本月初,Meta 发布「分割一切」AI 模型(Segment Anything Model,简称 SAM),可以为任何图像或视频中的任何物体生成 mask,甚至包括没有见过的物体和图像。有人将这一研究比喻为计算机视觉领域的 GPT-3 时刻之一。
Meta 表示,「SAM 已经学会了关于物体的一般概念,可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM 足够通用,可以涵盖广泛的用例,并且可以在新的图像『领域』即开即用,无需额外的训练。」
该模型一经发布,迅速引起计算机视觉领域的轰动,更是有人发出「CV 不存在了」这样的感慨。
然而目前 SAM 的应用主要集中在图像领域,在视频领域的应用仍然未被深入探索,尤其是对视频目标的跟踪 / 分割,仍是巨大挑战。同时,现有的跟踪模型的局限性也很明显,如,场景切换在现实视频中很常见,而现有的跟踪模型只能在单一场景下实现目标的精准定位;现有的模型要求准确的模版初始化,需要人为提供目标边界框或精准掩码,因而可用性被极大限制。
近日,南方科技大学郑锋团队提出了「跟踪一切」(Track Anything Model ,TAM)的交互工具,其在视频中实现高性能的交互式跟踪和分割。Track Anything 是基于 SAM 的二次创作模型,适用于视频领域任意目标的跟踪任务,可以通过简单的鼠标点击实现对任意视频任意目标的像素级跟踪,实现了目标跟踪的交互性、灵活性、可用性。

- 论文地址:https://arxiv.org/pdf/2304.11968.pdf
- 项目地址:https://github.com/gaomingqi/Track-Anything
- Demo 地址:https://huggingface.co/spaces/watchtowerss/Track-Anything
Track Anything:交互式跟踪任意视频任意目标
Track Anything 效果到底如何呢?我们先从几个示例来说明。首先是多目标跟踪与分割。《清明上河图》大家早已耳闻,画中人物众多、形态各异,其间还穿插各种动作等等。想要跟踪里面的目标难度还是比较大的。下面视频显示 Track Anything 很好的跟踪了物体。
接下来考察 Track Anything 在快速运动场景下的跟踪能力。众所周知,打篮球需要动作敏捷、健步如飞…… 用 AI 技术跟踪一位篮球运动员并不容易,加之运动员动作幅度大、相互之间出现遮挡等,都加大了跟踪难度,出现错误跟踪、漏跟踪情况。但从下面展示的效果来看,即便是在瞬息万变的篮球比赛,Track Anything 跟踪效果都做的非常好。
接下来,我们在看一个示例。从下面视频中可以看到,一位身姿矫健的男生灵活的跨越众多障碍,即便人的运动速度再快、动作再复杂等,Track Anything 都能很好的处理。
由于 Track Anything 跟踪效果非常好,受到广大网友的好评。就像下面这位网友所说的:「这项研究给人一种强烈的终结者的感觉。SAM 在分割图像方面很在行,但在视频方面却不出色,而TMA仅通过少量人工输入,就能很好的实现对视频中物体的跟踪与分割。」

技术介绍
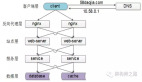
郑锋团队通过以使用者为中介的 SAM 与 VOS 模型的交互式组合,提出了 Track Anything 工具,它拥有强大的视频目标跟踪能力,并提供用户友好的操作界面,只需要简单的点击操作,就可以任意地跟踪用户感兴趣的一个或多个目标区域,还可以根据用户需求灵活调整目标对象,并自带用户纠错和视频编辑功能。其技术流程如下:
1 基于 SAM,用户通过正负样本点的选取,确定目标对象在视频中某一帧的空间区域。
2 使用用户确定的区域作为模板初始化跟踪模型。跟踪过程中,通过建立每个视频帧与模板区域之间的密集关联,实现将用户选取信息向整个视频的传递过程,从而实现目标跟踪。
3 跟踪过程中,用户可以随时暂停,同样通过正负样本选取的方式,实现对其他目标的追踪,或修正当前目标追踪的结果。
4 基于跟踪结果,用户可以使用目标擦除或视频修复功能,实现在视频中对特定区域的编辑。

总之,通过 Track Anything,使用者可以轻松地完成视频中单个或多个目标的精确标注,视频特定区域提取及编辑,以及长时 / 转场视频中的目标跟踪。
相关功能陆续上线中,欢迎大家试用!
郑锋团队不仅在视频领域研发了Track-Anything,还在图像和语言领域还推出了Caption-Anything系统。它是一个多功能的图像处理工具,结合了Segment Anything、Visual Captioning和ChatGPT在图像和语言领域的能力。项目地址:https://github.com/ttengwang/Caption-Anything/。