












Grad-CAM (Gradient-weighted Class Activation Mapping) 是一种可视化深度神经网络中哪些部分对于预测结果贡献最大的技术。它能够定位到特定的图像区域,从而使得神经网络的决策过程更加可解释和可视化。
Grad-CAM 的基本思想是,在神经网络中,最后一个卷积层的输出特征图对于分类结果的影响最大,因此我们可以通过对最后一个卷积层的梯度进行全局平均池化来计算每个通道的权重。这些权重可以用来加权特征图,生成一个 Class Activation Map (CAM),其中每个像素都代表了该像素区域对于分类结果的重要性。
相比于传统的 CAM 方法,Grad-CAM 能够处理任意种类的神经网络,因为它不需要修改网络结构或使用特定的层结构。此外,Grad-CAM 还可以用于对特征的可视化,以及对网络中的一些特定层或单元进行分析。
在Pytorch中,我们可以使用钩子 (hook) 技术,在网络中注册前向钩子和反向钩子。前向钩子用于记录目标层的输出特征图,反向钩子用于记录目标层的梯度。在本篇文章中,我们将详细介绍如何在Pytorch中实现Grad-CAM。

加载并查看预训练的模型
为了演示Grad-CAM的实现,我将使用来自Kaggle的胸部x射线数据集和我制作的一个预训练分类器,该分类器能够将x射线分类为是否患有肺炎。
首先我们看看这个模型的架构。就像前面提到的,我们需要识别最后一个卷积层,特别是它的激活函数。这一层表示模型学习到的最复杂的特征,它最有能力帮助我们理解模型的行为,下面是我们这个演示模型的代码:
模型3通道接收256x256的图片。它期望输入为[batch size, 3,256,256]。每个ResNet块以一个ReLU激活函数结束。对于我们的目标,我们需要选择最后一个ResNet块。
在Pytorch中,我们可以很容易地使用模型的属性进行选择。
Pytorch的钩子函数
Pytorch有许多钩子函数,这些函数可以处理在向前或后向传播期间流经模型的信息。我们可以使用它来检查中间梯度值,更改特定层的输出。
在这里,我们这里将关注两个方法:
该方法在模块上注册了一个后向传播的钩子,当调用backward()方法时,钩子函数将会运行。后向钩子函数接收模块本身的输入、相对于层的输入的梯度和相对于层的输出的梯度
它返回一个torch.utils.hooks.RemovableHandle,可以使用这个返回值来删除钩子。我们在后面会讨论这个问题。
这与前一个非常相似,它在前向传播中后运行,这个函数的参数略有不同。它可以让你访问层的输出:
它的返回也是torch.utils.hooks.RemovableHandle
向模型添加钩子函数
为了计算Grad-CAM,我们需要定义后向和前向钩子函数。这里的目标是关于最后一个卷积层的输出的梯度,需要它的激活,即层的激活函数的输出。钩子函数会在推理和向后传播期间为我们提取这些值。
在定义了钩子函数和存储激活和梯度的变量之后,就可以在感兴趣的层中注册钩子,注册的代码如下:
检索需要的梯度和激活
现在已经为模型设置了钩子函数,让我们加载一个图像,计算gradcam。
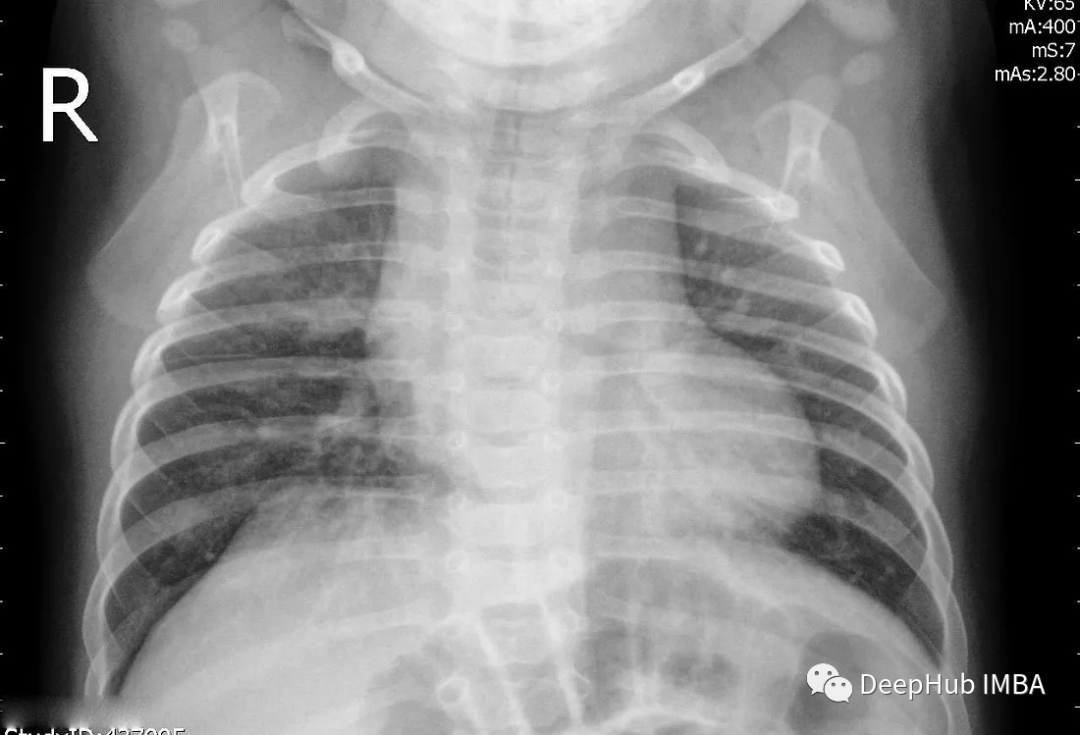
为了进行推理,我们还需要对其进行预处理:
现在就可以进行前向传播了:
钩子函数的返回如下:
得到了梯度和激活变量后就可以生成热图:
计算Grad-CAM
为了计算Grad-CAM,我们将原始论文公式进行一些简单的修改:
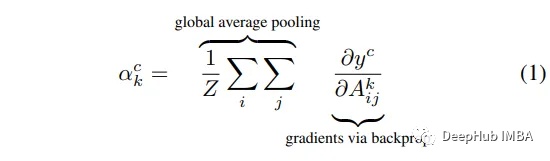
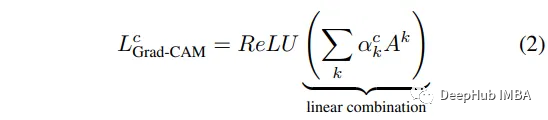
结果如下:

得到的激活包含1024个特征映射,这些特征映射捕获输入图像的不同方面,每个方面的空间分辨率为8x8。通过钩子获得的梯度表示每个特征映射对最终预测的重要性。通过计算梯度和激活的元素积可以获得突出显示图像最相关部分的特征映射的加权和。通过计算加权特征图的全局平均值,可以得到一个单一的热图,该热图表明图像中对模型预测最重要的区域。这就是Grad-CAM,它提供了模型决策过程的可视化解释,可以帮助我们解释和调试模型的行为。
但是这个图能代表什么呢?我们将他与图片进行整合就能更加清晰的可视化了。
结合原始图像和热图
下面的代码将原始图像和我们生成的热图进行整合显示:

这样看是不是就理解多了。由于它是一个正常的x射线结果,所以并没有什么需要特殊说明的。

再看这个例子,这个结果中被标注的是肺炎。Grad-CAM能准确显示出医生为确定是否患有肺炎而必须检查的胸部x光片区域。也就是说我们的模型的确学到了一些东西(红色区域再肺部附近)
删除钩子
要从模型中删除钩子,只需要在返回句柄中调用remove()方法。
总结
这篇文章可以帮助你理清Grad-CAM 是如何工作的,以及如何用Pytorch实现它。因为Pytorch包含了强大的钩子函数,所以我们可以在任何模型中使用本文的代码。













