













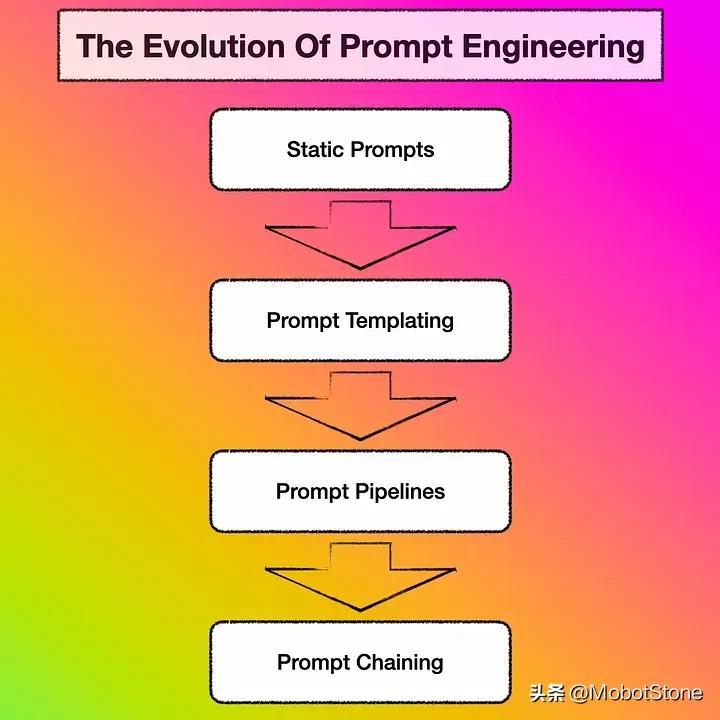
随着功能的增加,提示工程的复杂性将不可避免地增加。在这里,我解释了如何将复杂性引入到提示工程的过程中。
静态prompt
如今,试验prompt和提示工程已司空见惯。通过创建和运行提示的过程,用户可以体验 LLM 的生成能力。
文本生成是大型语言模型的元能力,及时工程是解锁它的关键。
在试验 Prompt Engineering 时收集到的首要原则之一是不能明确要求生成模型做某事。
相反,用户需要了解他们想要实现的目标并模仿该愿景的启动。模仿的过程被称为prompt设计、prompt或铸造。
Prompt Engineering 是向 LLM 提供指导和参考数据的方式。
在提示中引入集合结构可以从 LLM 获得更准确的响应。例如,如下所示,可以对提示进行上下文设计,为 LLM创建上下文参考。
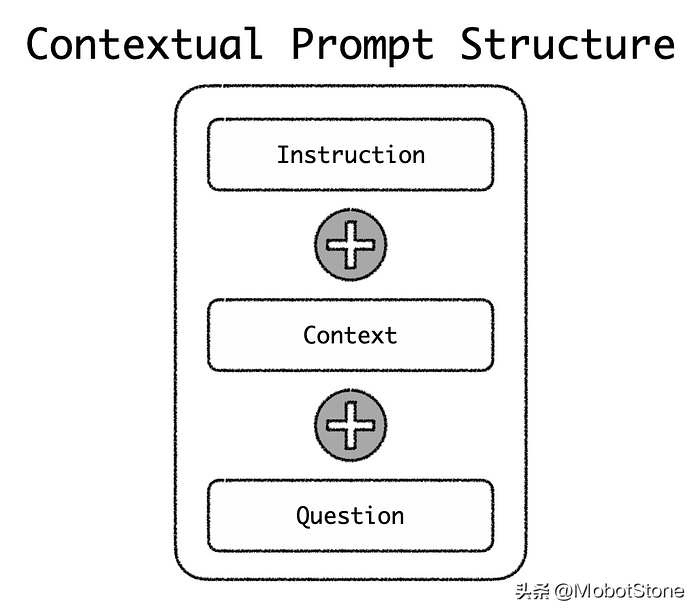
上下文设计的提示通常由三个部分组成,instruction,context和question。
这是上下文提示的实际示例:
在此阶段,提示本质上是静态的**,不构成较大应用程序的一部分。
prompt模板
静态prompt的下一步是prompt模板化。
静态prompt被转换为模板,其中键值被占位符替换。占位符在运行时被替换为应用程序值/变量。
有些人将模板化称为实体注入或prompt注入。
在下面来自DUST 的模板示例中,您可以看到占位符${EXAMPlES:question},${EXAMPlES:answer}并且${QUESTIONS:question}这些占位符在运行时被替换为值。
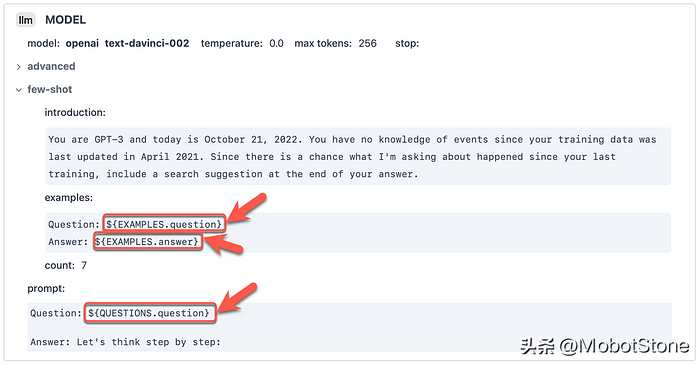
prompt模板允许prompt存储、重新使用、共享和编程。生成prompt可以合并到程序中以进行编程、存储和重复使用。
模板是带有占位符的文本文件,可以在运行时在其中插入变量和表达式。
prompt Pipelines
在prompt Pipelines的情况下,预定义的提示模板填充了来自用户的问题或请求。指导 LLM 的prompt中包含的上下文或参考是从知识库中检索的数据。
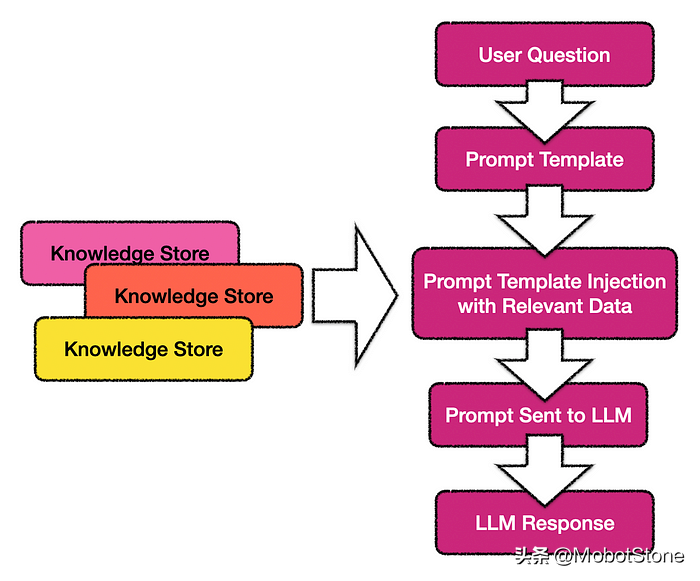
Prompt Pipelines 也可以描述为对提示模板的智能扩展。
因此,预先定义的prompt模板中的变量或占位符被填充(也称为prompt注入)来自用户的问题,以及要从知识库中搜索的知识。
来自知识存储的数据充当要回答的问题的上下文参考。拥有这些可用的信息可以防止 LLM出现错乱。该过程还有助于防止 LLM 使用模型中当时不准确的过时或旧数据。
随后,将组合的提示发送给 LLM,并将 LLM 响应返回给用户。
下面是在文档和问题数据被注入之前的prompt模板示例。
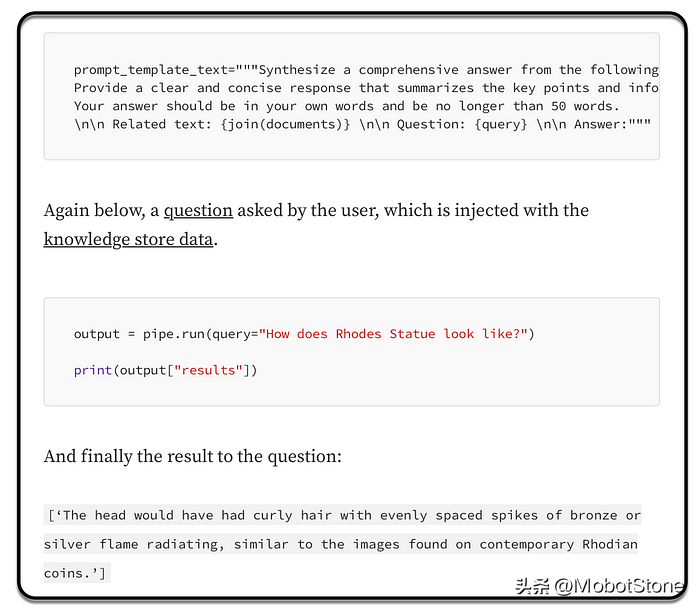
prompt链接
prompt链接是将多个prompt链接或排序以形成更大应用程序的过程。prompt序列可以串联或并联排列。
当prompt按顺序排列时,链中的提示(也称为节点)通常取决于链中前一个节点的输出。在某些情况下,数据处理和决策制定案例是在提示/节点之间实现的。
L LM 用途广泛,具有开放式功能。
在某些情况下,进程需要并行运行,例如,可以在用户与聊天机器人对话时并行启动用户请求。
Prompt Chaining 将主要由用于输入的对话式 UI 组成。输出也将主要是非结构化的对话输出。因此创建了一个数字助理或聊天机器人。提示链接也可用于流程和管道启动并通知用户结果的 RPA 场景。
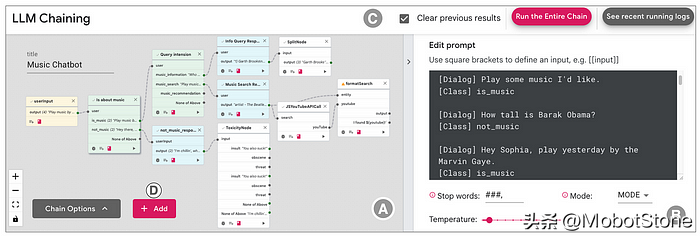
当通过可视化编程 UI链接大型语言模型提示时,功能的最大部分将是促进创作过程的 GUI。
下面是用于prompt工程和prompt链创作的此类 GUI 的图像。此设计源自华盛顿大学和谷歌进行的研究。
综上所述
“最后一英里”一词经常用于生成式 AI 和大型语言模型 (LLM) 的生产实施环境中。确保人工智能的实施确实解决了企业问题并实现了可衡量的商业价值。
生产实施需要面对客户的严格和审查,以及持续扩展、更新和改进的需求。
LLM 的生产实施需求:
- 用于微调 LLM 的精选和结构化数据
- 生成 AI 的监督方法
- 基于 LLM 的应用程序的可扩展和可管理的生态系统





























