作者 | 蔡柱梁
审校 | 重楼
目录 ES是什么 倒排索引 使用ES必须知道的基本概念 了解常用的DSL 1 ES是什么 Elasticsearch 是一个分布式的 RESTful 搜索和分析引擎,可用来集中存储您的数据,以便您对形形色色、规模不一的数据进行搜索、索引和分析。
上面是官网-API文档 对的定位描述。ES 是一个分布式的搜索引擎,数据存储形式与我们常用的 MySQL 的存储形式 — rows 不同,ES 会将数据以 JSON 结构存储到一个文档。一个文档写入 ES 后,我们可以在 1 秒左右查询到它,因此我们称 ES 在分布式中数据查询是准实时的。
提问:那么这种将一行行数据变成 我们传统的关系型数据库一般的存储形式是数据结构不固定,长度不固定。这时如果用关系型数据库做存储,那么我们表设计上,只能用一个
为了可以适应高并发,又能快速检索、分析数据的搜索分析引擎,像倒排索引实现可以通过词条快速查找文档的,而倒排索引的实现与这种文档存储数据的方式密不可分。
ES 的适用场景所具有的特点:
2 倒排索引 倒排索引是文档检索系统中最常用的数据结构。
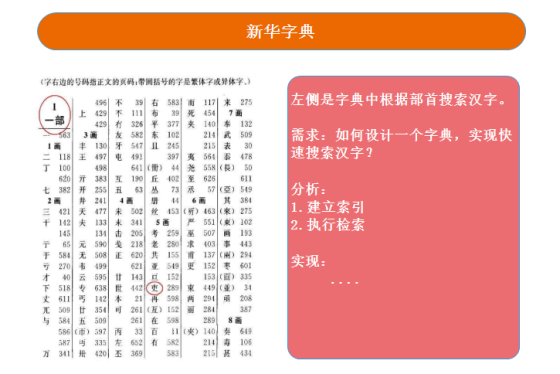
说到帮助搜索引擎检索数据的数据结构,我们最熟悉的应该就是倒排索引了。过去很多人喜欢用字典来举例,因为它的原理和我们使用中文字典查找汉字是相似的。
ES 会在我们保存一份文档的时候,将文档根据指定分词器进行分词,然后维护关键词和文档的关系——倒排索引。后面我们通过一些词条进行检索的时候,就可以通过这个索引找到对应相关的文档。
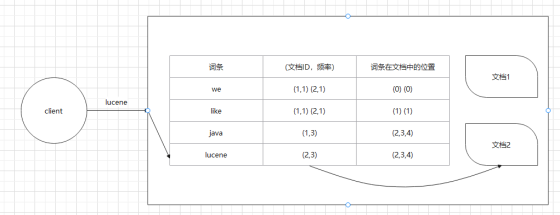
2.1 例子 下面举个例子。
插入两份文档,内容如下:
we like java java java we like lucene lucene lucene 建立倒排索引大体流程如下:
首先对所有数据的内容进行拆分,拆分成唯一的一个个词语(词条) 然后建立词条和对应文档的对应关系,具体如下: 词条
(文档ID,频率)
词条在文档中的位置
we
(1,1) (2,1)
(0) (0)
like
(1,1) (2,1)
(1) (1)
java
(1,3)
(2,3,4)
lucene
(2,3)
(2,3,4)
注意 :这里用表格来展示是为了方便理解,但是倒排索引其实是树结构。
那这时我检索词条:
3 使用ES必须知道的基本概念 这里的概念是我们在使用过程中绝对无法绕开的概念,所以我们需要知道,否则无法和同事交流,哪怕仅仅是使用级别。
3.1 document(文档) 在 ES 中,一份文档相当于 MySQL 中的一行记录,数据以 JSON 格式保存。文档被更新时,版本号会被增加。
3.2 Index(索引) 存储文档的地方,类似 MySQL 中的表。
3.3 Mapping(映射) 映射是定义一个文件和它所包含的字段如何被存储和索引的过程(这是官方定义 )。
文档里面有许多字段,这些字段有自己的类型,采用什么分词器等等,我们可以通过。
3.4 type(类型) 这是比较老旧版本会用到的定义,在 ES5 的时代,它可以对 Index 做更精细地划分,那个时代的 Index 更像 MySQL 的实例,而 type
类似 MySQL 的 table。
ES 5.x 中一个index可以有多种type。
ES 6.x 中一个index只能有一种type。
ES 7.x 以后,将逐步移除type这个概念,现在的操作已经不再使用,默认_doc。
4 了解常用的DSL 在 MySQL 中,我们经常使用 SQL 通过客户端操作 MySQL,而 DSL 正是我们通过客户端发送给 ES 的操作指令。
下面只写一些现在我们常常接触的简单的 DSL,更多的请看 官网。
4.1 Index 官网API:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html
4.1.1 创建索引 可以先建索引,再设置 mapping,也可以直接一次完成。
一次建好
复制 PUT goods {
"mappings" : {
"properties" : {
"brand" : {
"type" : "keyword"
},
"category" : {
"type" : "keyword"
},
"num" : {
"type" : "integer"
},
"price" : {
"type" : "double"
},
"title" : {
"type" : "text" ,
"analyzer" : "ik_smart"
},
"id" : {
"type" : "long"
}
}
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 4.1.2 查询 index 信息 GET index_name
4.1.3 删除 index DELETE index_name
4.1.4 关闭 index POST index_name/_close
当索引进入关闭状态,是不能操作文档的。
4.1.5 打开 index POST index_name/_open
4.1.6 Aliases(别名) & Reindex 实际工作中,有很多情况可能都会需要重建 index,同时将旧的数据迁移到新 index 上,并且期望这个过程可以零停机,那么这时我们就可以用到
aliases 和 reindex 了。
事实上,我们程序访问 index,很少是访问真正的 indexName,一般我们会对 index
建别名,程序访问的是别名。因为如果使用别名,那么此别名背后的索引需要进行更换的时候对程序可以做到无感知。
下面是一个需要添加分词器而导致需要重建 index 和数据迁移的场景(这里只是举个简单场景,方便感受这些命令如何使用而已)。
1)先建立了一个 person,具体如下:
复制 PUT person
{
"mappings" : {
"properties" : {
"address" : {
"type" : "text"
},
"age" : {
"type" : "integer"
},
"name" : {
"type" : "keyword"
}
}
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 2)后端程序访问是用别名
复制 POST _aliases
{
"actions" : [
{
"add" : {
"index" : "person" ,
"alias" : "person_index"
}
}
]
}3)添加了一些数据
复制 PUT person / _doc / 1
{
"name" : "test1" ,
"age" : 18 ,
"address" : "test address"
}4)添加分词器,更改 mapping 设置
复制 PUT person2
{
"mappings" : {
"properties" : {
"address" : {
"type" : "text" ,
"analyzer" : "ik_smart"
},
"age" : {
"type" : "integer"
},
"name" : {
"type" : "keyword"
}
}
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 5)别名操作(支持多个操作,并具有原子性)
复制 POST / _aliases
{
"actions" : [
# 添加别名
{ "add" : { "index" : "person2" , "alias" : "person_index" } }
]
}这时我们后端程序只能对 person_index 进行读操作,无法进行写操作。
6)将 person 中的数据导入到 person2 中(如果是不同进程,支持远程访问)
复制 POST _reindex
{
"source" : {
"index" : "person"
},
"dest" : {
"index" : "person2"
}
}7)去掉 person
复制 POST / _aliases
{
"actions" : [
# 将 person 从别名 person_index 中移除
{ "remove" : { "index" : "person" , "alias" : "person_index" } }
]
}这时后端程序对 person_index 的读写操作均恢复正常。
更多信息可以查阅官网:reindex aliases
4.2 设置 Mapping 添加 index。
复制 PUT person
{
"settings" : {
"number_of_shards" : 1 ,
"number_of_replicas" : 1
}
}已经建好索引 person,但是没有设置 mapping,现在设置。
复制 PUT person / _mapping
{
"properties" : {
"name" : {
"type" : "keyword"
},
"age" : {
"type" : "integer"
},
"address" :{
"type" : "text" ,
"analyzer" : "ik_max_word"
}
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. index 确定后,不能修改已有字段,只能添加,以下增加一个 test 字段作为例子。
复制 PUT person / _mapping
{
"properties" : {
"test" : {
"type" : "text"
}
}
}查询 mapping 信息 4.3 使用频率较高的查询 这里只写一些比较常接触的语句,不过像 wildcard 这种,也有很多公司是禁止使用的,所以用的时候一定要了解公司规范要求。
先设置一个商品 index,具体如下:
复制 PUT goods
{
"mappings" : {
"properties" : {
"brand" : {
"type" : "keyword"
},
"category" : {
"type" : "keyword"
},
"num" : {
"type" : "integer"
},
"price" : {
"type" : "double"
},
"title" : {
"type" : "text" ,
"analyzer" : "ik_smart"
},
"id" : {
"type" : "long"
}
}
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 字段说明:
title:商品标题 price:商品价格 num:商品库存 category:商品类别 brand:品牌名称 4.3.1 分页与排序 复制 # GET 索引库名称 / _search,默认展示10条数据
GET goods / _doc / _search
{
"query" : {
"match_all" : {}
},
"sort" : [
{
"price" : {
"order" : "desc" # 根据价格降序排序
}
}
],
"from" : 0 , # 从哪一条开始
"size" : 20 # 显示多少条
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 4.3.1.1 深度翻页 ES 深度分页存在的问题:
性能问题 深度分页会导致搜索引擎遍历大量的数据,因此会对性能产生负面影响。尤其是在数据量庞大的情况下,可能会导致搜索请求变得非常慢。 排序问题 这是由于不同分片上的数据排序不一致所导致的(每个分片需要将自己的处理结果给到协调节点,再由协调节点来计算出最后的结果)。 索引更新问题 如果在进行深度分页时,索引被更新了,那么可能会导致部分数据被遗漏或重复显示(为了避免这个问题,可以使用游标或滚动搜索等机制来遍历数据)。 内存问题 在进行深度分页时,Elasticsearch 需要将所有的搜索结果都存储在内存中。如果结果集非常大,那么会占用大量的内存,甚至可能导致内存溢出(为了避免这个问题,可以使用游标或滚动搜索等机制来逐步处理数据)。 在 Elasticsearch 7.0 之前,我们是采用 scroll 来解决深度分页的,但是到了 Elasticsearch 7.0 就开始不再推荐采用
scroll 了,推荐采用 search_after。
4.3.1.1.1 scroll 详细请看官方文档 。
以下例子来自于官网
1)先查询并生成快照
scroll=1m 是保留1分钟快照的意思,即是符合当前查询条件的数据的结果集合保留快照1分钟
复制 POST / index_name / _search ? scroll = 1 m
{
"size" : 100 ,
"query" : {
"match" : {
"message" : "foo"
}
}
}假设返回的 scroll_id 是
DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==
2)那么,我们就可以使用这个 ID 进行滚动翻页了
复制 POST / _search / scroll
{
"scroll" : "1m" , # 快照保持1分钟,重新计时
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}3)查询完后,记得删除游标
复制 DELETE / _search / scroll
{
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}这里详细说下游标的工作方式:
当第一次发起 scroll 请求时,ES 会创建一个包含搜索结果的快照,并返回一个唯一的滚动 ID。在接下来的每个 scroll
请求中,都需要带上这个滚动 ID,表示要获取与该搜索上下文匹配的下一批结果。因为每个 scroll
请求都使用了相同的搜索上下文,所以每个请求返回的结果都是相同的,只是可能包含不同的文档。如果 scroll 请求返回的结果集合大小不足以填满请求的大小限制,则
ES 会在后台继续搜索,并将结果添加到当前结果集中,直到结果集合大小达到请求的大小限制或搜索完成为止。
由于 scroll 机制的实现方式,每次请求返回的结果可以是任意大小,可以避免一次性读取所有结果可能导致的内存问题。同时,由于滚动 ID
只在指定的时间段内有效,所以可以在不消耗过多内存的情况下,分批次处理大量数据。但是,需要注意的是,如果时间段设置得过短,可能会导致滚动 ID
过期,需要重新发起搜索请求。
4.3.1.1.2 search_after 详细请看官网 。
以下例子来自于官网
1)先查询 复制 GET twitter / _search
{
"query" : {
"match" : {
"title" : "elasticsearch"
}
},
"sort" : [
{"date" : "asc" },
{"tie_breaker_id" : "asc" }
]
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 假设响应如下:
复制 {
"took" : 17 ,
"timed_out" : false ,
"_shards" : ... ,
"hits" : {
"total" : ... ,
"max_score" : null ,
"hits" : [
...
{
"_index" : "twitter" ,
"_id" : "654322" ,
"_score" : null ,
"_source" : ... ,
"sort" : [
1463538855 ,
"654322"
]
},
{
"_index" : "twitter" ,
"_id" : "654323" ,
"_score" : null ,
"_source" : ... ,
"sort" : [
1463538857 ,
"654323"
]
}
]
}
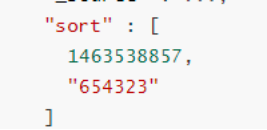
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 2)接着,使用上面响应结果中最后一个文档的排序键
作为参数传递到下一次查询中(这里其实就是对应了查询示例中的两个排序字段 date 和 tie_breaker_id)
复制 GET twitter / _search
{
"query" : {
"match" : {
"title" : "elasticsearch"
}
},
"search_after" : [1463538857 , "654323" ],
"sort" : [
{"date" : "asc" },
{"tie_breaker_id" : "asc" }
]
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 这里有一个问题,如果我在第2页准备翻到第3页时,refresh 了可能会打乱排序,那么这个分页的结果就不对了。为了避免这种情况,我们可以使用 PIT 来保存当前搜索的索引状态。
具体使用如下: 1)先得到 PIT ID 复制 POST / index_name / _pit ? keep_alive = 1 m 响应如下:
复制 {
"id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA=="
}2)使用 PIT ID 搜索 复制 GET / _search
{
"size" : 10000 ,
"query" : {
"match" : {
"user.id" : "elkbee"
}
},
"pit" : {
"id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==" ,
"keep_alive" : "1m"
},
"sort" : [
{"@timestamp" : {"order" : "asc" , "format" : "strict_date_optional_time_nanos" , "numeric_type" : "date_nanos" }}
]
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 响应如下:
复制 {
"pit_id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==" ,
"took" : 17 ,
"timed_out" : false ,
"_shards" : ... ,
"hits" : {
"total" : ... ,
"max_score" : null ,
"hits" : [
...
{
"_index" : "my-index-000001" ,
"_id" : "FaslK3QBySSL_rrj9zM5" ,
"_score" : null ,
"_source" : ... ,
"sort" : [
"2021-05-20T05:30:04.832Z" ,
4294967298
]
}
]
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 3)pit id + 排序键 翻页 复制 GET / _search
{
"size" : 10000 ,
"query" : {
"match" : {
"user.id" : "elkbee"
}
},
"pit" : {
"id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA==" ,
"keep_alive" : "1m"
},
"sort" : [
{"@timestamp" : {"order" : "asc" , "format" : "strict_date_optional_time_nanos" }}
],
"search_after" : [
"2021-05-20T05:30:04.832Z" ,
4294967298
],
"track_total_hits" : false
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 4)查询完后,删除 PIT 复制 DELETE / _pit
{
"id" : "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2RlXzIAAAAAAAAAAAwBYgACBXV1aWQyAAAFdXVpZDEAAQltYXRjaF9hbGw_gAAAAA=="
}scroll 和 search after 都是用来处理大数据时避免深度翻页的,它们区别如下:
实现方式不同 scroll 使用游标来保持搜索上下文,而 search after 使用排序键来跟踪搜索进度。 参数设置不同 scroll 需要指定一个时间段来保持搜索上下文,而 search after 需要指定一个排序字段和一个起始排序键来开始搜索。 数据处理方式不同 scroll 适用于一次性处理所有数据的场景,每次请求返回的结果可以是任意大小,直到搜索上下文过期或搜索完成为止。而。 排序方式不同 scroll 可能会导致排序不稳定的问题,而 search after 使用排序键来跟踪搜索进度,可以避免这个问题。 兼容性不同 scroll 是 Elasticsearch 5.x 及之前版本的遗留功能,而 search after 是 Elasticsearch 7.0 中引入的新特性,Elasticsearch 7.0 开始推荐使用 search after。 4.3.2 match 想对搜索关键字进行分词,搜索的结果更全面。
特点 会对查询条件进行分词 然后将分词后的查询条件和词条进行等值匹配 默认取并集 复制 GET goods / _search
{
"query" : {
"match" : {
"title" : "华为手机"
}
}
}
# 指定取交集
GET goods / _search
{
"query" : {
"match" : {
"title" : {
"query" : "华为手机" ,
"operator" : "and"
}
}
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 4.3.3 term 不想对搜索关键字进行分词,搜索的结果更加精确。
复制 GET goods / _search
{
"query" : {
"term" : {
"title" : {
"value" : "华为"
}
}
}
}4.3.4 range 当想对数值类型的字段做区间的搜索,例如商品价格。
复制 # 价格大于等于2000,小于等于3000
# gte : >= lte :<= gt :> lt :<
GET goods / _search
{
"query" : {
"range" : {
"price" : {
"gte" : 2000 ,
"lte" : 3000
}
}
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 4.3.5 wildcard 当使用match搜索仍然查询不到数据,可以尝试使用模糊查询,范围更广。
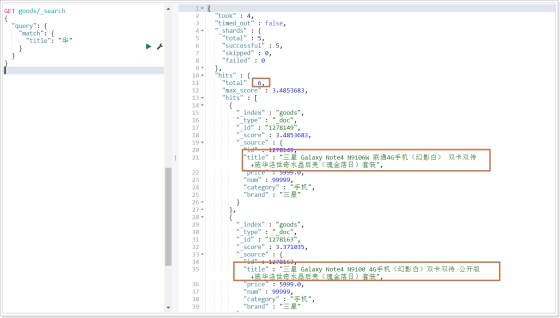
复制 GET goods / _search
{
"query" : {
"match" : {
"title" : "华"
}
}
}运行结果:
可以发现查询的结果中,那些title包含“华为”的数据查不出来,因为那些数据,没有分出"华"这一个字,而分出的就是"华为",这个时候我们若想把包含"华为"的数据都查出来,就可以使用模糊查询。
4.3.6 query_string 当不知道搜索的内容存储在哪个字段时,可以使用字符串搜索。
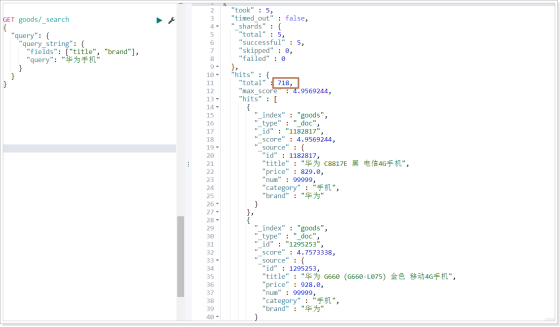
特点 会对查询条件进行分词 将分词后的查询条件和词条进行等值匹配 默认取并集(OR) 可以指定多个查询字段 1)不指定字段
复制 GET goods / _search
{
"query" : {
"query_string" : {
"query" : "华为手机"
}
}
}2)指定字段
复制 GET goods / _search
{
"query" : {
"query_string" : {
"fields" : ["title" , "brand" ],
"query" : "华为手机"
}
}
}运行结果:
4.3.7 bool 当存在多个查询条件时
语法 must(and):条件必须成立 。 must_not(not):条件必须不成立,必须和must或filter连接起来使用 。 should(or):条件可以成立 。 filter:条件必须成立,性能比must高(不会计算得分) 。
复制 # 查询品牌为华为,并且title包含手机的数据
GET goods / _search
{
"query" : {
"bool" : {
"must" : [
{
"term" : {
"brand" : {
"value" : "华为"
}
}
},
{
"match" : {
"title" : "手机"
}
}
]
}
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 运行结果:
4.3.8 Aggregations 聚合查询
聚合类型:
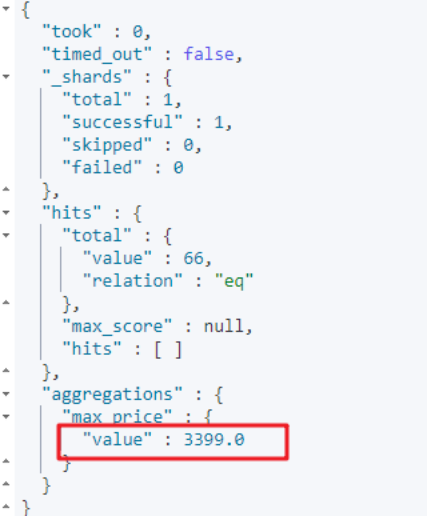
指标聚合:相当于MySQL的聚合函数。比如max、min、avg、sum等。 桶聚合:相当于MySQL的 group by 操作。(不要对text类型的数据进行分组,会失败) 4.3.8.1 指标聚合 复制 # 指标聚合:找品牌是华为的商品中价格最高的商品价格
GET goods / _search
{
"query" : {
"term" : {
"brand" : {
"value" : "华为"
}
}
},
"aggs" : {
"max_price" : {
"max" : {
"field" : "price"
}
}
},
"size" : 0
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 运行结果:
4.3.8.2 桶聚合 复制 # 桶聚合:根据品牌聚合,看每个品牌的手机商品数据量
GET goods / _search
{
"query" : {
"match" : {
"title" : "手机"
}
},
"aggs" : {
"brand_num" : {
"terms" : {
"field" : "brand"
}
}
},
"size" : 0
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 运行结果:
4.3.9 highlight(高亮查询) 复制 # 高亮: 让 title 中的“华为”和“手机”高亮起来
GET goods / _search
{
"query" : {
"match" : {
"title" : "华为手机"
}
},
"highlight" : {
"fields" : {
# 高亮字段
"title" : {
# 前缀
"pre_tags" : "<font class = 'color_class'>" ,
# 后缀
"post_tags" : "</font>"
}
}
}
}1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 运行结果:
5 总结 这篇文章的宗旨是希望可以帮助刚接触ES 的人可以快速了解ES,和掌握ES 的一些常用查询。