

yuzu 是基于 C++ 的 Switch 模拟器
官网:https://yuzu-emu.org/
Github: https://github.com/yuzu-emu/yuzu
yuzu是世界上最受欢迎的开源任天堂Switch模拟器,由Citra的创建者创建。
它是用C++编写的,考虑到了可移植性,我们积极维护Windows和Linux的构建。
应该是因为 塞尔达·王国之类 游戏的发布, Switch 模拟器相关的开源项目都登上了 GitHub 热榜。
yuzu 是基于 C++ 的 Switch 模拟器,能够在 Windows、Linux 上运行模拟 Switch 游戏,目前已经获得了 26K 的 Star。
Ryujinx 是基于 C# 的任天堂 Switch 模拟器
官网:https://ryujinx.org/
Github: https://github.com/Ryujinx/Ryujinx
应该是因为 塞尔达·王国之类 游戏的发布, Switch 模拟器相关的开源项目都登上了 GitHub 热榜。
其中,Ryujinx 是基于 C# 的任天堂 Switch 模拟器,通过这个模拟器你能在 Windows 上玩 Switch 上的游戏,目前已经获得了 21.7K 的 Star。
Chat2DB 一个集成了AIGC的数据库客户端工具
官网:http://www.sqlgpt.cn/
Github:https://github.com/alibaba/Chat2DB
Chat2DB 是一款有开源免费的多数据库客户端工具,支持windows、mac本地安装,也支持服务器端部署,web网页访问。和传统的数据库客户端软件Navicat、DBeaver 相比Chat2DB集成了AIGC的能力,能够将自然语言转换为SQL,也可以将SQL转换为自然语言,可以给出研发人员SQL的优化建议,极大的提升人员的效率,是AI时代数据库研发人员的利器,未来即使不懂SQL的运营业务也可以使用快速查询业务数据、生成报表能力。
✨特性
- AI智能助手,支持自然语言转SQL、SQL转自然语言、SQL优化建议
- 支持团队协作,研发无需知道线上数据库密码,解决企业数据库账号安全问题
- ⚙️ 强大的数据管理能力,支持数据表、视图、存储过程、函数、触发器、索引、序列、用户、角色、授权等管理
- 强大的扩展能力,目前已经支持MySQL、PostgreSQL、Oracle、SQLServer、ClickHouse、OceanBase、H2、SQLite等等,未来会支持更多的数据库
- 前端使用 Electron 开发,提供 Windows、Mac、Linux 客户端、网页版本一体化的解决方案
- 支持环境隔离、线上、日常数据权限分离

privateGPT 你的私人 GPT
Github:https://github.com/imartinez/privateGPT
privateGPT 开源两周,便斩获了 10K 的 Star。可以在离线的情况下,使用 GPT 来处理你的私人文档,完全不需要网络,本地化运行。
让 privateGPT 处理你的文档,然后就能通过对话的方式让 GPT 分析文档给出答案。

WebCPM 一个使用中文预训练模型进行互动网页搜索的项目
Github:https://github.com/thunlp/WebCPM
2021 年 12 月,OpenAI 正式推出 WebGPT,该项目的横空出世,标志着基于网页搜索的问答新范式的诞生。
在此之后,New Bing 首先将网页搜索功能整合发布,随后 OpenAI 也发布了支持联网的插件 ChatGPT Plugins。
大模型在联网功能的加持下,回答问题的实时性和准确性都得到了飞跃式增强。
近期,面壁智能联合来自清华、人大、腾讯的研究人员共同发布了 中文领域首个基于交互式网页搜索的问答开源模型框架 WebCPM,相关工作录用于自然语言处理顶级会议 ACL 2023。
WebCPM 是面壁智能自研大模型工具学习引擎 BMTools 的首个成功实践,其特点在于其信息检索基于交互式网页搜索,能够像人类一样与搜索引擎交互从而收集回答问题所需要的事实性知识并生成答案。
WebCPM 背后的基础模型 CPM 是由面壁智能与 OpenBMB 开源社区开发的百亿参数中文语言模型,占据多个中文领域语言模型排行榜前列。

WebCPM 研究背景
在当今信息化时代,人们在日常生活和工作中,需要不断地获取各种知识和信息,而这些信息往往分散在互联网上的海量数据中。
如何快速、准确地获取这些信息,并且对这些信息进行合理的整合,从而回答复杂、开放式问题,是一个极具挑战性的问题。长文本开放问答(Long-form Question Answering, LFQA)模型就是为了回答这种复杂的问题而设计的。
目前的 LFQA 解决方案通常采用 检索-综合 范式,包括信息检索和信息综合两个核心环节。信息检索环节从外部知识源(如搜索引擎)中搜索多样化的相关支持事实,信息综合环节则将搜集到的事实整合成一个连贯的答案。
然而,传统的 LFQA 范式存在一个缺陷:它通常依赖于非交互式的检索方法,即 仅使用原始问题作为查询语句来检索信息。
相反,人类能够通过与搜索引擎 实时交互 来进行网页搜索而筛选高质量信息。对于复杂问题,人类往往将其分解成多个子问题并依次提问。通过识别和浏览相关信息,人类逐渐完善对原问题的理解,并不断查询新问题来搜索更多样的信息。
这种迭代的搜索过程有助于扩大搜索范围,提高搜索结果质量。总体而言,交互式网页搜索不仅为我们提供了获取多样化信息来源的途径,同时也反映了人类解决问题的认知过程,从而提高了可解释性。
2021 年 12 月 OpenAI 发布 WebGPT,这是支持 LFQA 的交互式网页搜索的一项先驱性工作。
作者首先构建了一个由微软必应搜索(Bing)支持的网页搜索界面,然后招募标注员使用该界面收集信息来回答问题。
之后,他们微调 GPT-3 模型,让其模仿人类的搜索行为,并将收集到的信息整理成答案。实验结果显示,WebGPT 在 LFQA 任务具备出色的能力,甚至超过了人类专家。
同时,WebGPT 也是微软近期推出的 New Bing 背后的新一代搜索技术。
尽管效果十分惊人,但 WebGPT 、New Bing 对学术圈和工业界来说仍然充满神秘感。这是因为 WebGPT 的相关细节并未完全公开,其核心设计元素的工作原理也不透明。
鉴于当前交互式网页搜索的重要价值,我们迫切需要一个标准数据集与相关的开源模型以支持后续研究。
WebCPM 搜索交互界面和数据集
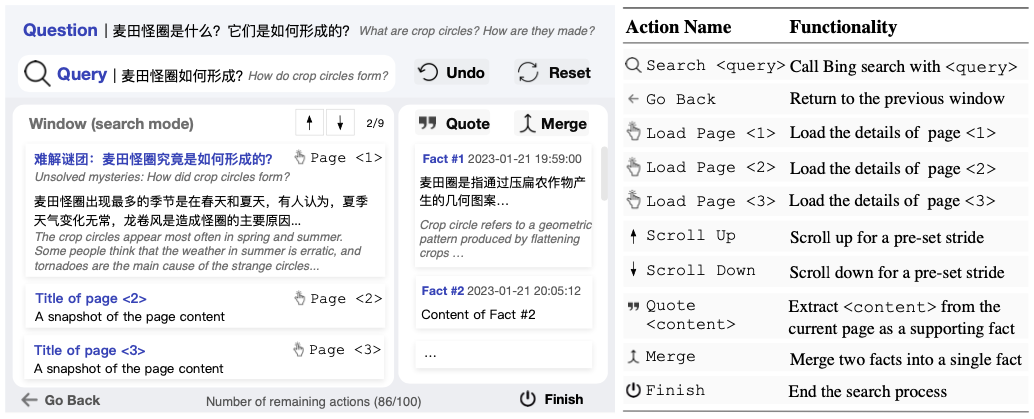
WebCPM 搜索交互界面和数据集
为推动相关领域发展,这篇 ACL 论文的研究团队首先构建了一个 开源的交互式网页搜索界面,用于记录人类为开放式问题收集相关信息时的网页搜索行为。
该界面底层调用必应搜索 API 支持网页搜索功能,囊括 10 种主流网页搜索操作(如点击页面、返回等等)。
在这个界面中,用户可以执行预定义的操作来进行多轮搜索和浏览。在找到网页上的相关信息时,他们可以将其作为支持事实记录下来。
当收集到足够的信息后,用户可以完成网页搜索,并根据收集到的事实来回答问题。同时,界面会自动记录用户的网页浏览行为,用于构建 WebCPM 数据集。
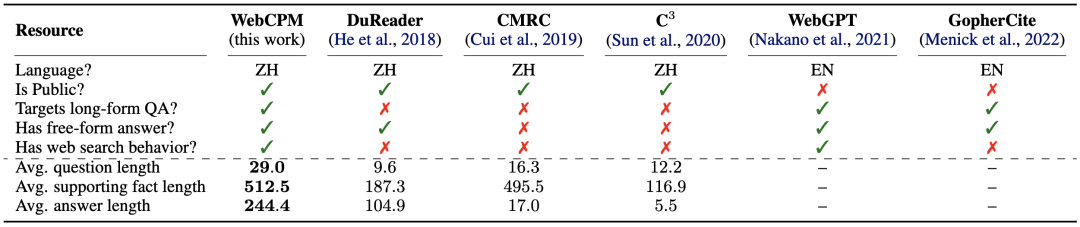
WebCPM 数据集与相关问答数据集的比较
基于这个界面,作者构建了中文领域首个基于交互式网页搜索的 LFQA 数据集。
它包含 5,500 对高质量的问题-答案对以及十万多条真实用户网页搜索行为。与现有的中文问答数据集相比,WebCPM 的问题、支持事实和答案都更长,体现了其问题的复杂性和答案内容的丰富性。
WebCPM 模型框架
作者提出了的 WebCPM 框架包括:(1)搜索模型与(2)答案综合模型。
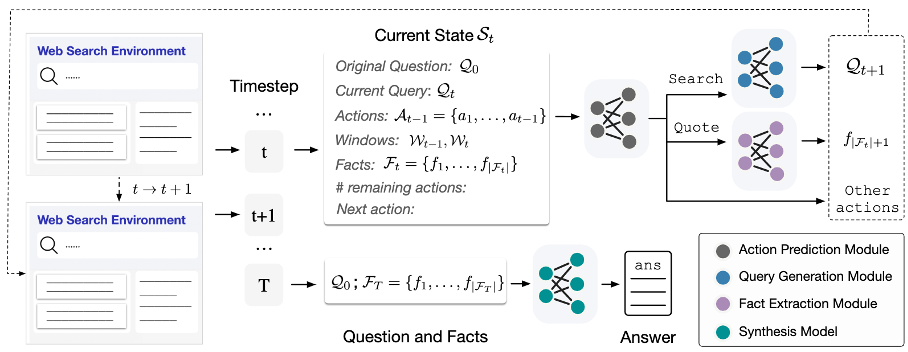
WebCPM 模型框架
搜索模型
该模型模仿人类网页搜索行为、与搜索引擎交互并进行信息检索。作者将网页搜索任务划分为 3 个子任务:
- 搜索行为预测(action prediction);
- 查询语句生成(search query generation);
- 支持事实摘要(supporting fact extraction)。
答案综合模型
该模型根据原问题与收集到的事实生成连贯的答案。然而与人类不同,经过训练的搜索模型偶尔会收集到不相关的噪声,这将影响生成答案的质量。
为了解决这一问题,作者在答案综合模型的训练数据中引入噪声,使其具备一定的去噪的能力,从而忽略不相关的事实,只关注重要的事实以生成答案。
WebCPM 实验评测
作者首先对每个子模块分别评估,然后,将所有模块组合起来形成整体的 pipeline,并测试其效果。最后,作者对每个模块的性能进行深入分析。
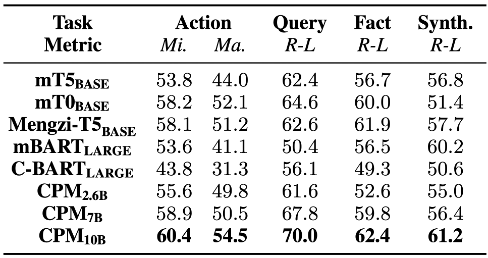
单个子任务的性能评估结果,作者测试了包括 CPM 模型在内的多个有代表性的中文大模型
- 单个子任务评估
作者测试了多个有代表性的中文大模型,并得出以下结论(结果如上图所示):不同模型在四个子任务上的性能各有优劣。
例如在搜索行为预测、查询语句生成和支持事实摘要中,mT0 的表现优于 mT5,但在综合信息方面表现较差。
此外,CPM 系列模型的性能随着模型参数量的增加也不断提高。得益于 scaling law ,更大的模型通常拥有更强的理解和生成能力,能表现出更好的下游任务性能。
- 整体 pipeline 评测
对于每个测试问题,作者比较了模型(CPM 10B 模型)和人类用户使用搜索引擎回答问题和做相同任务的表现,并进行人工评测。
具体而言,给定一个问题和模型与人类分别给出的答案,标注员将根据多个因素(包括答案整体实用性、连贯性和与问题的相关性)决定哪个答案更好。
从下图(a)的结果可以得出以下结论:模型生成的答案在 30%+ 的情况下与人写的答案相当或更优。
这个结果表明整个问答系统的性能在未来仍有巨大的提升空间(例如训练性能更加强大的基底模型);当将人工收集的事实应用于信息综合模型时,性能提高到了45%,这可以归因于收集的事实质量的提高。
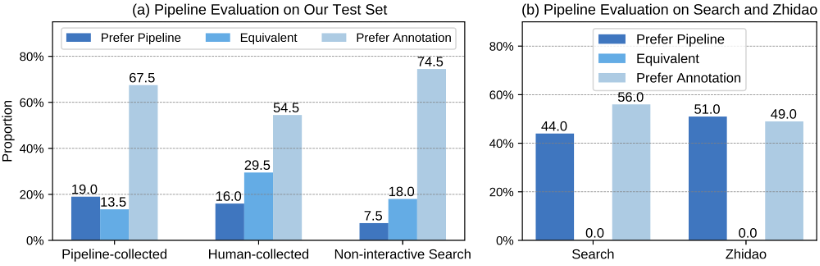
整体 pipeline 评测效果,作者测试了 WebCPM 数据集和 DuReader 数据集
此外,作者也将整体 pipeline 应用于 DuReader 中文 QA 数据集(包含 Zhidao 和 Search 两个子数据集),并比较了模型生成的答案和人工标注的答案,从上图(b)可以观察到模型生成的答案比 DuReader 标注答案更好的情况接近 50%,这反映了该模型强大的泛化能力,体现了WebCPM 数据标注的高质量。
WebCPM 案例分析
为了探究查询模块所学习到的人类行为,作者抽样不同测试问题生成的查询语句来进行案例分析。下图展示了部分结果,以研究查询模块的性能。
可以看出,该模块已经学会了复制原始问题,将问题分解为多个子问题,用相关术语改写问题等多种人类搜索策略。这些策略使查询语句更加多样化,有助于从更多的来源收集更丰富的信息。

WebCPM 成功实践 BMTools
近年来,大模型在诸多领域展现出惊人的应用价值,持续刷新各类下游任务的效果上限。尽管大模型在很多方面取得了显著的成果,但在特定领域的任务上,仍然存在一定的局限性。
这些任务往往需要专业化的工具或领域知识才能有效解决。因此,大模型需要具备调用各种专业化工具的能力,这样才能为现实世界任务提供更为全面的支持。
gpt4free 变相「开源」GPT-4
官网:
https://discord.gg/gpt4free
Github:https://github.com/xtekky/gpt4free

图片来自网络
众所周知,ChatGPT 是免费的,但想尝试最新最强的 GPT-4,基本上就只有「氪金」这一条路可以走——
要么订阅 ChatGPT Plus,要么付费调用 API。
虽然也有一些集成了 GPT 的网站,比如微软的必应、You.com 等,但他们多少都会夹带点私货。
那么,如果想体验更加原生的 GPT-4,但又不想花钱怎么办?
最近,一个名为 GPT 4 Free 项目横空出世。不仅在 GitHub 上斩获 18.5 k 星,而且登上了 Trending 周榜。
然而,制作这个项目的 CS 学生 Xtekky 却表示,OpenAI 现在要求他在五天内关闭整个项目,否则将面临诉讼。

这其中的矛盾在于,GPT 4 Free 所使用的这些网站本身,都是给 OpenAI 支付了大量费用,才用上的 GPT 模型。
因此,通过脚本进来的查询,网站不仅要掏腰包买单,而且自己还没得到任何流量。
如果这个网站是依靠广告收入来抵消 API 使用成本的话,那么这一通操作下来,就有可能会赔钱。
变相「开源」GPT-4
现在,想要用上 GPT-4,除了直接充会员外,就只能排队等 API,然后继续氪金……
而 GPT 4 Free,则可以让我们通过 You.com、Quora 和 CoCalc 等网站,免费使(bai)用(piao)GPT-4 和 GPT-3.5 模型。
同时,GPT 4 Free 配置起来也非常简单。
首先,在电脑上的 WSL 2(Windows Subsystem for Linux)安装 GPT 4 Free。这只需要几分钟,包括克隆 GitHub 仓库,使用 pip 安装一些必需的库,以及运行一个 Python 脚本。
启动脚本后,使用浏览器访问 http://localhost:8501,就可以获得一个聊天机器人了。
ChatGPT-Prompt-Engineering-for-Developers-in-Chinese 面向开发者的 ChatGPT 提示词工程
Github:https://github.com/GitHubDaily/ChatGPT-Prompt-Engineering-for-Developers-in-Chinese

ChatGPT 上线至今,已经快 5 个月了,但是不少人还没真正掌握它的使用技巧。
其实,ChatGPT 的难点,在于 Prompt(提示词)的编写,OpenAI 创始人在今年 2 月时,在 Twitter 上说:「能够出色编写 Prompt 跟聊天机器人对话,是一项能令人惊艳的高杠杆技能」。
因为从 ChatGPT 发布之后,如何写好 Prompt 已经成为了一个分水岭。熟练掌握 Prompt 编写的人,能够很快让 ChatGPT 理解需求,并很好的执行任务。
目前你在网上看到的所有 AI 助理、智能翻译、角色扮演,本质上还是通过编写 Prompt 来实现。
只要你的 Prompt 写的足够好,ChatGPT 可以帮你快速完成很多工作,包括写爬虫脚本、金融数据分析、文案润色与翻译等等,并且这些工作还做的比一般人出色。
之前我经常听到有同学抱怨,说 ChatGPT 也就那样,我说一句他回一句,并没有网上说的那么厉害,其实,你确定真正掌握 Prompt 应用了吗?
打个比方,至今还有不少人,不知道在给 ChatGPT 提供代码或者翻译文本时,需要使用引号分隔符来传给 ChatGPT,让它输出更准确的结果。
为了帮助大家能更好的掌握 Prompt 工程,DeepLearning.ai 创始人吴恩达与 OpenAI 开发者 Iza Fulford 联手推出了一门面向开发者的技术教程:《ChatGPT 提示工程》。
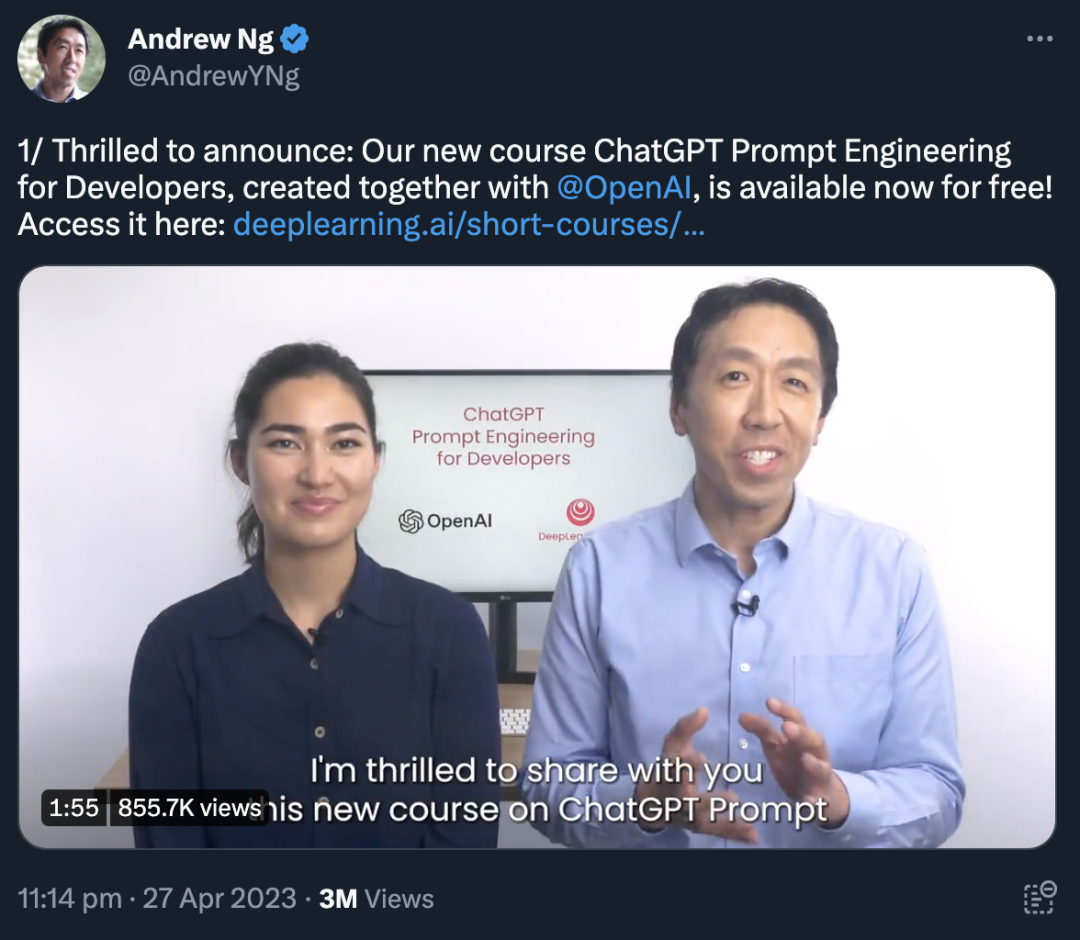
吴恩达老师相信大家都有所耳闻,作为人工智能界的重量级大佬,我们经常能在 AI 技术界看到他活跃的身影。
另一位讲师 Iza Fulford,大家可能不太熟悉,这里重点介绍下。
她是斯坦福本硕高材生,ChatGPT 之前在 GitHub 开源的那个文档搜索插件:Retrieval,就是出自她之手。
另外,她还是 OpenAI Cookbook(官方手册)的编撰者,如果你最近有深入了解过 GPT 相关的技术,那这本手册于你而言应该不会陌生。
该手册里面提供了大量 GPT 相关的使用案例,能帮助你快速上手并掌握 GPT 模型的开发与应用。
可以说,这两位大佬联手,推出的教程绝对不会差。更令人振奋的是,这个教程完全对外开放,所有人均可免费学习!
那么,这个教程里面主要讲了什么内容呢?
该教程总共分为 9 个章节,总一个多小时,里面主要涵盖:提示词最佳实践、评论情感分类、文本总结、邮件撰写、文本翻译、快速搭建一个聊天机器人等等。
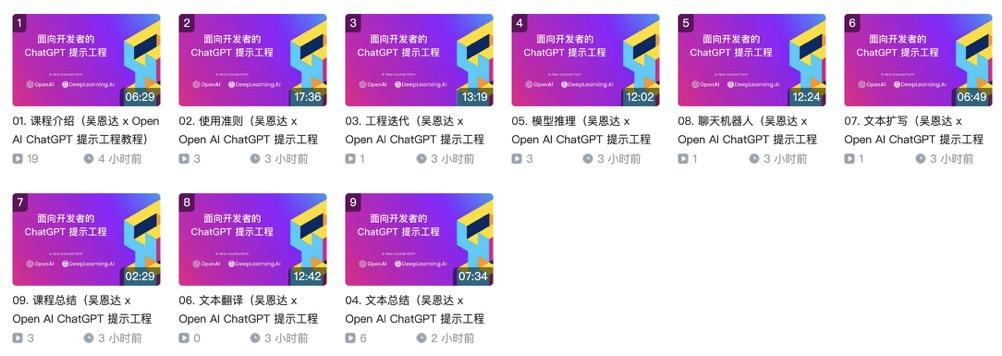
所以当下 ChatGPT 的流行案例,你都能在这个教程里面找到,十分全面!
除了能在这个教程里面学到如何使用 Prompt,你还能学到 GPT 接口调用开发知识。有需要的话,你甚至能在这个教程之上去延伸扩展,搭建出一款令人惊艳的应用。
目前该教程已经在 DeepLearning.ai 正式上线,官网上线提供了可交互式的 Notebook,让你可以一边学习,一边跟着编写代码实践。
不过当下这个教程只有英文版,为了让看不懂英文的同学也能第一时间学习并掌握这项技术。