4月20日消息,过去四个月,人工智能聊天机器人变得越来越受欢迎,它们能够完成各种任务,比如写复杂的学术论文和进行紧张的对话,能力很令人惊叹。
聊天机器人并不像人类那样思考,它们甚至不知道自己在说什么。它们之所以能模仿人类的语言,是因为驱动它们的人工智能已经吸收了大量的文本,其中大部分内容是从互联网上抓取的。
这些文本是人工智能在构建过程中获取世界信息的主要来源,它们会对人工智能的响应方式产生深远影响。如果人工智能在司法考试中取得了优异成绩,那可能是因为它的训练数据中包含了数以千计的LSAT(Law School Admission Test,美国法学院入学申请考试)资料。
科技公司对他们向人工智能提供了哪些信息始终保密。因此,《华盛顿邮报》开始分析其中一个重要数据集,彻底揭示了用于训练AI的专有、个人和常常具有攻击性的网站类型。
为了探究人工智能训练数据的内部构成,《华盛顿邮报》与艾伦人工智能研究所的研究人员合作,对谷歌的C4数据集进行了分析。这个数据集是一个包含1500多万个网站的海量快照,这些网站内容被用来训练许多备受关注的英语人工智能,例如谷歌的T5和Facebook的LLaMA。而OpenAI没有透露他们使用了什么样的数据集来训练支持聊天机器人ChatGPT的模型。
在这项调查中,研究人员使用网络分析公司Similarweb的数据对网站进行了分类。其中大约三分之一的网站无法进行分类而被排除,主要是因为它们已经不再存在于互联网上。接着,研究人员根据数据集中每个网站出现的“token”数量,对剩下的1000万个网站进行了排名。token是处理信息的小段文本,通常是一个单词或短语,用于训练AI模型。
从维基百科到WoWhead
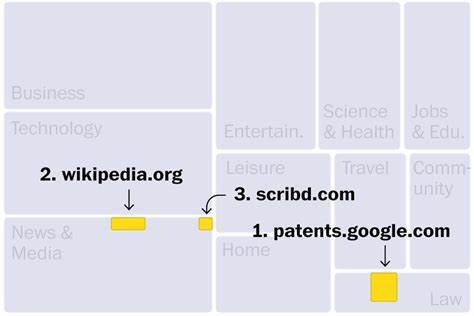
C4数据集的网站主要来自新闻、娱乐、软件开发、医疗和内容创作等行业。这可以解释为什么这些领域可能受到新一波人工智能的威胁。排名前三的网站分别是:第一名是谷歌专利搜索,它包含世界各地发布的专利文本;第二名是维基百科;第三名是只接受付费订阅的数字图书馆Scribd。此外,排名靠前的其他网站还有盗版电子书市场Library(第190位),这个网站因非法行为被美国司法部查封。此外,数据集中还存在至少27个被美国政府认定为盗版和假冒产品市场的网站。
还有一些顶级网站也出现在其中,例如《魔兽世界》玩家论坛wowhead(第181位),以及阿里安娜·赫芬顿(Arianna Huffington)创立的用于帮助缓解职业倦怠的网站thriveglobal(第175位)。此外,还有至少10个出售垃圾箱的网站,包括dumpsteroid(第183位),但它似乎已经无法访问。
虽然大部分网站都是安全的,但有些网站存在严重的隐私问题。例如,有两个排名进入前100位的网站,都私下承载了州选民登记数据库的副本。虽然选民数据是公开的,但这些模型可能会以未知的方式使用这些个人信息。
工商业网站占据了最大的类别(占分类token的16%)。排名第一的是提供投资建议的The Motley Fool(第13位)。其次是允许用户为创意项目进行众筹的Kickstarter网站(第25位)。而排名较后的Patreon位列第2398,该网站帮助创作者从订阅者那里收取每月费用以获得独家内容。
然而,Kickstarter和Patreon可能会让人工智能获取艺术家的想法和营销文案,人们担忧AI可能会在向用户提供建议时复制这些作品。目前,艺术家的作品被包括在人工智能培训数据中时,他们不会得到任何补偿,他们已经向文本转图像生成器Stable Diffusion、MidJourney和DeviantArt提出了侵权索赔。
根据这次《华盛顿邮报》的分析,更多的法律挑战可能即将到来:C4数据集中有超过2亿次出现版权符号(表示注册为知识产权的作品)。
技术网站是第二大类别,占分类token的15%。这包括许多平台,它们帮助人们建立网站,比如谷歌协作平台(第85位),它的页面涵盖了从英格兰雷丁柔道俱乐部到新泽西州幼儿园的各种内容。
C4数据集还包含了50多万个个人博客,占分类内容的3.8%。发布平台Medium排名第46位,是第五大科技网站,在其域名下拥有数万个博客。此外,还有在WordPress、Tumblr、Blogpot和Live Journal等平台上撰写的博客。
这些博客形式多样,从职业到个人都有,比如一篇名为“Grumpy Rumblings”的博客,由两位匿名的学者共同撰写,其中一位最近写到了他们的伴侣失业是如何影响了夫妻的税收。此外,C4数据集中还有一些专注于真人角色扮演游戏的顶级博客。
社交网络如Facebook和Twitter等(它们被视为现代网络的核心)的内容被禁止抓取,这意味着用于训练人工智能的大多数数据集都无法访问它们。Facebook和谷歌等科技巨头坐拥海量对话数据,但他们还不清楚如何使用个人用户信息来训练内部使用或作为产品销售的人工智能模型。
新闻和媒体网站是所有类别中排名第三,而前十位网站中有半数是新闻媒体:《纽约时报》网站排名第四,《洛杉矶时报》网站排名第六,《卫报》网站排名第七,《福布斯》网站排在第八位,《赫芬顿邮报》网站排名第九,《华盛顿邮报》网站排名第11位。与艺术家和创作者一样,多家新闻机构也批评科技公司在未经授权或提供补偿的情况下使用他们的内容。
与此同时,《华盛顿邮报》还发现有几家媒体在NewsGuard的独立可信度评级中排位较低:比如俄罗斯RT(第65位)、极右翼新闻网站breitbart(第159位)以及与白人至上主义有关的反移民网站vdare(第993位)。
聊天机器人已经被证明可以分享错误信息。不可信的训练数据可能导致它们传播偏见、宣传错误信息,而用户却无法追踪到它们的原始来源。
社区网站约占分类内容的5%,主要是宗教网站。
过滤器漏网之鱼有哪些?
像大多数公司一样,谷歌在将数据提供给人工智能之前,会对数据进行过滤和筛查。除了去除无意义和重复的文字外,该公司还使用了开源的“不良词汇列表”,其中包括402个英文术语和一个表情符号。公司通常使用高质量的数据集来微调模型,从而屏蔽用户不想看到的内容。
虽然这类列表旨在限制模型在接受培训时受到种族诽谤和不良内容的影响,但很多东西都通过了过滤器的筛查。《华盛顿邮报》发现了数百个色情网站和超过7.2万个“纳粹”例子,它们都在禁用词汇列表中。
与此同时,《华盛顿邮报》发现,这些过滤器未能删除某些令人不安的内容,包括白人至上主义网站、反跨性别网站以及以组织针对个人骚扰活动而闻名的匿名留言板4chan。研究中还发现了宣传阴谋论的网站。
你的网站有没有用于训练AI?
网络抓取听上去可能像是对整个互联网进行复制,但实际上它只是收集快照,即对特定时刻的网页样本抓取内容。C4数据集最初是由非营利组织CommonCrawl创建的,于2019年4月进行网络内容抓取,是人工智能模型训练的热门资源。CommonCrawl表示,该组织试图优先考虑最重要和声誉最好的网站,但没有试图避免授权或版权保护的内容。
《华盛顿邮报》认为,将数据的完整内容呈现在人工智能模型中至关重要,这些模型有望管理人们现代生活的许多方面。然而,这个数据集中的许多网站包含高度攻击性语言,即使模型训练时尽量掩盖这些词语,令人反感的内容仍然可能会存在。
专家表示,尽管C4数据集很庞大,但大型语言模型可能会使用更大的数据集。例如,OpenAI在2020年发布了GPT-3训练数据,其数据量是C4中网络抓取数据量的40倍。GPT-3的培训数据包括所有英文维基百科、大型科技公司经常使用的、未出版作家的免费小说集以及Reddit用户高度评价的链接文本汇编。
专家表示,许多公司甚至没有记录培训数据的内容(甚至是内部数据),因为担心发现有关可识别身份的个人信息、受版权保护的材料和其他未经同意被窃取的数据。随着公司强调解释聊天机器人如何做出决策面临的挑战,这是高管们需要给出透明答案的领域。