今天介绍一篇南大今年4月份发表的文章,主要探讨了多元时间序列预测问题中,独立预测(channel independent)和联合预测(channel dependent)二者效果的差异、背后的原因以及优化方法。

论文标题:The Capacity and Robustness Trade-off: Revisiting the Channel Independent Strategy for Multivariate Time Series Forecasting
下载地址:https://arxiv.org/pdf/2304.05206v1.pdf
1、独立预测和联合预测
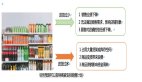
多元时间序列预测问题中,从多变量建模方法的维度有两种类型,一种是独立预测(channel independent,CI),指的是把多元序列当成多个单变量预测,每个变量分别建模;另一种是联合预测(channel dependent,CD),指的是多变量一起建模,考虑各个变量之间的关系。二者的差异如下图。

这两种方式各有特点:CI方法只考虑单个变量,模型更简单,但是天花板也较低,因为没有考虑各个序列之间的关系,损失了一部分关键信息;而CD方法考虑的信息更全面,但是模型也更加复杂。
2、哪种方法更好
文中首先做了详细的对比实验,在多个数据集,观察CI方法和CD方法哪种效果更好(采用线性模型)。文中实验得到的一个核心结论是:CI方法在大多数任务上表现的更好,并且效果方差也更小。下面这张图中可以看到,CI的MAE、MSE等指标在各个数据集上基本都小于CD,同时效果的波动也更小一些。

从下面的实验结果可以看到,CI相比CD,在绝大多数预测窗口长度和数据集上,效果都是提升的。

为什么CI方法在实际应用中比CD效果更好、更稳定呢?文中进行了一些理论证明,核心的结论是:真实数据往往存在Distribution Drift,而使用CI方法有助于缓解这个问题,提升模型泛化性。下面这张图,展示了各个数据集trainset和testset的ACF(自相关系数,反映了未来序列和历史序列之间的关系)随时间变化分布,可以看到Distribution Drift在各个数据集上是广泛存在的(也就是trainset的ACF和testset的ACF不同,即两者的历史与未来序列的关系不同)。

文中通过理论证明了CI对于缓解因此Distribution Drift有效,CI和CD之间的选择,是一种模型容量和模型鲁棒性之间的权衡。CD模型更加复杂,但是也对于Distribution Drift更敏感。这其实和模型容量与模型泛化性之间的关系类似,越复杂的模型,模型拟合的训练集样本越准确,但是泛化性较差,一旦训练集和测试集分布差异较大,效果就会变差。
3、如何优化
针对CD建模的问题,文中提出了一些优化方法,可以帮助CD模型更具鲁棒性。
正则化:引入一个正则化损失,用序列减去最近的样本点作为历史序列输入模型进行预测,同时使用平滑约束预测结果,让预测结果和最近邻的观测值偏差不要太大,使得预估结果更平;

低秩分解:将全连接参数矩阵分解成两个低阶矩阵,相当于减少了模型容量,缓解过拟合问题,提升模型鲁棒性;
损失函数:采用MAE替代MSE,降低模型对于异常值的敏感度;
历史输入序列长度:对于CD模型来说,输入的历史序列越长,可能反而会造成效果的下降,也是因为历序列越长,模型越容易受到Distribution Shift的影响,而对于CI模型,增长历史序列长度可以比较稳定的提升预测效果。
4、实验效果
文中将上面提到的改进CD模型的方法在多个数据集上进行实验,相比CD取得比较稳定的效果提升,说明上述方法对于提升多元序列预测鲁棒性有比较明显的作用。此外,文中也列举了低秩分解、历史窗口长度、损失函数类型等对于效果的影响实验结果。