译者 | 朱先忠
审校 | 重楼
大家好!在这篇文章中,我们将使用MONAI最新的开源扩展——MONAI生成式模型来创建一个潜在扩散模型(Latent Diffusion Model),并通过此模型生成胸部X射线图像!
简介
生成式人工智能在医疗保健方面展现出巨大的潜力,因为它允许我们创建模型来学习训练数据集的基本模式和结构。通过这种方式,我们可以使用这些生成式模型来创建无数的合成数据,这些数据具有与真实数据相同的细节和特征,并且不受到这些内容的具体限制。鉴于其重要性,我们创建了MONAI生成模型,这是包含时下众多最新模型(如扩散模型、自回归转换器和生成对抗性网络)和有助于训练和评估生成模型相应组件的MONAI平台的一个开源扩展。

MONAI生成模型
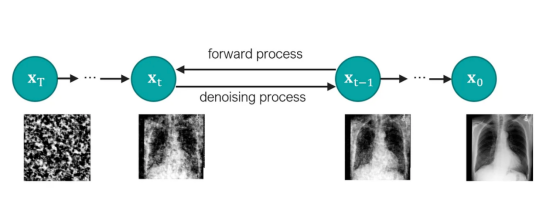
在这篇文章中,我们将通过一个完整的项目来创建一个潜在扩散模型(与Stable Diffusion相同类型的模型),该模型能够从放射学报告中生成胸部X射线(CXR)图像。在本文中,我们试图使代码易于理解并适应不同的开发环境;所以,尽管它可能不是最高效的,但我希望您喜欢它!
您可以在GitHub存储库中找到文中完整的开源项目。另外,请注意:在本文中,我们引用的是其版本0.2。
下载数据集
首先,我们从数据集开始讨论。在这个项目中,我们使用的是MIMIC数据集。要访问此数据集,需要先在Physionet门户网站上创建一个帐户。我们将使用MIMIC-CXR-JPG(包含JPG文件)和MIMIC-CXR(包含放射学报告)。这两个数据集都是在PhysioNet认证健康数据许可证1.5.0下发行。值得注意的是,在您完成免费的培训课程后,您即可以根据数据集页面底部的说明自由下载数据集。最初,CXR图像的像素约为+1000x1000。因此,下载过程可能需要一段时间。
胸部X光图像是一种重要的工具,可以提供有关胸腔内包括肺、心脏和血管等结构和器官的极为宝贵的信息,下载后,我们应该有超过35万张图像!这些图像对应于三种不同角度的投影之一:后-前(PA)、前-后(AP)和侧面(LAT)。
对于本文中这个试验项目来说,我们只对PA投影感兴趣,这是最常见角度的投影,我们可以在其中可视化放射学报告中提到的大多数特征(包括96162张图像)。关于这些报告,我们共有85882个文件,每个文件都包含几个文本部分。在这里,我们将使用调查结果(主要解释图像中的内容)和印象(总结报告的内容,就像下结论一样)数据。
为了使我们的模型和训练过程更易于管理,我们将重新调整一下图像的大小,使其在最小轴上具有512个像素。自动执行这些初始步骤的脚本列表可以在链接https://github.com/Warvito/generative_chestxray#preprocessing处找到。
开发模型
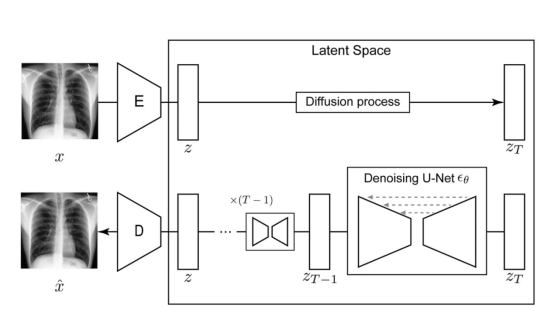
潜在扩散模型(Latent Diffusion Model)架构:自动编码器将输入图像x压缩为潜在表示z,然后通过扩散模型来估计z的概率分布。
我们所要使用的潜在扩散模型由如下几个部分组成:
- 自动编码器:用于将输入的图像压缩为较小的潜在表示;
- 扩散模型:其将学习CXR的潜在表示的概率数据分布;
- 一个文本编码器:它创建一个嵌入向量,用于调节采样过程。在本文这个例子中,我们使用的是一个经过预训练的例子。
借助于MONAI生成模型,我们可以轻松创建和训练这些模型。所以,让我们从自动编码器(Autoencoder)开始介绍!
使用具有KL正则化的自动编码器
具有KL正则化的自动编码器(AE-KL,在一些项目中,简称为VAE)的主要目标是能够创建小的潜在表示,并以高保真度重建图像(保留尽可能多的细节)。在这个项目中,我们正在创建一个具有四个级别的自动编码器,包括64128128128个通道,在每个级别之间应用下采样块,使特征图在进入最深层时更小。
尽管我们的自动编码器可能有自我注意功能的块,但在这个例子中,我们采用了与我们之前对大脑图像的研究类似的结构,并且不使用注意力机制来节省内存使用。最后,我们的潜在表示有三个通道。
注意:在我们的脚本中,我们使用OmegaConf包来存储我们模型的超参数。您可以在此文件中看到以前的配置。总之,OmegaConf是一个强大的工具,用于管理Python项目中的配置,特别是那些涉及深度学习或其他复杂软件系统的项目。OmegaConf允许我们方便地组织.yaml文件中的超参数,并在脚本中读取它们。
训练AE-KL
接下来,我们定义了训练过程的几个组成部分。首先,我们使用KL规则化。该部分负责评估扩散模型的潜在空间分布与高斯分布之间的距离。正如Rombach等人所提出的,这将用于限制潜在空间的方差,当我们在其上训练扩散模型时,这是非常有用的(稍后将详细介绍)。我们模型中的forward方法返回重构,以及我们用于计算KL散度的潜在表示的μ和σ向量。
其次,我们的模型中使用了像素级损失算法。在这个项目中,我们采用L1距离来评估我们的AE-kl重构与原始图像的差异。
接下来,我们的模型中还使用了感知级别层(Perceptual-level)的损失计算。感知损失的想法是,我们不是在像素级别评估输入图像和重构之间的差异,而是通过预先训练的模型来传递这两个图像。然后,我们测量内部激活和特征图的距离。在MONAI生成式模型中,我们可以轻松使用基于医学图像预训练网络的感知网络(可从链接https://github.com/Project-MONAI/GenerativeModels/blob/main/generative/losses/perceptual.py处找到)。我们可以访问RadImageNet研究中的2D网络(来自Mei等人),该研究对130多万张医学图像进行了训练!我们实现了2.5D方法,使用2D预训练网络通过评估切片来评估3D图像。最后,我们可以访问MedicalNet,以3D纯方法评估我们的3D图像。在这个项目中,我们使用了与Pinaya等人类似的方法,并使用了学习感知图像块相似性(LPIPS:Learned Perceptual Image Patch Similarity)度量(也可在MONAI生成式模型上获得)。
最后,我们使用对抗性损失计算来处理重构的细节。对抗性网络是一个补丁鉴别器(Patch-Discriminator,最初由Pix2Pix研究提出),我们对图像中的几个补丁进行预测,而不是对整个图像是真是假只有一个预测。
与原始的潜在扩散模型和稳定扩散不同,我们使用了来自最小二乘GAN的鉴别器损失。尽管这不是更高级的对抗性损失,但在3D医学图像上训练时,它也显示出了有效性和稳定性(但仍有改进的空间)。尽管对抗性损失可能非常不稳定,但它们与感知损失的结合也有助于稳定鉴别器和生成器的损失。
我们的训练循环和评估步骤可以从链接https://github.com/Warvito/generative_chestxray/blob/83f6c0892c63a1cdbf308ff654d40afc0af51bab/src/python/training/training_functions.py#L129和链接https://github.com/Warvito/generative_chestxray/blob/83f6c0892c63a1cdbf308ff654d40afc0af51bab/src/python/training/training_functions.py#L236处找到。在训练了共75次之后,我们用MLflow包保存我们的模型。我们使用MLflow包来更好地监控我们的实验,因为它组织了git hash和相应参数等信息,并可以将具有唯一ID的不同运行存储在实验组中,并更容易比较不同的结果(类似于其他工具,如权重和偏差)。AE-KL的日志文件可以从链接https://drive.google.com/drive/folders/1Ots9ujg4dSaTABKkyaUnFLpCKQ7kCgdK?usp=sharing处找到。
采用Diffusion模型
接下来,我们需要训练我们的扩散模型了。
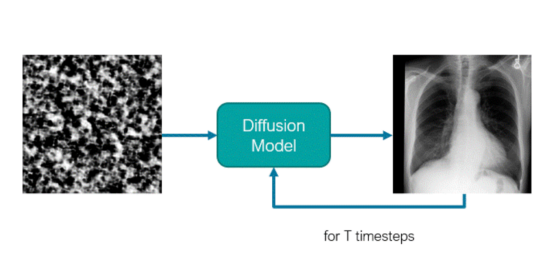
扩散模型是一个类似U-Net的网络。传统上,这种模型接收有噪声的图像(或潜在表示)作为输入,并预测其噪声分量。这些模型使用迭代去噪机制,通过几个步骤就能够从马尔可夫链上的噪声中生成图像。出于这个原因,该模型还以定义该模型处于采样过程的哪个阶段的时间步长为条件。
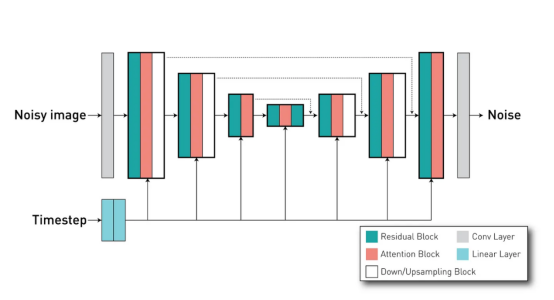
借助于DiffusionModelUNet类,我们可以为我们的扩散模型创建类似U-Net的网络。我们的项目使用了配置文件中所定义的配置参数,其中它定义了具有3个通道的输入和输出(因为我们的AE-kl具有3个通道的潜在空间),以及具有256512768个通道的3个不同级别。每个级别有2个残差块。
如前所述,这里非常重要的一点是传递所使用的模型的时间步长值,从而使模型便于调节这些残差块的行为。最后,我们定义了网络内部的注意力机制。在我们的案例中,我们在第二级和第三级有注意力块(由attention_levels参数表示),每个注意力头有512和768个通道(换句话说,我们在每个级别都有一个注意力头)。这些注意力机制很重要,因为它们允许我们通过交叉注意力方法将外部条件(放射性报告)应用于网络。
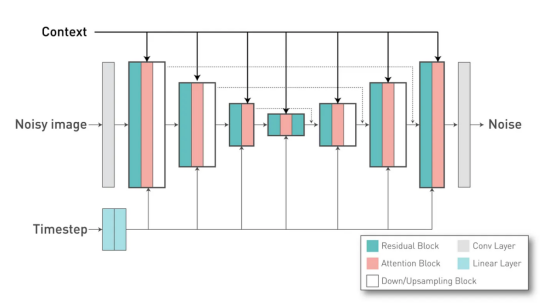
外部条件(或“上下文”)应用于U-Net的注意力块
在我们的项目中,我们使用了一个已经经过训练的文本编码器。为了简单起见,我们使用了Stable Diffusion v2.1模型中的相同模型(“stabilityai/Stable-Diffusion-2–1-base”)将我们的文本标记转换为文本嵌入,该文本嵌入将用作DiffusionModel UNet交叉关注层中的Key和Value向量。我们的文本嵌入的每个令牌都有1024个维度,我们在“with_conditing”和“cross_attention_dim”参数中定义它。
除了我们的模型定义之外,定义扩散模型的噪声将如何在训练期间添加到输入图像并在采样期间去除也是很重要的。为此,我们在MONAI生成模型中实现了Schedulers类,以定义噪声调度器。在本例中,我们将使用DDPMScheduler,具有1000个时间步长和以下超参数。
在这里,我们选择了“v预测”方法,其中我们的U-Net将尝试预测速度分量(原始图像和添加的噪声的组合),而不仅仅是添加的噪声。这种方法已被证明具有更稳定的训练和更快的收敛(也用于链接https://arxiv.org/abs/2210.02303处相应的算法模型)。
训练Diffusion模型
在训练扩散模型之前,我们需要找到一个合适的比例因子。如Rombach等人所述,如果潜在空间分布的标准偏差过高,信噪比可能会影响LDM获得的结果。如果潜在表示的值太高,我们添加到其中的最大高斯噪声量可能不足以破坏所有信息。这样,在训练过程中,原始潜在表示的信息可能在不应该出现的时候出现,这使得以后不可能从纯噪声中对图像进行采样。KL正则化可以在这方面有所帮助,但最好使用比例因子来调整潜在的表示值。在这个脚本中,我们验证了一批训练集中潜在空间分量的标准偏差的大小。我们发现我们的比例因子应该至少为0.8221。在我们的案例中,我们使用了一个更保守的值0.3(类似于稳定扩散的值)。
通过定义比例因子,我们可以训练我们的模型。在下面代码中,我们来看一下对应的训练循环。
正如您所看到的,我们首先从数据加载器中获取图像和报告。为了处理我们的图像,我们使用了MONAI的转换,并添加了一些自定义转换,从放射学报告中提取随机句子,并对输入的文本进行标记。在大约10%的情况下,我们使用空字符串(“”——这是一个带有句子开始标记(值=49406)和填充标记(值=49407)的向量),以便能够在采样期间使用无分类器引导。
接下来,我们获得了潜在表示和提示嵌入。我们创建要添加的噪声、要在该迭代中使用的随机时间步长以及所需的目标(速度分量)。最后,我们使用均方误差来计算我们的损失。
这种训练共持续了500次,有关的训练日志数据您可以在链接处https://drive.google.com/drive/folders/1Ots9ujg4dSaTABKkyaUnFLpCKQ7kCgdK?usp=sharing找到。
采样图像
在我们训练了两个模型之后,我们可以对合成图像进行采样。本实验中,我们使用了链接https://github.com/Warvito/generative_chestxray/blob/main/src/python/testing/sample_images.py处所对应的脚本。

该脚本使用Ho等人提出的无分类器引导方法,以强制执行图像生成中使用的文本提示。在这种方法中,我们使用了一个指导量表,可以用来牺牲生成数据的多样性,以获得对文本提示具有更高保真度的样本。7.0是默认值。
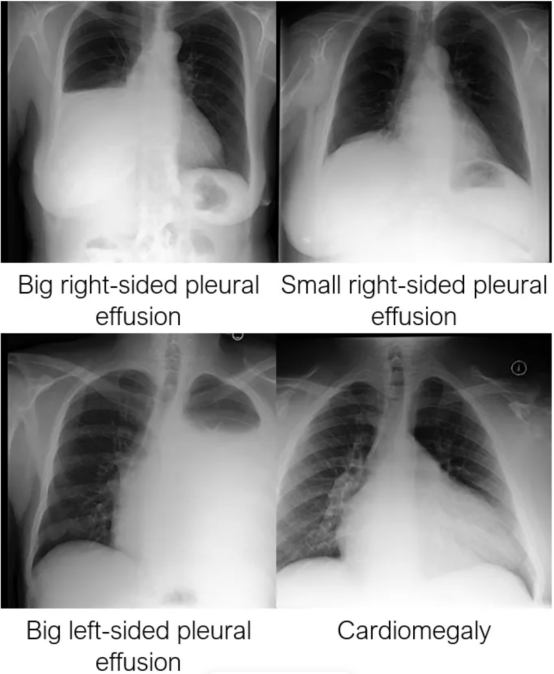
在下图中,我们可以看到经过训练的模型是如何了解临床特征的,以及它们的位置和严重程度。
评估
在本节中,我们将展示如何使用MONAI的指标来评估我们的生成模型在几个方面的性能。
基于MS-SSIM方法的自动编码器重构质量评估
首先,我们来验证我们的自动编码器kl重建输入图像的效果。这是我们在开发模型时的一个重要考虑点,因为压缩和重建数据的质量将定义我们样本质量的上限。如果模型没有很好地学习如何从潜在表示中解码图像,或者如果它没有很好的对我们的潜在空间建模,那么就不可能以现实的方式解码合成表示。在这个脚本中,我们使用测试集中的共5000张图像来评估我们的模型。我们可以使用多尺度结构相似性指数测量(MS-SSIM:Multiscale Structural Similarity Index Measure)来验证我们的重建效果。MS-SSIM是一种广泛使用的图像质量评估方法,用于测量两幅图像之间的相似性。与传统的图像质量评估方法(如PSNR和SSIM)不同,MS-SSIM能够捕捉不同尺度的图像的结构信息。
在我们的模型情况下,值越高,模型就越好。对于我们当前发布的版本(版本0.2),我们观察到我们的模型的平均MS-SSIM重建指标值为0.9789。
MS-SSIM样本的多样性
我们将首先评估由我们的模型生成的样本的多样性。为此,我们计算了不同生成图像之间的多尺度结构相似性指数测度。在我们的实验项目中,我们假设,如果我们的生成模型能够生成不同的图像,那么在比较合成图像对时,它将呈现较低的平均MS-SSIM值。例如,如果我们遇到模式崩溃之类的问题,我们生成的图像看起来会相似,并且MS-SSIM值会比我们在真实数据集中观察到的值低得多。
在我们的项目中,我们使用非条件样本(以“”(空字符串)作为文本提示生成的样本)来保持原始数据集的自然比例。如本脚本所示,我们选择了1000个模型的合成样本,并使用MONAI的数据加载器来帮助加载所有可能的图像对。我们使用嵌套循环来遍历所有可能的图像对,并忽略在两个数据加载器中选择的图像相同的情况。在这里,我们可以观察到MS-SSIM值为0.4083。我们可以在来自测试集的真实图像中执行相同的评估作为参考值。使用这个脚本,我们获得了测试集的MS-SSIM值为0.4046,这表明我们的模型生成的图像具有与在真实数据中观察到的图像相似的多样性。
然而,多样性并不意味着图像看起来好看或逼真。所以,我们将在下一步检查图像质量!
使用FID指标评估合成图像的质量
最后,我们来测量项目所生成的样本的FID指标值。FID是一种评估两组之间分布的指标,显示它们的相似程度。为此,我们需要一个预先训练的神经网络,从中我们可以提取用于计算距离的特征(类似于感知损失)。在这个例子中,我们选择使用torchxrayvision软件包中所提供的神经网络。
我们使用了Dense121网络(“densenet121-res224-all”),我们选择这个网络是为了接近文献中用于CXR合成图像的网络。从这个网络中,我们获得了一个具有1024个维度的特征向量。正如FID原始文件中建议的那样,与特征数量相比,使用类似数量的样本是很重要的。出于这个原因,我们使用了1000张无条件图像,并将它们与测试集中的1000张图像进行比较。对于FID指标来说,值越低越好,这里我们获得了合理的FID=9.0237。
结论
在这篇文章中,我们介绍了一种使用MONAI生成模型开发项目的方法,内容包括从下载数据到评估生成模型和最后的合成数据等。尽管这个项目版本可能更高效,也有更好的超参数,但是其实我们希望它能很好地说明我们开发的扩展所提供的不同功能。如果您对如何改进我们的CXR模型有任何想法,或者如果您想为我们的软件包做出贡献,请在链接https://github.com/Warvito/generative_chestxray/issues或链接https://github.com/Project-MONAI/GenerativeModels/issues处添加对我们问题部分的评论。
最后说明一点,本文中我们经过训练的模型可以在MONAI模型动物园网站找到,还有我们的3D大脑生成器和其他模型等内容均可找到。我们所提供的模型动物园使下载模型的权重和执行推理的代码变得更加容易。
最后,如果您想要了解更多教程资源和关于我们工作的更多信息,请访问链接https://github.com/Project-MONAI/GenerativeModels/tree/main/tutorials查看我们的教程页面,并请关注我本人,以获取最新的更新和更多类似内容!
[注]除非另有说明;否则,本文中所有图片均由作者提供。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Generating Medical Images with MONAI,作者:Walter Hugo Lopez Pinaya