译者 | 李睿
审校 | 重楼
本文将分享一些在Mule4中创建高可靠应用的优秀实践。而用户对可靠性的期望是在Mule应用程序停止或崩溃之后不会丢失消息或数据。
这里分享的大部分配置细节(与可靠性相关)都来自MuleSoft文档/文章。
1.异步处理—使用持久虚拟机队列| Anypoint MQ使用外部消息代理(基于JMS)
使用持久虚拟机队列
当在单个运行时实例模式下运行Mule应用程序时,持久队列通过序列化并将内容存储在磁盘上来工作。但是,当在集群运行时实例模式下运行Mule应用程序时,持久队列会备份在内存网格中。在单个运行时实例模式或集群运行时实例模式下,当使用持久队列时,发送的数据必须是可序列化的。
CloudHub(1.0)部署的应用程序可以选择使用CloudHub持久队列。CloudHub持久队列是一种云服务,允许将发布到虚拟机(VM)队列的消息存储在应用程序的外部。
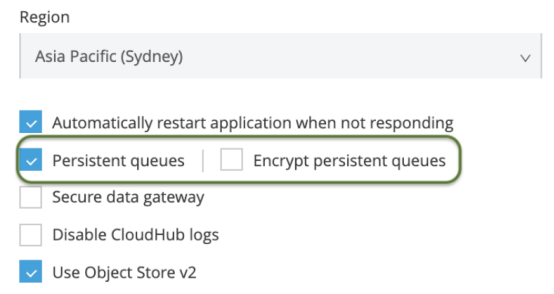
如何启用CloudHub持久队列
CloudHub持久队列可以在每个应用程序的基础上启用,该选项可以在运行时管理器→应用程序→设置页面中找到。如果用户拥有这一权限,还可以选择加密持久队列以增加安全性。这一功能仅适用于拥有白金及以上订阅权限的用户。
使用Anypoint MQ
Anypoint MQ是一个多租户的云消息传递服务,允许客户在其应用程序之间执行高级异步消息传递方案。Anypoint MQ与Anypoint平台完全集成,提供基于角色的访问控制、客户端管理和连接器。
Anypoint MQ确保安全可靠的消息传递。自动启用跨多个数据中心的持久数据存储,以确保消息队列架构能够处理数据中心中断并具有完全的灾难恢复。对消息队列进行加密以确保数据处于静止状态,或将消息发送到死信队列以提高可靠性。
如何使用Anypoint MQ
安装和配置Anypoint MQ
- 使用Enterprise Mule凭据登录Anypoint平台,然后单击MQ。
- 单击“访问管理”,然后单击“用户或角色”,创建Anypoint MQ用户或角色。
- 从MQ创建队列、消息交换或FIFO队列。
- 单击详细信息中的队列或消息交换器名称,可以访问消息发送器,将消息发送到队列或消息交换器,并使用消息浏览器从队列中获取消息。
- 在MQ中,单击“客户端应用程序”注册应用程序。可以查看该应用程序的客户端应用ID和客户端秘密。
在Anypoint Studio中,
- 使用Anypoint Exchange安装Anypoint MQ连接器。
- 使用所需的构建块(如HTTP连接器、Anypoint MQ连接器、Set Payload和Logger)创建一个新的Mule项目。
- 配置Anypoint MQ连接器,并提供应用程序的客户端应用程序ID和客户端密码。
- 将Anypoint MQ连接器操作设置为发布或使用消息,或接受(ACK)或不接受(NACK)消息。
使用外部消息代理(基于JMS)
用于JMS(Java消息服务)的Anypoint连接器(JMS连接器)支持向实现JMS规范的任何消息服务的队列和主题发送和接收消息。
如何配置JMS连接器
配置源:
可以配置以下三个输入源中的一个来使用JMS连接器:
- JMS>新建消息— 通过侦听传入消息来启动数据流
- HTTP>侦听器— 每当它在配置的主机和端口上接收到请求时,就启动数据流
- 调度器— 在满足基于时间的条件时,启动数据流
要配置“新建消息”源,执行以下步骤:
- 在Mule Palette视图中,选择JMS>新建消息。
- 将新消息拖到Studio画布上。
- 在“新建消息”配置屏幕中,可选择更改“显示名称”字段的值。
- 单击连接器配置字段旁边的加号(+)来配置一个全局元素,该元素可以被应用程序中的所有源实例使用。
在JMS配置窗口中,为“连接”选择要提供给此配置的连接类型之一:
- 主动MQ连接
- 主动MQ连接— 无连接测试-(已弃用)
- 通用连接
- 在通用选项卡上,指定连接器的连接信息,例如代理所需的库、JMS规范、缓存策略、身份验证和连接。
- 在TLS/SSL选项卡上,可以选择指定TLS配置。
- 在“高级”选项卡上,可以选择指定重新连接策略和XA连接池。
- 单击“确定”关闭窗口。
- 在“新建消息”配置屏幕的“目的地”中,指定要从中使用消息的目的地的名称。
- 在“新建消息”配置界面中配置其他可选字段。
添加连接器
要为JMS连接器添加操作,遵循以下步骤:
- 在Mule Palette视图中,选择JMS连接器,然后选择所需的操作。
- 将操作拖到Studio画布上,并拖动到输入源的右侧。
2.状态管理-使用持久对象存储|使用持久虚拟机队列|使用外部存储(DB、FTP等)
使用持久对象存储
对象存储是一个存储键值信息的存储容器。对象存储可以是持久的或暂时的(非持久的),在应用程序重启的情况下,持久性操作系统不会丢失任何信息(键值),而非持久性(键值)信息丢失。
如何使用/启用持久对象存储
使用默认对象存储
在默认情况下,每个Mule应用程序都有一个持久的对象存储,并且总是可以在不需要任何配置的情况下对应用程序可用。数据流可以使用它来持久化和共享数据。
如果希望使用默认的对象存储,可以为对象存储指定键,而无需为对象存储操作选择或创建对象存储引用,也无需在对象存储组件的XML元素中指定对象存储属性。
Mule应用程序使用运行时管理器部署到CloudHub worker,但是默认对象存储的内容在应用程序的应用程序数据页面的运行时管理器中是不可见的。
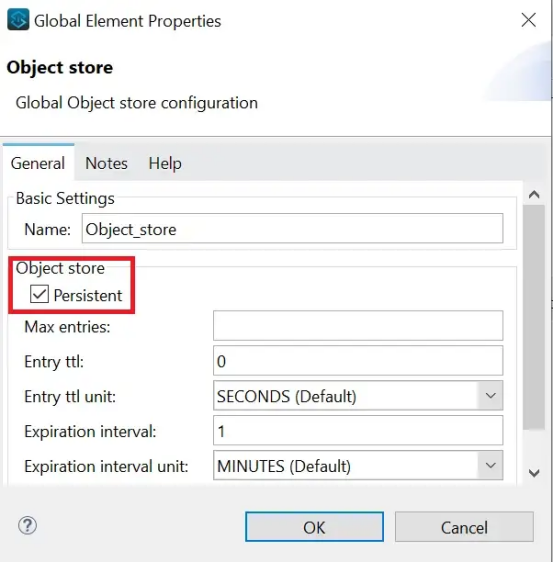
使用自定义对象存储
自定义对象存储必须指定对象存储属性。这些对象存储可以配置为不同于默认对象存储的行为。例如,可以指出对象存储是持久的(这样对象存储的数据在Mule运行时崩溃时仍然存在)还是瞬态的(在Mule运行时崩溃时数据不存在)。
使用Persistence Gateway
Anypoint Runtime Fabric提供Persistence Gateway。
允许部署到Mule运行时实例的Mule应用程序在应用程序副本和重启之间存储和共享数据,从而确保可靠性。
在Anypoint Runtime Fabric中配置了Persistence Gateway后,它就可以用于部署到Mule运行时引擎(4.2.1或更高版本)的Mule应用程序。在配置完成后,用户可以在使用运行时管理器部署应用程序时选择“使用持久对象存储”。
Mule应用程序通过对象存储连接器使用对象存储v2 REST API连接到Persistence Gateway。这使得用户可以同时部署到Anypoint Runtime Fabric和CloudHub,而无需修改Mule应用程序。
如何配置Persistence Gateway
在配置过程中,Persistence Gateway创建所需的数据库模式。然后,当部署到Runtime Fabric的应用程序被配置为使用持久对象存储时,Persistence Gateway将必要的行写入数据库。
要配置Persistence Gateway,必须创建一个Kubernetes自定义资源,该资源允许集群连接到持久性数据存储。
Create a Kubernetes Secret
Shell
kubectl create secret generic <SECRET NAME> -n rtf --from-literal=persistence-gateway-creds='postgres://
es://username:pass@host:port/databasename' 为数据存储创建自定义资源
1.将自定义资源模板从Kubernetes自定义资源模板复制到一个名为custom-resource.yaml的文件中。
2.确保secretRef:name的值与Kubernetes秘密文件中定义的name字段匹配。
3.根据环境的需要修改自定义资源模板的其他字段。
4.运行kubectl apply-f customientresource.yaml。
检查Persistence Gateway Pod的日志,以确保它可以与数据库通信
Shell
kubectl get pods -n rtf
寻找具有名称前缀Persistence Gateway Pod
Shell
kubectl logs -f persistence-gateway-6dfb98949c-7xns9 -nrtf使用持久虚拟机队列
参考上面的“异步处理”。
使用外部存储
另一种选择是将数据持久化在外部存储系统中,如DB、FTP、外部缓存等。Mule应用程序可以使用连接器连接到这些系统。
不同的外部存储提供不同的服务质量(QoS)级别,从而确保可靠性:
- 持久性
- 事务
- 复制
- 驱逐策略(最不常用)
- 通过集群实现高可用性
- 通过分区加快数据检索
- 自动故障切换
3.重新连接策略
当Mule应用程序中的操作无法连接到外部服务器时,默认行为是操作立即失败并返回连接错误。
为了确保不丢失数据,可以通过为该操作配置重连接策略来修改这一默认行为。
如何配置重连接策略
可以通过修改操作属性或修改操作的全局元素的配置来配置操作的重连接策略。
连接性测试在Mule应用程序启动时运行,然后在应用程序运行时定期运行。重新连接策略指示当连接失败时应该做什么。
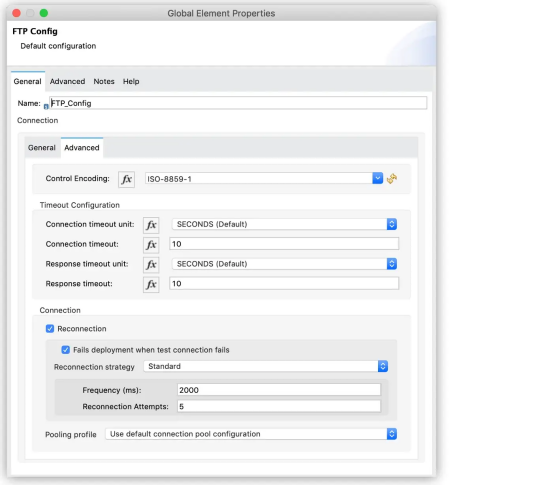
以下是可用的重连接策略及其行为:
- 从不:默认行为,如果连接尝试不成功,则立即返回连接错误。
- 标准(重新连接):设置重新连接尝试的次数以及在返回连接错误之前执行这些尝试的间隔。
- 永远(永远重新连接):尝试在给定的时间间隔内不断地重新连接。
XML示例代码:
XML
<ftp:config name="FTP_Config" doc:name="FTP Config" >
<ftp:connection host="ftp.someftphost.com" port="21" username="myusername" password="mypassword" >
<reconnection failsDeployment="true" >
<reconnect count="5"/>
</reconnection>
</ftp:connection>
</ftp:config>
<flow name="reconnectionsFlow" >
<ftp:listener doc:name="On New or Updated File" config-ref="FTP_Config">
<scheduling-strategy >
<fixed-frequency />
</scheduling-strategy>
</ftp:listener>
</flow>XML
<ftp:connection host="ftp.someftphost.com" port="21" username="myusername" password="mypassword" >
<reconnection>
<reconnect-forever frequency="4000"></reconnect>
</reconnection>
</ftp:connection>在默认情况下,只会记录一个失败的连接测试,Mule应用程序无论如何都会启动或继续运行而不尝试重新连接。但是,可以在某些连接器操作上配置重新连接策略,以代替重复尝试连接。
配置属性/参数如下:
< reconnection >的属性
failsDeployment:如果为true,当测试连接失败时导致部署失败。默认为false。
<reconnect>的属性
Blocking:如果为false,重连接策略在一个单独的非阻塞线程中运行。默认为true。
Frequency:重新连接的频率(毫秒)。默认为2000。
Count:尝试重连的次数。默认值为2。
<reconnect-forever>的属性
Blocking:如果为false,重连接策略在一个单独的非阻塞线程中运行。默认为true。
Frequency:指定重新连接的频率(单位:毫秒)。默认为2000。
4.重新传递策略
重新传递策略(Redelivery Policy)是一个过滤器,通过限制Mule运行时引擎(Mule)执行产生错误的消息的次数来帮助节省资源。
当向流的源添加重新传递策略时,Mule会在执行流的组件之前评估接收到的数据。如果消息传递失败了指定次数,则重新传递策略将阻止流处理接收到的数据,并引发REDELIVERY_EXHAUSTED错误。
如何配置重新传递策略
在流中的事件源上配置重新发送策略,例如:HTTPListener;关于新建或更新的文件;在JMS连接器的新消息等上指定编号。在引发REDELIVERY_EXHAUSTED错误之前,流可以处理由事件源发出的“相同”事件的次数。
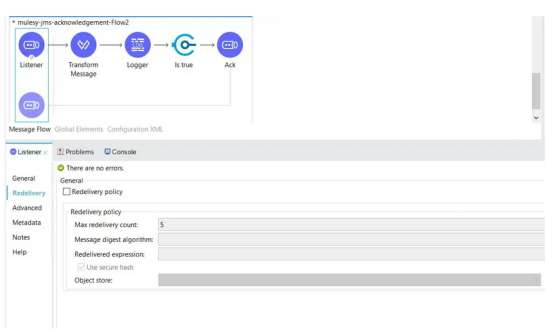
以下是配置参数:
- Max Redelivery Count:在引发MULE:Redelivery_EXHAUSTED错误之前,可以将消息重新传递到流并处理失败的最大次数。默认值为5。
- 0表示不传递
- -1表示无限次重新传递
- 是否使用安全哈希:是否使用安全哈希算法来识别重新发送的消息。默认为True。
- 消息摘要算法:用于消息的安全哈希算法。如果消息的有效负载是一个Java对象,Mule将忽略消息摘要算法的值,并返回有效负载的hashCode()返回的值。默认为SHA-256。
- ID表达式:定义一个或多个表达式,用于确定何时重新传递消息。只有当“使用安全散列”的值为False时,才能设置此属性。
- 对象存储:存储每条消息的重新传递计数器的对象存储。可以将对象存储配置为引用或内部元素。
重新传递策略如何运作
每次源接收到一个新消息,Mule通过生成它的密钥来识别该消息。
- 如果处理流导致异常,Mule增加与消息键关联的计数器。当计数器达到的值大于配置的maxRedeliveryCountvalue时,Mule抛出Mule:REDELIVERY_EXHAUSTED错误。
- 如果处理流没有引起异常,则重置其计数器。
5.文件存储的可重复流策略
Mule4引入了可重复流作为处理流的默认框架。可重复流使用户能够:
- 多次读取流。
- 能够并发访问流。
该策略最初使用的内存缓冲区大小为512KB。对于较大的流,该策略在磁盘上创建一个临时文件来存储内容,而不会溢出内存。
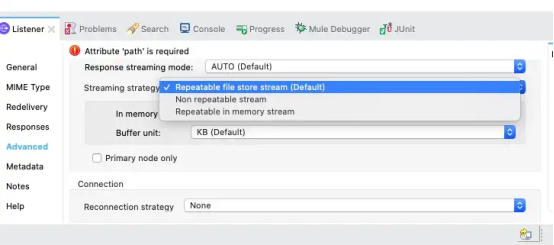
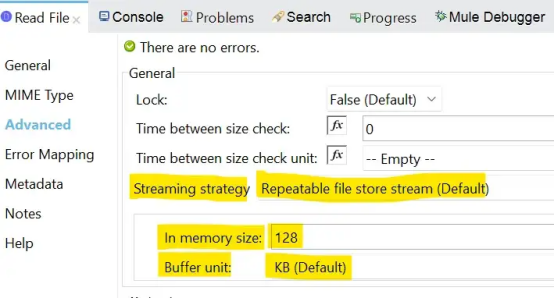
如果需要处理大文件或小文件,可以改变缓冲区大小(inMemorySize)来优化性能:
- 配置更大的缓冲区大小可以通过避免运行时需要将缓冲区写入磁盘的次数来提高性能,但它也限制了应用程序可以处理的并发请求的数量。
- 配置较小的缓冲区大小可节省内存负载。
还可以设置缓冲区的度量单位(bufferUnit)。
XML示例代码:
XML
<file:read path="smallFile.json">
<repeatable-file-store-stream
inMemorySize="10"
bufferUnit="KB"/>
</file:read>6.事务管理
事务是Mule应用程序中的操作,其结果需要保持确定。当流中的一系列步骤必须作为一个单元成功或失败时,Mule使用事务来划分该单元。
事务类型
Mule支持单一资源(默认为本地)和扩展架构(XA)事务类型(transactionType)。唯一可以定义事务类型的组件是消息源(例如jms:listener和vm:listener)和Try scope。
单一资源事务(也称为简单事务或本地事务)仅使用单一资源发送或接收消息:JMS代理、VM队列或JDBC连接。
XML示例代码:
XML
<flow name="asdFlow" doc:id="2a67b1ee-0394-44a8-b6d9-9ce4f94f1ae2" >
<jms:listener config-ref="JMS_Config" destinatinotallow="test.in" transactinotallow="ALWAYS_BEGIN"/>
<!-- Other operations -->
<jms:publish config-ref="JMS_Config" destinatinotallow="test.out" transactinotallow="ALWAYS_JOIN"/>
</flow>Mule只提交成功通过完整流的消息。如果在流中的任何一点上,消息抛出了一个传播的错误(不是由出错时继续处理的),Mule将回滚事务。
扩展架构事务(或XA事务)可用于将来自多个事务资源(如VM、JMS或Database)的一系列操作分组到单个可靠的全局事务中。
XA(扩展架构)标准是一个X/Open组标准,它指定了全局事务管理器和本地事务资源管理器之间的接口。XA协议定义了一个两阶段提交协议,可用于跨不同类型的多个服务器可靠地协调和排序一系列原子操作。每个本地XA资源管理器都支持A.C.I.D属性(原子性、一致性、隔离性和持久性),这些属性有助于确保XA资源管理器管理的资源中操作序列的完成。
XML示例代码:
XML
<flow name="exampleFlow" >
<try transactinotallow="ALWAYS_BEGIN" transactinotallow="XA">
<set-payload value="Hello World"/>
<vm:publish queueName="someVmQueue" config-ref="VM_Config"/>
<jms:consume config-ref="JMS_Config" destinatinotallow="someQueue"/>
<db:insert config-ref="Database_Config">
<db:sql>${insertQuery}</db:sql>
</db:insert>
</try>
<error-handler>
<on-error-propagate enableNotificatinotallow="true" logExceptinotallow="true"/>
</error-handler>
</flow>如果db:insert操作失败,事务将在错误处理程序(on-error-propagate)执行之前回滚(即它不是由on-error-continue处理的)。因此,通过vm:publish发送的消息不会被确认发送,而jms:consume中的消息也不会被实际使用,因此下次可以再次使用它。
下表描述了每种事务类型的特征以及加入事务的操作所需的条件:

Mule4中支持事务的常见连接器操作:
- JMS—发布;消费
- VM—发布;消费
- 数据库—所有操作
事务操作
事务操作(transactionalAction)定义了操作对事务采取的操作类型。
下表描述了所有可用的事务操作:
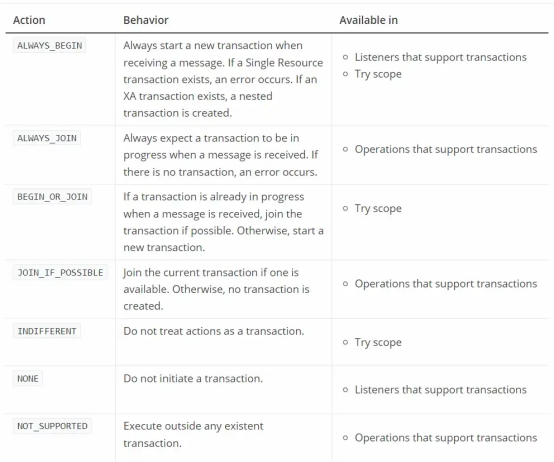
如何配置事务
在消息源中,可以从消息源启动事务。在这种情况下,整个流成为一个事务。
要从消息源发起事务,请配置其事务类型和事务操作:
- 在Anypoint Studio中:打开监听器的高级选项卡,设置事务类型和事务动作值:
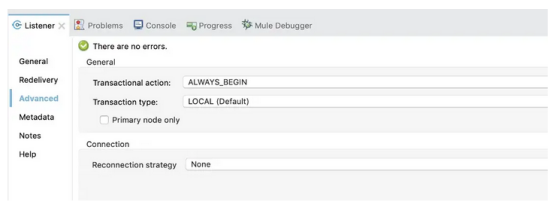
- 在配置XML中:添加transactionaction元素和transactionType元素(如果需要的话),并设置它们的值:
XML
<?xml versinotallow="1.0" encoding="UTF-8"?>
<mule xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns:vm="http://www.mulesoft.org/schema/mule/vm"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc=http://www.mulesoft.org/schema/mule/documentation xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocatinotallow="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/vm http://www.mulesoft.org/schema/mule/vm/current/mule-vm.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd">
<vm:config name="VM_Config1" >
<vm:queues >
<vm:queue queueName="input" />
<vm:queue queueName="output" />
</vm:queues>
</vm:config>
<flow name="source-transactionsFlow">
<vm:listener config-ref="VM_Config1" queueName="input" transactinotallow="ALWAYS_BEGIN"/>
<http:request method="GET" url="www.google.com"/>
<vm:publish config-ref="VM_Config1" queueName="output"/>
</flow>
</mule>在Try scope内
Mule流也能够以非事务性连接器(如HTTP)开始,它需要流中的事务。在这种情况下,可以使用Try scope来设置事务。
可以在Try scope组件中通过设置事务类型和事务操作来设置事务:
•在Anypoint Studio中:打开Try scope的General选项卡,设置事务类型和事务操作值:
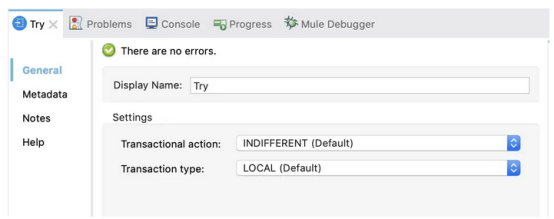
•在配置XML中:添加transactionaction元素和transactionType元素(如果需要的话),并设置它们的值:
XML
<?xml versinotallow="1.0" encoding="UTF-8"?>
<mule xmlns:vm="http://www.mulesoft.org/schema/mule/vm" xmlns:db="http://www.mulesoft.org/schema/mule/db"
xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:doc="http://www.mulesoft.org/schema/mule/documentation"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocatinotallow="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/db http://www.mulesoft.org/schema/mule/db/current/mule-db.xsd
http://www.mulesoft.org/schema/mule/vm http://www.mulesoft.org/schema/mule/vm/current/mule-vm.xsd">
<db:config name="Database_Config">
<db:derby-connection database="myDb" create="true" />
</db:config>
<vm:config name="VM_Config">
<vm:queues>
<vm:queue queueName="myQueue" />
</vm:queues>
</vm:config>
<flow name="transactionsFlow">
<try transactinotallow="ALWAYS_BEGIN" transactinotallow="XA">
<db:insert doc:name="Insert" transactinotallow="ALWAYS_JOIN">
<db:sql>
INSERT INTO main_flow_audit (errorType, description) VALUES (:errorType, :description)
</db:sql>
<db:input-parameters><![CDATA[
#[{
'errorType' : 'AUTHENTICATION',
'description' : 'invalid authentication credentials',
}]
]]></db:input-parameters>
</db:insert>
<vm:publish config-ref="VM_Config" queueName="myQueue" transactinotallow="ALWAYS_JOIN"/>
</try>
</flow>
</mule>Bitronix事务管理器
Bitronix是Mule应用程序的XA事务管理器。Bitronix事务管理器允许Mule在重启时自动恢复中断的事务。
如何配置Mule应用程序使用Bitronix
要使用Bitronix(在单个应用程序中或在Mule域中的所有应用程序中),在Mule应用程序中将其声明为全局配置元素:
XML
<?xml versinotallow="1.0" encoding="UTF-8"?>
<mule xmlns="http://www.mulesoft.org/schema/mule/core"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:bti="http://www.mulesoft.org/schema/mule/ee/bti"
xsi:schemaLocatinotallow="
http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/ee/bti http://www.mulesoft.org/schema/mule/ee/bti/current/mule-bti-ee.xsd">
<bti:transaction-manager/>
...
</mule>可以添加Bitronix
从Studio导入到应用程序或域,执行以下步骤:
- 进入全局元素选项卡。
- 点击创建按钮。
- 搜索Bitronix事务管理器。
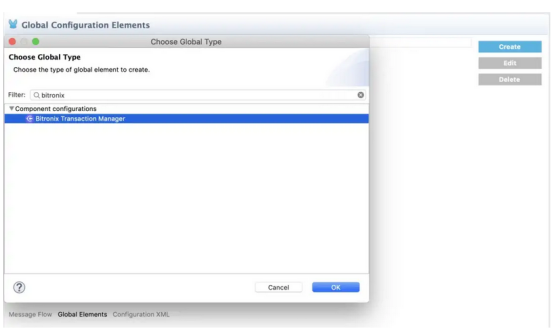
下表列出了Bitronix的配置属性:

7.批处理作业
批处理作业组件设计用于对大于内存的数据集进行可靠的异步处理。它自动拆分源数据,并将其存储到持久队列中,从而可以处理大型数据集。
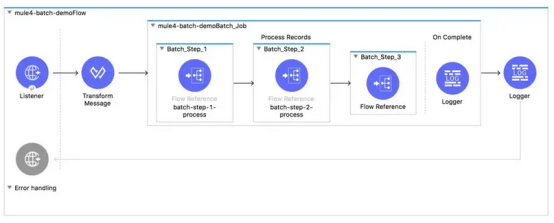
该组件可配置如下:
- 过滤要在批处理步骤中处理的记录:要过滤记录,批处理步骤支持acceptExpression和acceptPolicy。两者都是可选的。
- 从批量聚合器执行批量操作:聚合用于将数组中的多条记录发送到外部服务器。
- 改变记录块大小:为了提高性能,Mule运行时以块的形式队列和调度批记录,每个线程最多100条记录。这种行为减少了I/O请求的数量,提高了操作的负载。
- 在批处理作业实例上设置最大并发限制:最大并发(maxConcurrency)字段限制要同时处理的记录块的数量。
8. Until Successful作用域
Until Successful作用域依次执行其中的处理器,直到所有处理器都成功,或者该作用域耗尽了最大重试次数。Until Successful同步运行。如果作用域内的任何处理器未能连接或未能产生成功的结果,则Until Successful将重试其中的所有处理器,包括失败的处理器,直到所有配置的重试都耗尽。如果重试成功,作用域将继续到下一个组件。如果最后一次重试不成功,Until Successful将报错。
如何配置Until Successful作用域
要配置Until Successful作用域,需要在应用程序流中添加<Until-Successful>XML元素。
可以在Until Successful作用域内配置以下属性:

XML示例代码:
XML
<!-- FTP Connector config-->
<ftp:config name="FTP_Config" doc:name="FTP Config" >
<ftp:connection workingDir="${ftp.dir}" host="${ftp.host}" />
</ftp:config>
<flow name="untilSuccessfulFlow" >
<!-- Scheduler component to trigger the flow-->
<scheduler doc:name="Scheduler" >
<scheduling-strategy >
<fixed-frequency frequency="15" timeUnit="SECONDS"/>
</scheduling-strategy>
</scheduler>
<!-- Until Successful scope-->
<until-successful maxRetries="5" doc:name="Until Successful" millisBetweenRetries="3000">
<!-- FTP Write operation that executes as part of the Until Successful Scope -->
<ftp:write doc:name="Write" config-ref="FTP_Config" path="/"/>
</until-successful>
<logger level="INFO" doc:name="File upload success" message="File upload success"/>
<!-- Error Handler at flow level-->
<error-handler>
<on-error-continue enableNotificatinotallow="true" logExceptinotallow="true" doc:name="On Error Continue" type="RETRY_EXHAUSTED">
<logger level="INFO" doc:name="File upload failed" message="File upload failed"/>
</on-error-continue>
</error-handler>
</flow>上面的XML示例配置了由调度器组件和执行FTP写入操作的Until Successful作用域触发的流。
9. First Successful路由器
First Successful路由器遍历已配置的处理路由列表,直到其中一条路由成功执行。如果任何处理路由执行失败(抛出错误),路由器执行下一个配置的路由。如果配置的路由都没有成功执行,First Successful路由将抛出一个错误。
First Successful路由器在成功执行路由后停止执行。
XML示例代码:
XML
<first-successful doc:name="First Successful" doc:id="6ae009e7-ebe5-47cf-b860-db6d51a31251" >
<route>
<file:read doc:name="Read non existent file" doc:id="199cdb01-cb43-404e-acfd-211fe5a9167e" path="nonExistentFile"/>
<set-variable value="1" doc:name="Set successfulRoute var to route 1" doc:id="c740b39e-a1c4-41d6-8a28-0766ca815ec6" variableName="successfulRoute"/>
</route>
<route>
<set-payload value="#[vars.nonExistentVar!]" doc:name="Set Payload with non existent variable" doc:id="0cc9ac4d-5622-4e10-971c-99073cb58df0" />
<set-variable value="2" doc:name="Set successfulRoute var to route 2" doc:id="88f15c26-d242-4b11-af49-492c35625b84" variableName="successfulRoute" />
</route>
<route>
<set-variable value="3" doc:name="Set successfulRoute var to route 3" doc:id="446afb25-0181-45e5-b04a-68ecb98b57b7" variableName="successfulRoute" />
</route>
<route >
<logger level="INFO" doc:name="Logger" doc:id="b94b905a-3a68-4c88-b753-464bc3d0cfeb" message="This route is never going to be executed"/>
</route>
</first-successful>10.可靠性模式
可靠性模式是一种为应用程序提供可靠消息传递的设计,即使应用程序从非事务性连接器接收消息。可靠性模式将可靠的获取流与应用程序逻辑流耦合在一起。
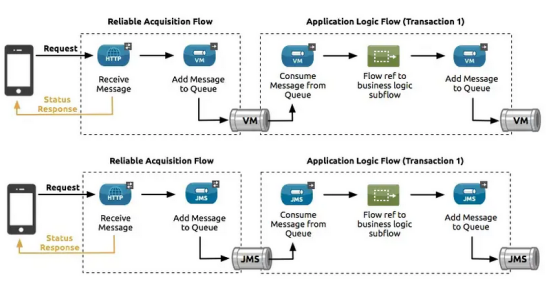
可靠获取流(图的左侧)可靠地将消息从没有实现事务的消息源传递到实现事务的连接器的出站操作。操作可以是任何类型的事务端点,比如VM或JMS。如果可靠获取流不能传递消息,它将确保消息不会丢失。
- 对于基于套接字的连接(例如HTTP),这意味着向客户端返回一个“不成功的请求”响应,以便客户端可以重试请求。
- 对于基于资源的连接(例如文件或FTP),这意味着不删除文件,以便可以重新处理。
应用程序逻辑流(图的右侧)将使用事务连接器的消息源中的消息传递到应用程序的业务逻辑。
XML示例代码:
XML
<http:listener-config name="HTTP_Listener_config" doc:name="HTTP Listener config" >
<http:listener-connection host="0.0.0.0" port="8081" />
</http:listener-config>
<vm:config name="VM_Config" doc:name="VM Config" >
<vm:queues >
<vm:queue queueName="toTransactionalVM" queueType="PERSISTENT"/>
</vm:queues>
</vm:config>
<flow name="reliable-data-acquisition">
<http:listener config-ref="HTTP_Listener_config" path="transactionalEndpoint"/>
<vm:publish config-ref="VM_Config" queueName="toTransactionalVM" sendCorrelationId="ALWAYS"/> (1)
</flow>
<!-- This is the application logic flow in the reliability pattern.
It is a wrapper around the sub-flow "business-logic-processing". -->
<flow name="main-flow">
<vm:listener doc:name="Listener" config-ref="VM_Config" queueName="toTransactionalVM"
transactionalAction="ALWAYS_BEGIN"/> (2)
<flow-ref name="business-logic-processing"/>
</flow>
<!-- In this sub-flow, the application starts processing the message. -->
<sub-flow name="business-logic-processing">
<logger level="INFO" doc:name="Logger" />
<!--
This is where the actual business-logic is performed.
-->
</sub-flow>注意事项
在实现可靠性模式时,需要考虑以下几点:
- 当连接器(消息源)允许时,始终使用事务。
- 当希望在同一个事务中登记多个托管资源时,使用XA事务来桥接消息源。
- JMS的可靠性与MQ实现及其配置方式有关。大多数MQ实现允许配置消息是仅存储在内存中还是持久化。只有将MQ服务器配置为在转发消息之前持久存储消息,才能实现可靠性。否则,可能会在MQ服务器崩溃时丢失消息。
- 可靠性会影响性能。
- 如果可靠获取流中的出站操作不是事务性的(例如,从文件到FTP的流),请在Try Scope内执行该操作。通过这种实践,可以确认操作是否成功完成,如果失败,则记录错误消息。
11.测试
可靠性测试是一项重要的软件测试技术,由团队执行,以确保软件在每种环境条件下以及在指定的时间内始终如一地执行和运行。
该测试包含了功能测试和非功能测试的结果,例如压力测试、安全测试、功能测试、生产测试等。
可靠性测试的类型
- 特性测试:特性测试的目的是检查软件的特性和功能。
- 回归测试:这是为了检查应用程序中是否因为修复了以前的错误而引入了新的错误。这是在每次更改或更新软件特性和功能之后进行的。
- 负载测试:该测试是为了确认软件在最高工作量条件下的功能。
12.验证模式
JSON模块验证可用于根据JSON模式验证JSON。它将显示JSON有效负载的确切错误,因此可以将传入的JSON错误通知客户端。
类似地,有XML模块验证来根据XML模式验证XML。
因为有适当的验证,这些模块可以防止在流中进一步抛出错误,从而节省了确保可靠性的额外工作,例如持久化到DB、推入到DLQ等。
13.错误处理
应该正确处理上述任何实践抛出的错误,以确保没有数据丢失。
如何处理错误
a. REDELIVERY_EXHAUSTED
当引发错误的执行次数大于配置的maxRedeliveryCount值时,从配置Redelivery策略的任何地方抛出。
在这种情况下,在“On Error Continue”作用域上,确保将消息(正在处理的当前消息)传送/持久化到死信队列(DLQ)中,这样它就不会丢失。一旦持久化到DLQ中,任何类型的通知都可以发送到相关团队。
XML示例代码:
XML
<on-error-continue type="REDELIVERY_EXHAUSTED">
<vm:publish queuename="errorqueue"/>
</on-error-continue>b. RETRY_EXHAUSTED
当某个执行块的重试已经耗尽时,从给定操作或从Until Successful作用域抛出。
在这种情况下,在“On Error Continue”作用域内,确保将消息(当前消息正在处理中)推送/持久化到死信队列(DLQ)中,以使其不会丢失。一旦持久化到DLQ中,就可以向相关团队发送通知失败的任何类型的通知。
XML示例代码:
XML
<on-error-continue type="RETRY_EXHAUSTED">
<vm:publish queuename="errorqueue"/>
</on-error-continue>c.事务中的任何错误
当事务期间发生错误时,应用程序必须处理错误并继续执行或执行回滚。
On Error Propagate- 如果on-error-propagate错误处理程序位于开始事务的组件对应的错误处理程序范围内:在执行on-error-propagate作用域的处理器之前,事务将被回滚。这意味着错误处理程序中的处理器不在事务中运行。
- 如果on-error-propagate错误处理程序位于没有启动事务的元素中:事务不会回滚,on-error-propagate错误处理程序中的处理器在事务中运行。
On Error Continue错误得到处理,事务保持活动状态并能够提交。on-error-continue中的处理器在事务中运行。
在上述任何一种情况下,确保将当前消息推入DLQ或DB等存储系统。
d.批处理作业错误
Mule有三个选项来处理记录级别的错误:
1.Finish processing停止当前作业实例的执行。完成当前正在执行的记录的执行,但不要从队列中提取更多记录,并将作业实例设置为FAILURE状态。调用OnComplete阶段。
2.继续处理批处理,不考虑任何失败的记录,使用acceptExpression和acceptPolicy属性指导后续批处理步骤如何处理失败的记录。
3.继续处理批处理,不考虑任何失败的记录(使用acceptExpression和acceptPolicy属性指示后续批处理步骤如何处理失败的记录),直到批处理作业积累了失败记录的最大数量,此时执行将停止,就像选项1中那样。
在最后两种情况下,在ONLY_FAILURES批处理步骤中,将失败的记录推入DLQ或DB之类的存储系统。
e.来自第一个成功路由器的错误
当配置的路由都没有成功执行时,通过将消息推入DLQ或DB之类的存储系统来处理抛出的错误。
结论
这是在一个地方整理各种可靠性问题的解决方案的努力,热衷于构建高可靠性应用程序的Mule开发人员可以参考一些详尽的列表。
需要记住的是,其中一些解决方案/实践的性能可能会受到影响,因此在选择时需要谨慎。
原文标题:Best Practices for Creating Highly Reliable Applications in Mule 4,作者:Praveen Sundar