













年少往事
记得刚学数据链表的时候,老师是不是说,读多写少用数组,写多读少用链表,但你有没有想过多少才算多?我也有这个疑问,刚好今天有时间,借这个话题一起探讨,ArrayList和LinkedList选择之写操作。
磁盘IO
我们都知道,磁盘IO以块为单位读取数据,如果你所需要的数据都存储在一个块呢,一次IO即可返回。如果跨越多个块,只要你的块是连续的,类似MYSQl,基于预读机制,一次读取多个块的数据。这明显利好数组,因为数组申请内存的时候,大小是固定且连续的。如果是链表,它的数据随机散落在不同的块,意味着磁盘IO很快。
小结
- 数组读性能好是因为数据顺序存储,一次IO即可返回
- 链表读性能差是因为数据随机存储,多次IO才能返回
扩容
我们都知道,ArrayList存在扩容问题,在频繁写入的时候,会因为容量不足需要重写开辟新的数组空间,然后复制原数组数据到新的数组,这个过程消耗大量内存,这也是提出写多用链表的原因。
那么,是不是只要写多就用链表?这个回答显然是否定的,不然没有探讨的意义。下面我们看看大数据量下两者写入差异。
小试牛刀,500万数据看看
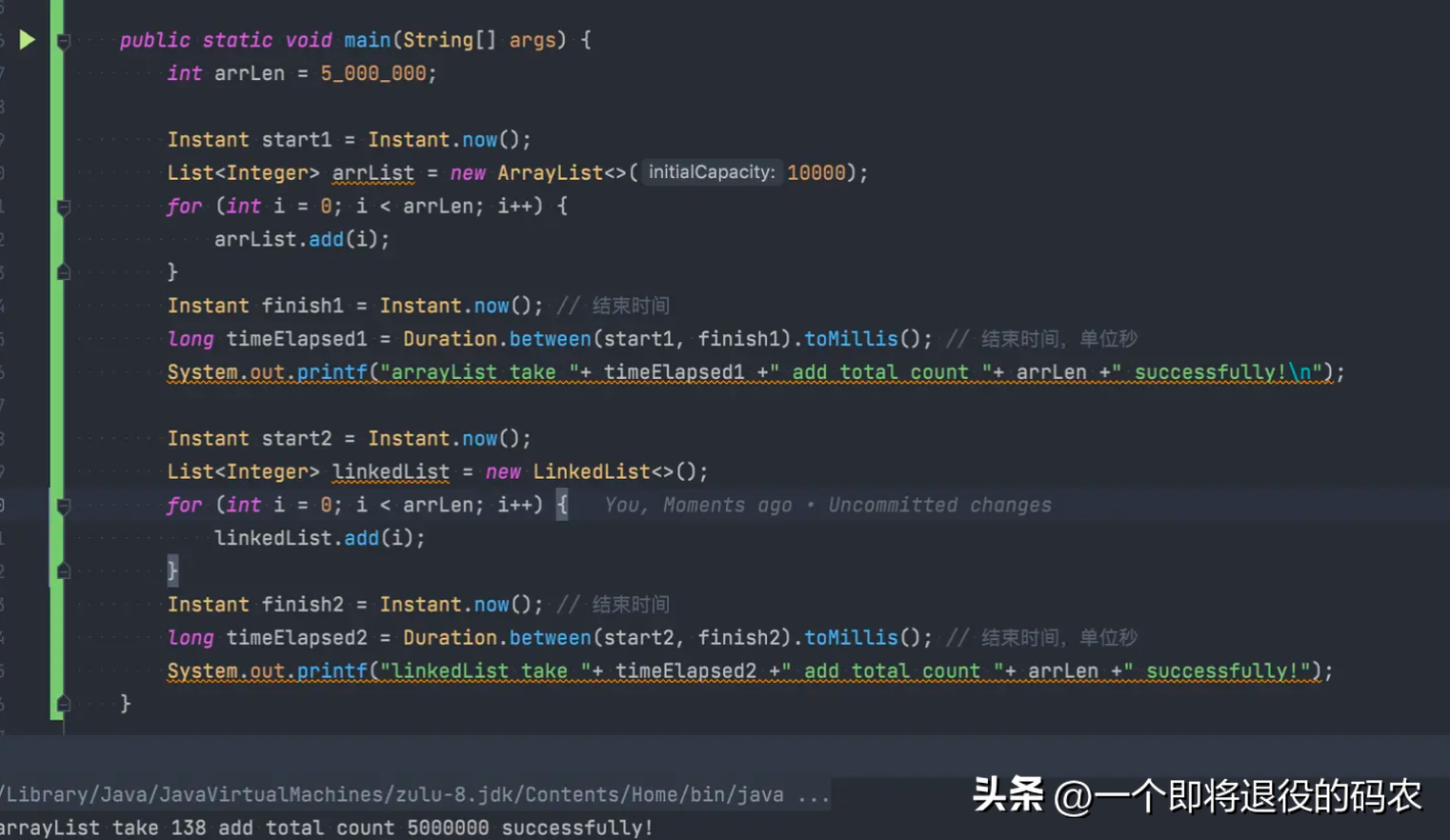
ArrayList初始容量1万,循环插入500万数据,扩容9次,用时138ms,LinkedList只需要不停创建节点,将节点next绑定即可,但用时724ms,差距5倍多。
小结
500万数据写入,用ArrayList是上策。不过能接触到这么多数据量的情况并不多,实际使用以实际情况为准,多测测你的业务和机器选择比较好,不过对于我来说,优先考虑ArrayList,因为从GC的角度来说,顺序存储利于GC,不管是CMS还是G1。
加量-1千万

可以看到,一千万数据量依然有接近3倍的差异,看到这你还犹豫什么,无脑ArrayList
2千万

没想到2千万就被反超了,但是你以为这样会说服我使用LinkedList吗,我只能说Naive
3千万

已持平!
4千万

重新反超,这么大的数据量下,linkedList创建大量node,比需要开辟新数组内存的arrayList消耗的时间更多,内存也更多,不信Jmap看看?而arrayList可是扩容了12次
结论
没得出什么牛逼结论,反而看出两个list在大数据量情况下,性能不是一定谁更好,可能是两条有多个交点的曲线。在选择上,无脑arrayList,如果是重要场景,最好根据业务和机器配置选择合适的。但业务会增长,摸着良心问自己,业务增长到另一个交点的时候,你会改过来吗!


















