1 背景介绍
为了满足不断增长的业务需求,转转逐步接入了大量的支付通道,而第三方系统的稳定性参差不齐,通道故障时有发生。当三方通道发生异常时我们的感知比较后置,比如大量的系统告警,甚至需要等业务或用户反馈才能感知到异常。作为承接全公司支付业务的核心系统,想要建立一个能给上游提供稳定服务的系统,仅依靠人工维护是远远不够的,因此建立一个完善的支付通道自动化管理系统就提上了日程。
2 设计目标
结合转转自身业务的特点,我们整理了支付通道自动化管理系统重点需要解决的问题:
- 多通道、多主体的通道监控能力;
- 故障快速发现,快速定位异常原因;
- 尽量做到无误报、无漏报;
- 通道故障自动化切换的能力;
3 技术选型
基于以上背景,再来看下技术方案的选型:
3.1 熔断器
提到故障的熔断和降级,首先想到的是市面上成熟的组件是否能够满足,比如 Hystrix,结合转转当前的业务场景来看,有以下几点无法满足诉求:
- 熔断器的降级熔断是基于接口的,无法满足通道和商户号维度的降级;
- 流量回切时可能异常仍未恢复,无法自定义探测流量的范围,比如回切时指定用户或业务,容易造成二次事故;
3.2 时序数据库
熔断器无法满足目标后,我们就将目标转向了自研,首先想做一个监控系统,底层一般都是选用时序数据库来存储,以下是热门时序数据库的排名:

时序数据库排名
结合转转目前的现状,我们最终将范围锁定在了 Prometheus 和基于 Redis 自研:
准确性方面: 由于 Prometheus 在设计上就放弃了一部分数据准确性,放弃一点准确性得到的是更高的可靠性,架构简单、数据简单、运维简单、节约机器成本与人力成本。
通常对于监控系统,数据拥有少量的误差是可以接受的,而对于自动切换通道这种高敏感场景并不适用:
- 比如在两次采样的间隔 (15s) 中有一个瞬时小尖峰,那么这次小尖峰是观察不到的
- 再比如 QPS、RT、P95、P99 这些值都是估算值,无法和日志、数据库一样做到 100% 准确

Prometheus 不适合的场景
接入和学习成本方面: Prometheus 对于业务研发来讲还是有一定的学习成本的,也不便于后期的维护,而 Redis 对于 Java 后端开发者来说再熟悉不过了,无论是前期的学习成本还是后期的维护成本都比较低。
结合以上几个方面考量,最终决定基于 Redis 自研 “时序数据库” 来满足当前的诉求。
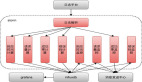
4 架构设计

架构设计
收款和付款时会先通过各自的通道路由,筛选出可用的支付通道列表,获取到通道之后调用网关下单或打款,再由网关来向三方发起请求,请求结束后将三方返回的结果通过 MQ 上报到通道监控系统。
监控系统在监听到消息后,将监控的数据存储到 Redis,再由数据计算模块拉取 Redis 的数据进行筛选过滤后,汇总计算各通道的失败率,最后根据各通道配置的告警规则触发通道异常告警。
Redis 中的数据会定期向 MySQL 备份,以便后续故障分析使用,同时会有离线任务定时清理 Redis 中的数据,避免 Redis 中存储的数据量过大。
同时为了更直观的观察各通道数据指标的变化,将收集到的数据指标上报到了 Prometheus,通过 Grafana 数据看板来观察通道健康度。

通道指标看板
通道自动上下线是比较敏感的操作,严格依赖算法的准确性,所以系统上线初期,我们只上线了手动上下线的能力,需要在收集大量样本后,不断完善算法,提高监控的准确性和灵敏度,再逐步切换至基于监控的通道自动化管理。
5 实现细节
5.1 数据结构
再来看下基于 Redis 的数据存储是如何存储的,虽然没有使用时序数据库,但是在数据结构选择上也是结合了时序数据库的存储思想来设计的,下面就以最热门的 InfluxDB 来对比看下:
InfluxDB | Redis |
tags 标签 | set 记录监控维度 |
time 时间戳 | zset 存储时间戳(秒) |
fields 数据 | hash 存储具体的值 |
- tags 标签:记录监控的维度,相对应的在 Redis 中选用的是 set 来存储,利用 set 去重的特性,刚好可以记录需要监控的指标。
- tims 时间:记录发生的时间,相对应的在 Redis 中选用的是 zset 来存储,在监控时需要根据时间范围进行查找,且要求是按照时间排序的,刚好可以利用 zset 的按照 score 来排序和查找的特性,用于记录监控点位的时间戳,为了避免数据量过大,这里记录的单位是秒,也就一秒一个点位。
- fields 数据:存储具体的监控数据,相对应的在 Redis 中选用的是 hash 来存储,利用 hash 中存储 key、value 的特性,来记录请求结果数据,记录一个点位内(1 秒)的成功与失败的情况,并记录失败的具体原因,key 用来存储请求结果,value 用来记录对应结果 1 秒内发生的次数。
最终 Redis 中存储的结构样例如下:
1.set
存储已统计的维度,具体到商户号
key: routeAlarm:alarmitems
value: 微信-打款-100000111
微信-打款-100000112
微信-打款-100000113
.......
2.zset
存储指定商户号请求的时间戳(秒),同一秒的数据会覆盖存储
key: routeAlarm:alarmitem:timeStore:微信-打款-100000111
score: 1657164225 value: 1657164225
score: 1657164226 value: 1657164226
score: 1657164227 value: 1657164227
.......
3.hash
存储指定商户号1秒内的请求结果, 每秒汇总一份结果
key: routeAlarm:alarmitem:fieldStore:微信-打款-100000111:1657164225
key: success value: 10 (次数)
key: fail value: 5
key: balance_not_enough value: 3
key: thrid_error value: 2
.......5.2 核心算法
为了避免两次监控间的小高峰被忽略,确保不漏报,我们的算法采用的是局部 计数法 加上整体 滑动窗口 的方式来实现的,每秒一个计数的点位,记录成功和失败的数量,监控时会计算整个窗口时间范围内的成功失败数,最终得出每个通道的失败率,比如:窗口时间是1分钟,监控频率 10秒/次。

核心算法
那么监控频率是多少、时间窗口范围如何设定,这都会影响我们最终监控的准确性。如果监控频率过小,就会导致我们的取数样本太少,结果也没有参考意义。如果监控频率过大,两次窗口之间的小高峰就可能存在漏报的情况,这些都是影响告警准确性的因素,这就需要通过对各个通道单据量级如:每天、每小时单量、下单频率等指标进行分析而确定。
5.3 小流量的处理
小流量的通道和时间段要如何处理
- 从通道维度看,小流量的通道如何处理
- 从时间维度看,底峰时间段如何处理
比如转转接入的某一通道,每天总量只有几单,或者凌晨的单量就是很少,针对这种小流量的处理方式是,在监控时间窗口内只有 1 单且失败,则会扩大时间窗口,比如我们正常时间窗口是 1 分钟,那么扩大 1 倍后,时间窗口则变更为 2 分钟,1-10 倍逐级增加,扩大到 10 倍之后如果还是高于预警阀值则会触发告警,此时我们认为这种也是需要关注的异常。
6 最终效果
- 通道异常告警,快速定位问题

通道异常告警
- 合并重复告警项

合并重复告警项
- 通道异常恢复

通道异常恢复
7 未来规划
目前的支付通道自动化管理系统还需要在以下几个方面进行优化和升级:
- 持续优化监控算法,提升告警准确率到99%以上;
- 与监控系统配合,实现通道故障时自动下线的能力;
- 与监控系统配合,实现故障恢复探测及通道自动上线的能力;
关于作者:张丹,转转支付结算技术部研发工程师,主要负责清结算方向的研发工作