在前面的文章中,松哥和小伙伴们分享了 MySQL 中,InnoDB 存储引擎的数据结构,小伙伴们知道,当我们使用索引进行搜索的时候,每一次的搜索都是在某一棵 B+Tree 中搜索的,如果使用了二级索引的话,可能还会涉及到回表。
那么现在问题来了,如果我们的搜索条件中包含两个字段,且这两个字段都有独立的索引,那么 MySQL 会怎么处理?今天我们就来讨论下这个话题。
1. 问题重现
为了方便小伙伴们理解,我先通过 SQL 来把我的问题重复一下。
我使用的测试数据是 MySQL 官网提供的测试数据,相关的介绍文档在:
- https://dev.mysql.com/doc/employee/en/
相应的数据库脚本在:
- https://github.com/datacharmer/test_db
小伙伴们可以自行下载这个数据库脚本并导入到自己的数据库之中。
在官方提供的案例中,有一个这样的表:
CREATE TABLE `film_actor` (
`actor_id` smallint unsigned NOT NULL,
`film_id` smallint unsigned NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`,`film_id`),
KEY `idx_fk_film_id` (`film_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;在这个表中有两个索引,其中一个是主键索引,主键索引是一个联合索引,还有一个是根据 film_id 建立的普通索引。现在假设我有如下 SQL 需要执行:
select * from film_actor where film_id=1 or actor_id=1;那么问题来了,这个查询会用到索引吗?
想知道有没有用到索引,用 explain 关键字看一下就知道了:
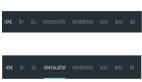
explain select * from film_actor where film_id=1 or actor_id=1;执行结果如下:

小伙伴们看到,此时 type 是 index_merge,possible_keys 和 key 中,都给出来了两个索引,Extra 中的值为 Using union(idx_fk_film_id,PRIMARY); Using where。
看起来是用了索引,但是具体是怎么用的,这个执行计划该如何解读呢?
这个其实就是一个索引合并,接下来我们就来看下到底什么是索引合并。
2. 索引合并
index_merge 表示索引合并,当同一个表中的搜索条件中同时存在多个索引的时候,MySQL 会分别对这些索引进行扫描,然后将扫描结果进行合并,合并分三种情况:
- 对各自扫描结果求并集(unions)。
- 对各自扫描结果求交集(intersections)。
- 前两者的组合。
在官方文档中给了四个可能会用到索引合并的例子:
SELECT * FROM tbl_name WHERE key1 = 10 OR key2 = 20;
SELECT * FROM tbl_name
WHERE (key1 = 10 OR key2 = 20) AND non_key = 30;
SELECT * FROM t1, t2
WHERE (t1.key1 IN (1,2) OR t1.key2 LIKE 'value%')
AND t2.key1 = t1.some_col;
SELECT * FROM t1, t2
WHERE t1.key1 = 1
AND (t2.key1 = t1.some_col OR t2.key2 = t1.some_col2);有的时候,我们写的 SQL,明明可以合并,但是系统却没有合并,此时我们对查询条件做一些调整,例如:
- (x AND y) OR z => (x OR z) AND (y OR z)
- (x OR y) AND z => (x AND z) OR (y AND z)
另外需要注意的是,索引合并不适用于全文索引。
在 explain 执行计划中,如果用到了索引合并,Extra 字段的值一般分为三种情况,分别是:
- Using intersect(...)
- Using union(...)
- Using sort_union(...)
上文案例属于第二种情况。
那么接下来把这三种情况都来和小伙伴们聊一下。
2.1 Using intersect(...)
这个就是对多个扫描结果求交集。
并不是只要涉及到多个索引,且是 AND,就会触发 Using intersect,有两个条件:
- 如果是二级索引,则必须是等值查询。如果二级索引是复合索引,则复合索引的每一列都必须覆盖到,不能只是其中的某几列。
- 主键索引可以是范围查询。
我们来看官方给出的一个例子,如下:
key_part1 = const1 AND key_part2 = const2 ... AND key_partN = constNkey_part1 - key_partN 就是复合索引中的所有列(必须是所有列)。
对于第 2 点,如果涉及到主键索引,则主键索引可以是范围查询,例如下面这样(但是二级索引依然只能是等值查询):
SELECT * FROM innodb_table WHERE primary_key < 10 AND key_col1 = 20;如果是复合索引和普通索引,那么复合索引必须覆盖到所有列且复合索引和普通索引都要是等值匹配才可以,例如下面这样:
SELECT * FROM tbl_name WHERE key1_part1 = 1 AND key1_part2 = 2 AND key2 = 2;key1_part1 和 key1_part2 分别表示同一个复合索引的第一列和第二列(一共就两列),此时和 key2 一起作为查询条件,也有可能会用到索引合并。
上面这些情况都是在各自搜索完成之后求交集。
举一个简单的例子吧,还是 MySQL 官方的测试数据,sakila 库中有一个 actor 表,该表结构如下:
CREATE TABLE `actor` (
`actor_id` smallint unsigned NOT NULL AUTO_INCREMENT,
`first_name` varchar(45) NOT NULL,
`last_name` varchar(45) NOT NULL,
`last_update` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`actor_id`),
KEY `idx_actor_last_name` (`last_name`)
) ENGINE=InnoDB AUTO_INCREMENT=201 DEFAULT CHARSET=utf8mb3;可以看到,有一个主键,有一个普通索引,我执行如下 SQL:
select * from actor where actor_id<10 and last_name='WAHLBERG'执行计划如下:

可以看到,用到了索引合并,且是 Using intersect。
2.2 Using union(...)
求并集的跟求交集的比较像,就是 AND 变成了 OR。
当二级索引是等值查询,或者是组合索引,但是要求组合索引的每一列都必须覆盖到,不能只是覆盖到部分列,例如下面这个查询条件:
key_part1 = const1 OR key_part2 = const2 ... OR key_partN = constNkey_part1~key_partN 就是同一个复合索引的不同列,同时在该复合索引中,也一共就只有这 N 个字段,这种情况就会用到 Using union。
InnoBD 表上的主键范围查询也有可能会触发 Using union。
符合 2.1 小节的情况,将 AND 换成 OR 之后,也有可能会触发 Using union。
这个例子就不用举了,文章一开始的就是。
2.3 Using sort_union(...)
很明显,2.2 小节的条件比较苛刻,二级索引必须是等值查询才能触发 Using union,而我们日常使用的时候,范围查询也是非常常见的,所以又有了 Using sort_union,这个的要求就宽松一些了:
- 二级索引也可以按照范围匹配
- 复合索引也不用覆盖所有列
举个例子,如下面的 SQL:
SELECT * FROM tbl_name
WHERE key_col1 < 10 OR key_col2 < 20;
SELECT * FROM tbl_name
WHERE (key_col1 > 10 OR key_col2 = 20) AND nonkey_col = 30;二级索引范围搜索,也有可能触发 Using sort_union 的。
2.4 索引合并原理
在 2.1 小节和 2.2 小节,分别是求交集和求并集,为了 intersect 和 union 操作方便,在各个单独的索引扫描的时候,都是要获取到有序的主键值的合集,各个索引都获取到有序的主键,然后求交集或者并集就会比较方便。
因此,在 2.1 和 2.2 小节,都是主键索引可以范围搜索,因为主键索引本身主键就是有序的;二级索引则有诸多限制,这诸多限制的最终目的都是为了做到最终拿到的主键值是有序的。
例如:
- 二级索引必须等值匹配,等值匹配意味着最终拿到的 B+Tree 的叶子上的主键值就是唯一的;二级索引如果可以按照范围查找,那么最终从二级索引的 B+Tree 的叶子结点上拿到的主键值就不是有序的了。
- 类似的,复合索引必须覆盖到所有列也是相似的原因,因为如果没有覆盖到所有列,意味着最终拿到的主键值也是无序的。
2.3 小节允许二级索引按照范围搜索,这是因为在 Using sort_union 中,会先对拿到的主键值进行排序,然后才会去求交集或者并集,当然,相比于 2.1 和 2.2 小节,2.3 小节的性能也会降低一些。
3. 索引合并的问题
索引合并看着似乎提升了 MySQL 搜索的性能,然而,一般出现索引合并,大概率都是因为索引创建的不合理,我们需要重新审视自己的索引。
如上面 2.3 小节所述,这种方式在查询的过程中需要缓存临时数据、需要排序然后才能求交集或者并集,这些操作都会消耗掉大部分的 CPU 和内存资源。并且这些消耗不会被计算到查询成本中,因为 MySQL 优化器只关心随机页面的读取问题,并不会关心这里涉及到的这些额外计算问题,所以,在一些极端情况下,索引合并的性能可能还不如全表扫描。
因此,有时候如果我们确定自己不需要索引合并,那么可以通过 ignore index 来忽略掉一些索引,如下(对比 2.1 小节截图):

也可以通过 optimizer_switch 来关闭索引合并功能,如下:

好啦,索引合并就和小伙伴们聊这么多吧~感兴趣的小伙伴也可以尝试下哦!