大型语言模型能力惊人,但在部署过程中往往由于规模而消耗巨大的成本。华盛顿大学联合谷歌云计算人工智能研究院、谷歌研究院针对该问题进行了进一步解决,提出了逐步蒸馏(Distilling Step-by-Step)范式帮助模型训练。该方法在训练用于特定任务的小型模型方面优于 LLM,训练数据远少于传统的微调和蒸馏。他们的 770M T5 模型在一个基准任务上表现优于 540B PaLM 模型。令人印象深刻的是,他们的模型只使用了可用数据的 80%。

虽然大型语言模型(LLMs)展现了令人印象深刻的少样本学习能力,但将这样大规模的模型部署在现实应用中是很难的。为 1750 亿参数规模的 LLM 提供服务的专门基础设施,至少需要 350GB 的 GPU 内存。更甚者,现今最先进的 LLM 是由超过 5000 亿的参数组成的,这意味着它需要更多的内存和计算资源。这样的计算要求对于大多数生产商来说都是难以企及的,更何况是要求低延迟的应用了。
为了解决大型模型的这个问题,部署者往往采用小一些的特定模型来替代。这些小一点的模型用常见范式 —— 微调或是蒸馏来进行训练。微调使用下游的人类注释数据升级一个预训练过的小模型。蒸馏用较大的 LLM 产生的标签训练同样较小的模型。但是很遗憾,这些范式在缩小模型规模的同时也付出了代价:为了达到与 LLM 相当的性能,微调需要昂贵的人类标签,而蒸馏需要大量很难获得的无标签数据。
在一篇题为「Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes」的论文中,来自华盛顿大学、谷歌的研究者引入了一种新的简单机制 —— 逐步蒸馏(Distilling step-bystep),用于使用更少的训练数据来训练更小的模型。这种机制减少了微调和蒸馏 LLM 所需的训练数据量,使之有更小的模型规模。

论文链接:https://arxiv.org/pdf/2305.02301v1.pdf
该机制的核心是换一种角度,将 LLM 看作是可以推理的 agent,而不是噪声标签的来源。LLM 可以产生自然语言的理由(rationale),这些理由可以用来解释和支持模型所预测的标签。例如,当被问及「一位先生携带着打高尔夫球的设备,他可能有什么?(a) 球杆,(b) 礼堂,(c) 冥想中心,(d) 会议,(e) 教堂」,LLM 可以通过思维链(CoT)推理回答出「(a)球杆」,并通过说明「答案一定是用来打高尔夫球的东西」来合理化这个标签。在上述选择中,只有球杆是用来打高尔夫的。研究者使用这些理由作为额外更丰富的信息在多任务训练设置中训练较小的模型,并进行标签预测和理由预测。
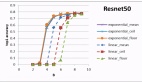
如图 1 所示,逐步蒸馏可以学习特定任务的小模型,这些模型的参数量还不到 LLM 的 1/500。与传统的微调或蒸馏相比,逐步蒸馏使用的训练示例要也少得多。

实验结果显示,在 4 个 NLP 基准中,有三个有希望的实验结论。
- 第一,相对于微调和蒸馏,逐步蒸馏模型在各数据集上实现了更好的性能,平均减少了 50% 以上的训练实例(最多可减少 85% 以上)。
- 第二,我们的模型在模型尺寸更小的情况下表现优于 LLM(最多可以小到 2000 倍),极大地降低了模型部署所需的计算成本。
- 第三,该研究在缩减模型尺寸的同时,也减少了超越 LLM 所需要的数据量。研究者使用一个 770M 的 T5 模型超越了 540B 参数的 LLM 的性能。这个较小的模型只使用了现有微调方法 80% 的标记数据集。
当只有未标记的数据时,小模型的表现相比 LLM 而言仍然有过之而无不及 —— 只用一个 11B 的 T5 模型就超过了 540B 的 PaLM 的性能。
该研究进一步表明,当一个较小的模型表现比 LLM 差时,与标准的蒸馏方法相比,逐步蒸馏可以更有效地利用额外的无标签数据来使较小的模型媲美 LLM 的性能。
逐步蒸馏
研究者提出了逐步蒸馏这个新范式,是利用 LLM 对其预测的推理能力,以数据高效率的方式训练更小的模型。整体框架如图 2 所示。

该范式有两个简单的步骤:首先,给定一个 LLM 和一个无标签的数据集,提示 LLM 生成输出标签以及证明该标签成立的理由。理由用自然语言解释,为模型预测的标签提供支持(见图 2)。理由是当前自监督 LLM 的一个涌现的行为属性。
然后,除了任务标签之外,利用这些理由来训练更小的下游模型。说白了,理由能提供了更丰富、更详细的信息,来说明一个输入为什么被映射到一个特定的输出标签。
实验结果
研究者在实验中验证了逐步蒸馏的有效性。首先,与标准的微调和任务蒸馏方法相比,逐步蒸馏有助于实现更好的性能,训练实例的数量少得多,大幅提高了学习小型特定任务模型的数据效率。


其次,研究表明,逐步蒸馏方法以更小的模型大小超越了 LLM 的性能,与 llm 相比,大大降低了部署成本。


最后,研究者调查了逐步蒸馏方法在超过 LLM 的性能方面所需的最低资源,包括训练示例数量和模型大小。他们展示了逐步蒸馏方法通过使用更少的数据和更小的模型,同时提高了数据效率和部署效率。