概括
积累了一两周,好久没做笔记了,今天,我将展示在之前两周的实战经验:如何使用 Python 和自然语言处理构建知识图谱。
网络图是一种数学结构,用于表示点之间的关系,可通过无向/有向图结构进行可视化展示。它是一种将相关节点映射的数据库形式。
知识库是来自不同来源信息的集中存储库,如维基百科、百度百科等。
知识图谱是一种采用图形数据模型的知识库。简单来说,它是一种特殊类型的网络图,用于展示现实世界实体、事实、概念和事件之间的关系。2012年,谷歌首次使用“知识图谱”这个术语,用于介绍他们的模型。

目前,大多数公司都在建立数据湖,这是一个中央数据库,它可以收集来自不同来源的各种类型的原始数据(包括结构化和非结构化数据)。因此,人们需要工具来理解所有这些不同信息的意义。知识图谱越来越受欢迎,因为它可以简化大型数据集的探索和发现。简单来说,知识图谱将数据和相关元数据连接起来,因此可以用来构建组织信息资产的全面表示。例如,知识图谱可以替代您需要查阅的所有文件,以查找特定的信息。
知识图谱被视为自然语言处理领域的一部分,因为要构建“知识”,需要进行“语义增强”过程。由于没有人想要手动执行此任务,因此我们需要使用机器和自然语言处理算法来完成此任务。
我将解析维基百科并提取一个页面,用作本教程的数据集(下面的链接)。
俄乌战争 - 维基百科 俄乌战争是俄罗斯与俄罗斯支持的分离主义者之间持续的国际冲突,以及...... en.wikipedia.org
特别是将通过:
- 设置:使用维基百科API进行网页爬取以读取包和数据。
- NLP使用SpaCy:对文本进行分句、词性标注、依存句法分析和命名实体识别。
- 提取实体及其关系:使用Textacy库来识别实体并建立它们之间的关系。
- 网络图构建:使用NetworkX库来创建和操作图形结构。
- 时间轴图:使用DateParser库来解析日期信息并生成时间轴图。
设置
首先导入以下库:
Wikipedia-api是一个Python库,可轻松解析Wikipedia页面。我们将使用这个库来提取所需的页面,但会排除页面底部的所有“注释”和“参考文献”内容。

简单地写出页面的名称:

通过从文本中识别和提取subjects-actions-objects来绘制历史事件的关系图谱(因此动词是关系)。
自然语言处理
要构建知识图谱,首先需要识别实体及其关系。因此,需要使用自然语言处理技术处理文本数据集。
目前,最常用于此类任务的库是SpaCy,它是一种开源软件,用于高级自然语言处理,利用Cython(C+Python)进行加速。SpaCy使用预训练的语言模型对文本进行标记化,并将其转换为“文档”对象,该对象包含模型预测的所有注释。
NLP模型的第一个输出是句子分割(中文有自己的分词规则):即确定句子的起始和结束位置的问题。通常,它是通过基于标点符号对段落进行分割来完成的。现在我们来看看SpaCy将文本分成了多少个句子:

现在,对于每个句子,我们将提取实体及其关系。为了做到这一点,首先需要了解词性标注(POS):即用适当的语法标签标记句子中的每个单词的过程。以下是可能标记的完整列表(截至今日):
- ADJ: 形容词,例如big,old,green,incomprehensible,first
- ADP: 介词,例如in,to,during
- ADV: 副词,例如very,tomorrow,down,where,there
- AUX: 助动词,例如is,has(done),will(do),should(do)
- CONJ: 连词,例如and,or,but
- CCONJ: 并列连词,例如and,or,but
- DET: 限定词,例如a,an,the
- INTJ: 感叹词,例如psst,ouch,bravo,hello
- NOUN: 名词,例如girl,cat,tree,air,beauty
- NUM: 数词,例如1,2017,one,seventy-seven,IV,MMXIV
- PART: 助词,例如's,not
- PRON: 代词,例如I,you,he,she,myself,themselves,somebody
- PROPN: 专有名词,例如Mary,John,London,NATO,HBO
- PUNCT: 标点符号,例如.,(,),?
- SCONJ: 从属连词,例如if,while,that
- SYM: 符号,例如$,%,§,©,+,-,×,÷,=,:),表情符号
- VERB: 动词,例如run,runs,running,eat,ate,eating
- X: 其他,例如sfpksdpsxmsa
- SPACE: 空格,例如
仅有词性标注是不够的,模型还会尝试理解单词对之间的关系。这个任务称为依存句法分析(Dependency Parsing,DEP)。以下是可能的标签完整列表(截至今日)。
- ACL:作为名词从句的修饰语
- ACOMP:形容词补语
- ADVCL:状语从句修饰语
- ADVMOD:状语修饰语
- AGENT:主语中的动作执行者
- AMOD:形容词修饰语
- APPOS:同位语
- ATTR:主谓结构中的谓语部分
- AUX:助动词
- AUXPASS:被动语态中的助动词
- CASE:格标记
- CC:并列连词
- CCOMP:从句补足语
- COMPOUND:复合修饰语
- CONJ:连接词
- CSUBJ:主语从句
- CSUBJPASS:被动语态中的主语从句
- DATIVE:与双宾语动词相关的间接宾语
- DEP:未分类的依赖
- DET:限定词
- DOBJ:直接宾语
- EXPL:人称代词
- INTJ:感叹词
- MARK:标记
- META:元素修饰语
- NEG:否定修饰语
- NOUNMOD:名词修饰语
- NPMOD:名词短语修饰语
- NSUBJ:名词从句主语
- NSUBJPASS:被动语态中的名词从句主语
- NUMMOD:数字修饰语
- OPRD:宾语补足语
- PARATAXIS:并列结构
- PCOMP:介词的补足语
- POBJ:介词宾语
- POSS:所有格修饰语
- PRECONJ:前置连词
- PREDET:前置限定词
- PREP:介词修饰语
- PRT:小品词
- PUNCT:标点符号
- QUANTMOD:量词修饰语
- RELCL:关系从句修饰语
- ROOT:句子主干
- XCOMP:开放性从句补足语
举个例子来理解POS标记和DEP解析:

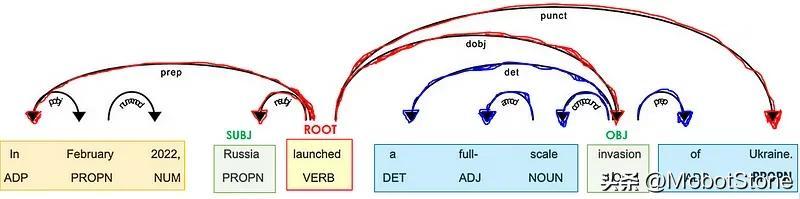
检查 NLP 模型预测的 POS 和 DEP 标签:

SpaCy提供了一个图形工具来可视化这些注释:
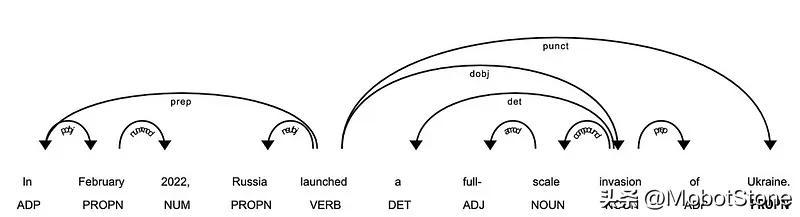
最重要的标记是动词 ( POS=VERB ),因为它是句子中含义的词根 ( DEP=ROOT )。
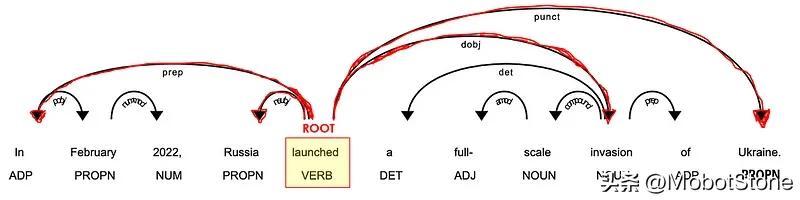
助词,如副词和副词 ( POS=ADV/ADP ),通常作为修饰语 ( *DEP=mod ) 与动词相关联,因为它们可以修饰动词的含义。例如,“ travel to ”和“ travel from ”具有不同的含义,即使词根相同(“ travel ”)。
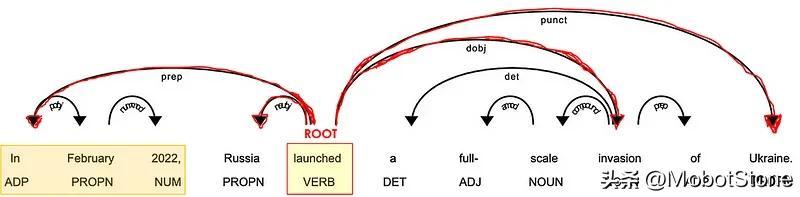
在与动词相连的单词中,必须有一些名词(POS=PROPN/NOUN)作为句子的主语和宾语( *DEP=nsubj/obj )。

名词通常位于形容词 ( POS=ADJ ) 附近,作为其含义的修饰语 ( DEP=amod )。例如,在“好人”和“坏人”中,形容词赋予名词“人”相反的含义。
SpaCy执行的另一个很酷的任务是命名实体识别(NER)。命名实体是“真实世界中的对象”(例如人、国家、产品、日期),模型可以在文档中识别各种类型的命名实体。以下是可能的所有标签的完整列表(截至今日):
- 人名: 包括虚构人物。
- 国家、宗教或政治团体:民族、宗教或政治团体。
- 地点:建筑、机场、高速公路、桥梁等。
- 公司、机构等:公司、机构等。
- 地理位置:国家、城市、州。
- 地点:非国家地理位置,山脉、水域等。
- 产品:物体、车辆、食品等(不包括服务)。
- 事件:命名飓风、战斗、战争、体育赛事等。
- 艺术作品:书籍、歌曲等的标题。
- 法律:成为法律的指定文件。
- 语言:任何命名的语言。
- 日期:绝对或相对日期或期间。
- 时间:小于一天的时间。
- 百分比:百分比,包括“%”。
- 货币:货币价值,包括单位。
- 数量:衡量重量或距离等。
- 序数: “第一”,“第二”等。
- 基数:不属于其他类型的数字。

或者使用SpaCy图形工具更好:

这对于我们想要向知识图谱添加多个属性的情况非常有用。
接下来,使用NLP模型预测的标签,我们可以提取实体及其关系。
实体和关系抽取
这个想法很简单,但实现起来可能会有些棘手。对于每个句子,我们将提取主语和宾语以及它们的修饰语、复合词和它们之间的标点符号。
可以通过两种方式完成:
- 手动方式:可以从基准代码开始,该代码可能必须稍作修改并针对您特定的数据集/用例进行调整。
让我们在这个数据集上试试看,看看通常的例子:



第二种方法是使用Textacy,这是一个基于SpaCy构建的库,用于扩展其核心功能。这种方法更加用户友好,通常也更准确。

让我们也使用 NER 标签(即日期)提取属性:

已经提取了“知识”,接下来可以构建图表了。
网络图
Python标准库中用于创建和操作图网络的是NetworkX。我们可以从整个数据集开始创建图形,但如果节点太多,可视化将变得混乱:

知识图谱可以让我们从大局的角度看到所有事物的相关性,但是如果直接看整张图就没有什么用处。因此,最好根据我们所需的信息应用一些过滤器。对于这个例子,我将只选择涉及最常见实体的部分(基本上是最连接的节点):

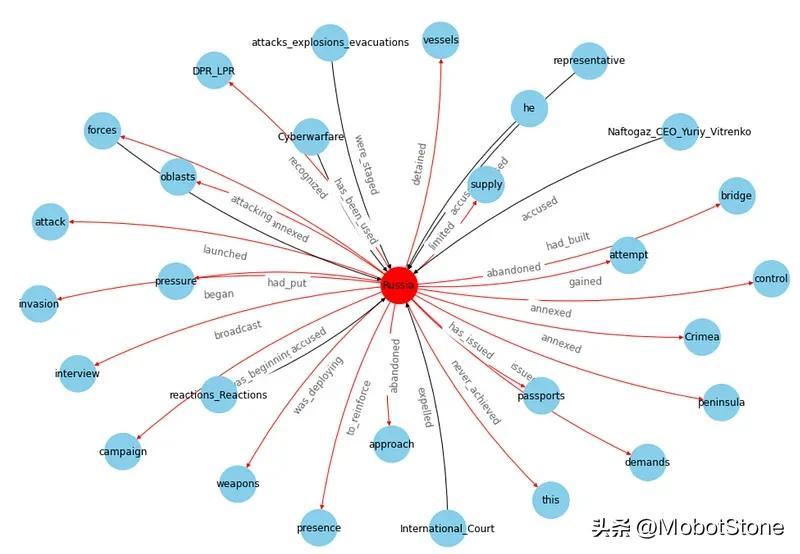
上面的效果已经不错了。如果想让它成为 3D 的话,可以使用以下代码:
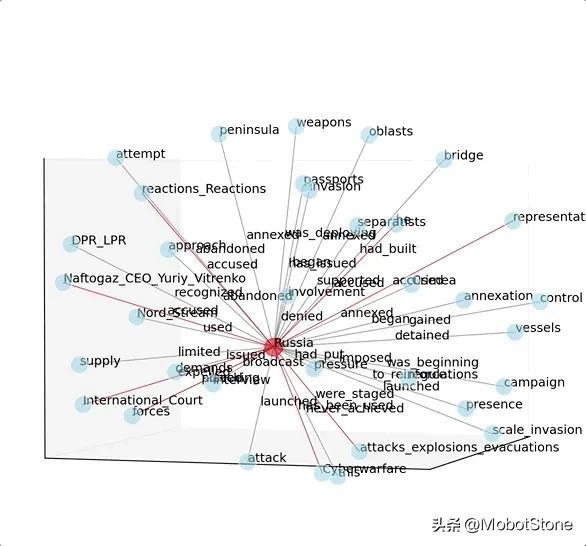
需要注意一点,图形网络可能很有用且漂亮,但它不是本教程的重点。知识图谱最重要的部分是“知识”(文本处理),然后可以在数据帧、图形或其他图表上显示结果。例如,我可以使用NER识别的日期来构建时间轴图。
时间轴图
首先,需要将被识别为“日期”的字符串转换为日期时间格式。DateParser库可以解析几乎在网页上常见的任何字符串格式中的日期。
将它应用于属性的数据框:

将把它与实体关系的主要数据框结合起来:

最后,我可以绘制时间轴(绘制完整的图表可能不会用到):

过滤特定时间:

提取“知识”后,可以根据自己喜欢的风格重新绘制它。
结论
本文是关于**如何使用 Python 构建知识图谱的教程。**从维基百科解析的数据使用了几种 NLP 技术来提取“知识”(即实体和关系)并将其存储在网络图对象中。
现利用 NLP 和知识图来映射来自多个来源的相关数据并找到对业务有用的见解。试想一下,将这种模型应用于与单个实体(即 Apple Inc)相关的所有文档(即财务报告、新闻、推文)可以提取多少价值。您可以快速了解与该实体直接相关的所有事实、人员和公司。然后,通过扩展网络,即使信息不直接连接到起始实体 (A — > B — > C)。