译者 | 布加迪
审校 | 重楼
近几个月来基于人工智能(AI)的聊天机器人风靡全球,一个原因是它们可以为各种用途生成或完善文本,无论策划广告活动还是撰写简历。

这些聊天机器人基于大型语言模型(LLM)算法,算法可以模仿人类智能,创建文本内容以及音频、视频、图像和计算机代码。LLM是一种AI,接受大量文章、书籍或网上资源及其他输入的训练,对自然语言输入给出类似人类的答复。
越来越多的科技公司已推出了基于LLM的生成式AI工具,用于企业自动化处理应用任务。比如,微软上周向数量有限的用户推出了一款基于OpenAI的ChatGPT的聊天机器人,它嵌入在Microsoft 365中,可以自动化执行CRM和ERP应用软件的功能。
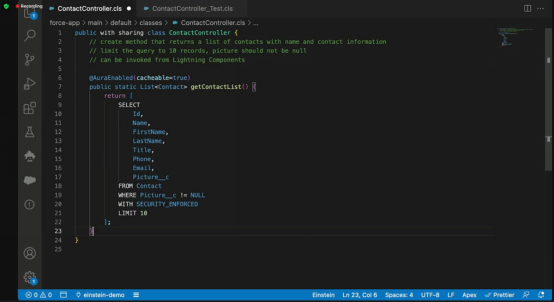
图1. 生成式AI通过用户提示创建软件代码的示例。在这个例子中,Salesforce的Einstein聊天机器人通过使用OpenAI的GPT-3.5大型语言模型被启用
比如说,新的Microsoft 365 Copilot可以在Word中用来创建文档的初稿,可能会节省数小时的撰写、溯源和编辑时间。Salesforce还宣布计划发布一个基于GPT的聊天机器人,用于与其CRM平台结合使用。
OpenAI的GPT-4等大多数LLM都被预先训练成预测下一个单词或内容的引擎,这是大多数企业使用它们的方式,即所谓的“开箱即用”。虽然基于LLM的聊天机器人也会出现一些错误,但经过预先训练的LLM比较擅长馈送总体上准确和引人注目的内容,这些内容至少可以作为起点。
然而,许多行业需要更多定制的LLM算法,能理解他们的行话,并生成针对用户的内容。比如说,面向医疗保健行业的LLM可能需要处理和解释电子健康记录(EHR),建议治疗方案,或根据医生笔记或语音记录创建患者医疗保健摘要。面向金融服务行业的LLM可以总结收益电话会议、创建会议文字记录,并执行欺诈分析以保护消费者。
综观众多行业,确保答复有很高的准确性至关重要。
大多数LLM都可以通过应用编程接口(API)来访问,该接口允许用户创建参数或者调整LLM的答复方式。发送给聊天机器人的问题或请求就叫提示(prompt),原因在于用户提示答复。提示可以是自然语言问题、代码片段或命令,但若要LMM准确地完成工作,提示必须切题。
而这种必要性已催生了一种新的技能:提示工程。
提示工程详解
提示工程是指制作和优化文本提示,以便大型语言模型达到预期结果的方法。SambaNova Systems是一家生产AI半导体的硅谷初创公司,该公司产品高级副总裁Marshall Choy表示:“提示工程帮助LLM实现产品原型和探索的快速迭代,因为它可以定制LLM,以便快速轻松地与任务定义保持一致。”
Hugging Face是一个创建和托管LLM的社区驱动平台,该平台的机器学习工程师Eno Reyes表示,可能对用户来说同样重要的是,提示工程有望成为IT和商业专业人士的一项重要技能。
Reyes在回复美国《计算机世界》杂志的邮件中说:“我认识的很多从事软件、IT和咨询业的人一直将提示工程用于个人工作。随着LLM日益融入到众多行业,它们大有提高生产力的潜力。”
Reyes表示,如果有效地运用提示工程,企业用户可以优化LLM,更高效准确地执行从客户支持、内容生成到数据分析的特定任务。
目前最有名的LLM:OpenAI的GPT-3是广受欢迎的ChatGPT聊天机器人的基础。GPT-3 LLM工作在一个1750亿参数的模型上,可以用简短的书面提示生成文本和计算机代码。OpenAI的最新版本GPT-4估计有多达2800亿个参数,因而极有可能给出正确的答复。
除了OpenAI的GPT LLM外,流行的生成式AI平台还包括一些开放模型,比如Hugging Face的BLOOM和XLM-RoBERTa、英伟达的NeMO LLM、XLNet、和GLM-130B。
由于提示工程是一门新兴的学科,企业依靠小册子和提示指南来确保其AI应用程序有最佳答复。甚至出现了新兴的提示市场平台,比如ChatGPT的100个最佳提示(https://beebom.com/best-chatgpt-prompts/)。
Gartner Research的杰出副总裁分析师Arun Chandrasekaran说:“有人甚至在出售提示建议。”他补充道,最近对生成式AI的大量关注突显了市场需要更好的提示工程。
他说:“这是一个比较新的领域。生成式AI应用常常依赖自我监督的大型AI模型,因此从它们那里获得最佳答复需要更多的专业知识、试验和额外的努力。我确信,随着技术日趋成熟,我们可能会从AI模型创建者那里得到更好的指导和最佳实践,以便有效地发挥AI模型和应用软件的最大功效。”
好的输出来自好的输入
LLM的机器学习组件自动从数据输入中学习。除了最初用于创建GPT-4等LLM的数据外,OpenAI还创建了名为强化学习人类反馈(RLHF)的机制,人训练模型如何给出类似人类的答复。
比如说,用户向LLM提出问题,然后写出理想的答案。随后用户再次向模型提出同样的问题,模型会提供其他许多不同的回答。如果这是基于事实的问题,我们希望答案保持不变;如果这是开放式问题,目的是给出多个类似人类的创造性答复。
比如说,如果用户让ChatGPT生成一首关于一个人待在夏威夷海滩上的诗,就会期望它每次生成一首不同的诗。Chandrasekaran说:“因此,训练人员所做的就是将答复从最好到最差进行评分。这是馈给模型的输入,以确保它给出更像人类或最佳的答复,同时试图尽量减少最糟糕的答复。但您提问题的方式对于从模型得到的输出有很大影响。”
组织可以通过摄取公司内部的自定义数据集来训练GPT模型。比如说,它们拿来企业数据后可以进行标记和注释,以提高数据质量,然后馈入到GPT-4模型中。这需要对模型进行微调,以便它能够回答该组织所特有的问题。
也可以针对特定行业进行微调。已经出现了一批新兴初创企业,它们使用GPT-4,摄取金融服务等垂直行业所特有的大量信息。
Chandrasekaran说:“它们可能会摄取Lexus-Nexus和彭博社的信息,可能摄取证券交易委员会(SEC)的信息,比如8K和10K报告。但关键是,模型在学习该领域所特有的大量语言或信息。因此,微调可能在行业层面或组织层面进行。”
比如说,Harvey是一家与OpenAI合作的初创公司,为法律专业人士创建所谓的“律师领航员”或ChatGPT版本。律师可以使用定制的ChatGPT聊天机器人来查找任何法律判例,以便某些法官为下一个案子做准备。
Chandrasekaran说:“我认为出售提示的价值与其说在语言上,不如说在图像上。生成式AI领域有各种各样的模型,包括文本转换成图像的模型。”
比如说,用户可以要求生成式AI模型生成吉他手在月球上弹奏的图像。Chandrasekaran 说:“我认为文本转换成图像的模型这个领域在提示市场更受重视。”
Hugging Face作为一站式LLM中心
虽然Hugging Face创建了一些自己的LLM,包括BLOOM,但该组织的主要角色是充当第三方机器学习模型的中心,就像代码界的GitHub那样。Hugging Face目前拥有超过10万个机器学习模型,包括来自初创公司和科技巨头的众多LLM。
由于新模型是开源的,它们通常在该中心上向公众开放,为新兴的开源LLM创建了一站式目的地。
要使用Hugging Face为特定的公司或行业对LLM进行微调,用户可以利用该组织的“Transformers”API和“Datasets”库。比如说,在金融服务业,用户可以导入预先训练好的LLM(比如Flan-UL2),加载金融新闻文章数据集,然后使用“Transformer”训练器对模型进行微调,以生成这些文章的摘要。与AWS、DeepSpeed和Accelerate的集成进一步简化和优化了训练。
据Reyes声称,整个过程可以用不到100行代码来完成。
另一种开始入手提示工程的方法需要用到Hugging Face的Inference API。据Reyes声称,这是一个简单的HTTP请求端点,支持80000多个Transformer模型。Reyes说:“这个API允许用户发送文本提示,并接收来自我们平台上的开源模型(包括LLM)的答复。如果您还想更简单一点,可以通过使用Hugging Face中心的LLM模型上的推理窗口组件实际发送文本,无需代码。”
少样本和零样本学习
LLM提示工程通常有两种形式:少样本学习和零样本学习或训练。
零样本学习需要输入简单的指令作为提示,以便从LLM生成预期的响应。其目的是教LLM执行新的任务,而不使用这些特定任务的已标记数据。零样本学习好比是强化学习。
反过来,少样本学习使用少量的样本信息或数据来训练LLM以获得所需的响应。少样本学习主要由三个部分组成:
- 任务描述:简短地描述模型应该做什么事,比如“把英语翻译成法语”。
- 例子:几个例子向模型表明了期望它做什么事,比如说“sea otter => loutre de mer”。
- 提示:新例子的开头,模型应该通过生成缺失的文本来完成该例子,比如:“cheese =>”。
据Gartner的Chandrasekaran声称,实际上,目前很少有组织拥有定制的训练模型来满足其需求,因为大多数模型仍处于开发的早期阶段。虽然少样本和零样本学习有所帮助,但学习提示工程这种技能很重要,对IT用户和业务用户来说都很重要。
Chandrasekaran说:“提示工程是如今应该拥有的一项重要技能,因为基础模型擅长少样本和零样本学习,但它们的性能或表现在很多方面受到我们如何有条不紊地设计提示的影响。这些技能对IT用户和业务用户都很重要,具体视用例和领域而定。”
大多数API允许用户运用自己的提示工程技术。据Reyes声称,每当用户向LLM发送文本,都有机会完善提示以实现特定的结果。
Reyes说:“然而,这种灵活性也为恶意用例打开了大门,比如提示注入。像微软必应的Sydney这样的事件表明,人们可以利用提示工程实现意想不到的用途。作为一个新兴的研究领域,解决恶意用例和红队渗透测试中的提示注入对未来至关重要,可确保在各种应用场合下负责任、安全地使用LLM。”
原文标题:How to train your chatbot through prompt engineering,作者:Lucas Mearian