讲师介绍
林静,现任货拉拉核心基础设施技术专家、数据库中间件团队负责人,对数据库中间件研发有深刻的理解和丰富的实战经验;曾任摩托罗拉子公司UniqueSoft的Java专家,主导自动逆向工程系统Java方向研发;曾任阿里本地生活中间件技术专家,负责DAL中间件的研发,同时负责多活体系中全局控制中心和数据层的建设。
分享概要
一、混合云自建数据库中间件背景介绍
二、混合云自建数据库中间件实践
三、混合云自建数据库中间件展望
四、混合云自建数据库中间件思考
一、混合云自建数据库中间件背景介绍
货拉拉是一家业务分布国内海内外多个国家和地区的互联网企业,在不同的地区,我们会根据当地的情况,选择合适的云商。因此我们的基础就是一个多云多数据中心的架构。
1、问题与挑战

随着业务的不断发展,数据的总量不断膨胀,同时业务线也在不断增多。这给数据库带来了巨大的压力,因为它们需要处理海量的数据,并保持高性能和稳定性。
此外,我们的技术底层也在不断演进,新老服务也在不断交替。这就要求我们的数据层架构能够适应多语言异构的环境,同时具备高度的可扩展性和可维护性。
在混合云背景下,这些挑战变得更加复杂。因为混合云意味着我们的架构设计必须具有跨云特性,需要能适配不同的云环境,不依赖特定的云厂商的独有产品。从业务研发视角看,就是统一的解决方案,不需要重复开发的代码来适配底层环境。
2、历史HLL服务架构
我们先来看一下曾经的架构。

1)业务层存在多语言技术栈并存,技术适配困难的问题。技术栈众多,本身不是问题,问题在于缺乏统一的维护,当需要做公司级别的改造时,需要各个业务团队只能各自为政,不能形成有效的合力。
2)基础中间件很多时候还停留在部署起来能跑的程度。缺乏长效的治理,比如apollo这种配置中心就部署了多套,各个业务团队各自维护一份配置数据,关键数据散落各处没法管理。
3)数据库中间件其实也是这种情况。本身无论是“SmartCLient”方式也好,“Proxy”方式也好,都是比较优秀的开源解决方案。问题在于缺乏系统性的建设,没有完整的监控报警,没有相应的故障应急,没有自动化运维,不能满足企业对高可用和可运维的诉求。
4)DB层客观存在的云商差异让运维工作复杂度倍增。
总的来说,当时的整体架构处于勉强能够应对业务诉求的程度,但在稳定性和可运维性上存在不足。
二、混合云自建数据库中间件实践
1、HLL数据层架构
我们再来看当前的技术架构。当前的HLL架构已经补齐了大部分的中间件。

接入层包含了开源的统一流量网关KONG,自研服务化网关LAPIGateway,自建安全网关WAF,商用高防网关等组件。
基础框架方面,建设了基础框架JAF,微服务框架HLL-SOA,任务系统LLjob,监控报警系统HLL-Monitor等模块。
变化最大的其实是数据库中间件的部分。我们通过自建数据库中间件DBProxy统一了这一层的标准:
- 异构proxy架构,实现了对上层开发语言的兼容;
- 集成HLL体系,集成了HLL的DMS,LLMonitor,配置中心,注册中心等基础组件,让数据库中间件不再是数据孤岛,和各个组件形成合力;
- 跨云适配 + 场景化分库分表,让DBProxy能够屏蔽底层差异,给业务服务提供一致的体验。帮助业务服务高效安全的从历史存留各种数据库中间件迁移到DBProxy上来;
- 高可用设计,让DBProxy本身不会成为系统的弱点;
- 高性能架构,让DBProxy拥有超过同类的产品的性能表现;
- DB稳定性保障,让DBProxy能够满足各个云台下rds通用的稳定性诉求;
- 企业级的可运维性,是DBProxy能够解决历史遗留问题的核心。我们有严格的开发流程,全面的应急预案,完善的监控报警体系,自动化的管理运维手段。
随着自建数据中间件的落地,让HLL的系统的稳定性和可运维性都获得了巨大的提升。
2、为什么选择自建

选择自建数据库中间件,是混合云背景下的必然选择。
大厂目前普遍都有自己的数据库中间件,经历过大厂复杂业务场景考验,无论是功能还是稳定性都值得信赖。可惜就是不开源,而开源出来的产品和内部线上产品往往有代差。
云产品是我们比较理想的选择,上线快、稳定性好、功能成熟,但不能做到跨云通用,不符合我们“跨云通用”的基本诉求。
开源产品帮助我们解决了许多问题。无论是功能丰富的开源产品,还是友好的开源社区,都让我们在系统演化的道路上受益匪浅。伴随着企业的发展,我们对产品提出了更多定制化的需求,而这些肯定是不能通过开源产品实现的。
因此我们选择了自建数据库中间件这条道路。
3、数据库中间件架构
HLL数据库中间件的架构还是比较简单的,我们由下往上看:

1)技术栈:
- 采用Java技术栈,为了保证GC停顿时间尽量短,使用了ZGC这种低停顿垃圾回收方式;
- 采用了异步网络框架 Netty,保证系统对高并发的支持;
- 采用了事件异步驱动编程模型,保证了系统的高可用和高性能;
- 采用异构Proxy架构,保证了对多语言的兼容。
2)可运维性(“平滑”是最主要的关键词):
- 平滑升级,连接预热,快启动,慢退出,连接平滑释放等细节来达成变更平滑、管理平滑、运维平滑;
- 监控报警,是一个系统长期稳定的关键之一。在越早的阶段发现问题,问题的影响就越小,而监控报警是发现识别问题的关键。监控报警既要全面,又要准确,必须有一个持续收敛保鲜的过程才能保证它的有效。
3)高可用设计(体现在方方面面):
- 分集群部署,是解决不同业务对资源有不同侧重的问题;
- 拥塞设计是非常重要的。假设一条SQL返回100个G的结果,如果没有合理的拥塞机制,轻易就能撑爆DBProxy的内存。所以必须有合理的拥塞机制,DBProxy要尽快把数据吐到客户端,要像TCP滑动窗口一样,根据客户端的数据接收能力,对数据流速作出调整;
- 线程收敛是DBProxy性能保障的核心之一,一旦线程数过多,额外的内存和CPU开销就会增多。同时很多框架机制都是和线程数相关的,比如ZGC在线程数增多的时候,效果就会变差。
4)功能特性比较多,我们挑几个来简单聊一聊:
- 限流:我们的限流采用的是限制DB并发数的令牌桶算法。为什么不是采用更好理解的QPS或者连接数限制呢?主要因为这两个维度在不同的SQL应用场景下数值差距太大,需要付出非常大的运维成本。而基于DB核数设定并发数的动态限流,更符合数据库领域的特征。
- 动态index hint注入:这个功能解决的是,SQL由于数据量变化等原因没有走到合理的索引,变异成慢SQL的问题。在业务高峰的时候直接在DB上加索引,或者改业务SQL是不现实的。通过DBProxy,可以动态给SQL添加index hint,等过了业务高峰期,再常规修复是非常安全高效的做法。
- ShardingMapingKey:这个功能是为满足Sharding表的额外映射诉求。比如有一张表包含两个唯一ID,根据其中一个ID做分库分表后,用另一ID查数据就只能全分片扫,才能找到对应的数据,这可能导致上千倍的读放大。ShardingMapingKey能自动维护一张Mapping表,来管理两个ID的映射关系,这样就避免全分片扫的问题。
总的来说,没有什么出人意料的技术技巧,有的只是为了满足业务的诉求,而细细打磨的过程。
4、数据库中间件建设成果

主要成果是:
- 跨云通用的MySQL水平扩容能力。理论上能够支持1024倍的扩容,能够满足企业未来3-5年的业务发展诉求。
- 跨云通用的MySQL保护能力。能够阻断常规的MySQL风险,具备应对各种突发异常的应急能力。
此外,HLL数据库中间件具备低延迟、高可用、低成本的特性。HLL DBProxy已经上线快3年了,自身一直保持0故障,通过拦截异常SQL,消弭流量冲击,阻挡连接风暴等能力,为数据库提供了强有力的保护。
5、数据库领域还有哪些问题

首先是数据安全问题:过去我们的SQL审计只能由业务研发,在业务逻辑中插入特定代码实现,存在覆盖不全、成本高、推进难的问题。
然后是SQL治理问题:由于我们的数据库全部由云商托管,很多细节不再对DBA和研发暴露。观察SQL详情的手段只有类似吞吐量,RT95线这样的监控报警,不能很好地了解SQL执行的细节,存在SQL治理粒度不够细,SQL无法追踪的问题。
还有是SQL预警问题:很多时候,风险SQL只有到了生产并造成一定破坏后,我们才能发现,这个时候已经只能亡羊补牢了。虽然亡羊补牢,为时未晚,但我们更想要防患于未然。
最后是压测SQL流量失真问题:压力测试是保障系统容量的核心手段,但在DB领域,我们经常因为测试SQL和线上真实运行的SQL存在差异,而无法有效验证出数据库的真实容量,存在容量风险和资源浪费的双重问题。
6、为什么不直接使用云上SQL治理产品

1)部分云商提供了类似的产品,但价格普遍比较昂贵。由于成本压力,我们只会开几天然后尽早关闭,只能应急,不能当作常规手段。
2)在这些领域,不同云商提供的产品服务差别非常大。有的云商提供了非常丰富的相关产品服务,但在另外的云商那里却是一片空白。跨云差异巨大,完全不能通用。
3)云商提供的能力和我们的实际需求还是存在一些差异,毕竟云服务只会支持通用场景,而不会按照企业的需求做定制。
4)云上产品也不是只要能用就好,还要考虑集成问题,比如研发使用习惯,监控报警,沟通,审计,管控等。
7、基于DBProxy的旁路SQL能力建设

SQL安全审计:基于DBProxy的“SQL安全审计”能力,对业务没有侵入,随着DBProxy对业务的全面覆盖,所有的DB都自动纳入了审计范围。解决了推广覆盖难、接入成本高的问题。
SQL深度洞察:基于DBProxy的“SQL深入洞察”能力,不仅收集分析了SQL的执行细节,而且集成了SQL指纹(SQLID)和业务调用的Trace信息,解决了SQL观察粒度粗、难以追踪的问题。
SQL线下预警:“SQL深入洞察”能够在预发环境就识别出风险SQL,解决了问题SQL后知后觉的问题。
SQL流量仿真:“SQL流量仿真”能够精准还原线上真实SQL流量,保障系统数据库容量安全,同时避免资源浪费。
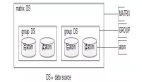
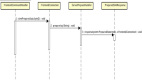
8、SQL深度洞察效果图

这里有两个主要的应用场景:
- 一个场景是,先看DB整体情况,比如影响行数过多的,RT太长的,可以根据SQLID反溯它的来源。
- 另一个场景是,先通过业务视角发现某条SQL比较反常,可以通过SQLID来查看它的更详细的情况,比如使用频率和RT抖动幅度等。
四、混合云自建数据库中间件思考
1、下一步最直接的挑战是“多AZ”

“多AZ”架构可以简单理解为云上的同城多活架构。
云上“多AZ”对比一般自建同城多活,优势在于成本更低、粒度更灵活。由于基础设施的部分已经由云商建设好,企业可以有选择性地落地多AZ架构,比如只有MySQL使用多AZ架构,其他部分保持单AZ。
图中是一个简化的三AZ部署案例,每个AZ可以承担50%的流量。任意一个AZ出问题,系统都能正常工作。
“多AZ”架构还是有门槛的:
- 首先是AZ间的网络延迟(一般AZ间的延迟在1-10ms)。必须充分地考量业务系统的延迟敏感度,确保业务系统能够在这种延迟中正常工作。
- 然后是IT成本。在刚才的例子中,我们有三个50%的AZ,假设容量和IT成本成正比,我们起码需要承担1.5倍的IT成本。
- 还有一个不能忽视的部分是AZ间的网络稳定性。AZ间的网络稳定性是远不如AZ内部的,如果业务系统自身不够健壮,网络一抖就崩溃。那么这种情况下“多AZ”的架构并不会提升系统稳定性,反而会有所降低。
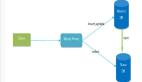
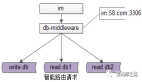
2、当前多AZ高可用架构设计

建设AZ级别的故障转移能力,对企业来说是十分必要的。我们之前遇到过一次类似的故障:由于第三方的意外操作,机房内部100多个机架断电,相关服务组件全部故障,系统不可用持续长达1个多小时。假如当时我们的系统具备AZ级别故障转移能力,这次事故就能完全避免掉。
图中是一个简化的多AZ架构设计,采用的是双AZ对等部署的方式。系统整体没有额外的IT成本,AZ故障后,利用K8S的弹性能力,在健康的AZ内快速弹出足够的容量。
而数据库中间件在“多AZ”架构里是存在不足的:
- 首先是AZ间延迟放大问题。当业务节点和DBProxy不在同一个AZ时,一个SQL请求需要经历两次跨AZ延迟,这对系统RT容忍性提出了更高的要求。
- 然后是弹性能力不足问题。我们需要投入额外的IT成本和运维开销来适配AZ容灾场景。
这方面“RedisMesh”已经领先了一步,通过K8S DaemonSet+Sidecar的近客户端部署架构,规避了中间件放大跨AZ延迟的问题,也解决了弹性问题。
3、未来数据库中间件的展望

未来我们期望把DBProxy、KafkaGateway这样的数据层中间件都转型到sidecar模式,和现有的RedisMesh集成,打造新一代的数据层中间件DataMesh。
DataMesh不仅具备原来数据库中间件的基础能力,而且具备远超当前数据库中间件的云环境适应性,能够灵活适配未来复杂多变云上架构。
当然这个过程不是一蹴而就的。
4、混合云数据库中间件走向何处

对于数据库中间件前进的方向和节奏,我们是这样的考虑的。
首先是避免“唯技术”,技术是手段不是目的,不能因为喜欢什么技术就投入进去。
然后“比业务快半步”,就是说基础技术要像一碗刚做好的面一样,温度刚刚好。太晚了不行,不能让业务饿着了,太早了也不行,面就凉。
最后是“面向云原生”,我们不能试图去撇开云环境去做什么,而应该更靠近云,让业务服务更容易享受的云时代的便利。
三、混合云自建数据库中间件展望
1、无论什么时候稳定性都是第一位

我们的核心工作是为企业带来稳定性价值和效率价值。稳定性永远是第一位的。这方面,我们比较信奉海恩法则。
简单来说,故障的发生是有迹可循的,我们应该通过流程和机制把故障消灭在萌芽状态。
2、高可用设计有哪些要点

就像前面说的高可用是可以通过建设来达成的。简单总结下来就是:
- 做最坏的打算,不要有侥幸心理;
- 要解决大部分人的问题,符合大部分人的使用习惯,不要标新立异;
- 不要单打独斗,借助整个公司基础设施的力量,形成合力;
- 把好的机制和流程沉淀到工具去。
3、数据库中间件研发培养

最后跟大家分享一点关于如何培养数据库中间件研发的想法,培养中间件领域的研发,应该从这三方面入手:领域知识、产品意识、编程技巧。一名优秀的数据库中间件开发应该同时具备这三方面的能力,三者缺一不可。