作为工程师,日常的工作基本上都是围绕着【系统】展开的。【搭建一个系统】是工程师必须具备的最基础能力。
从业至今,我自己负责过很多系统,也看到过很多系统。有的系统搭建得非常优雅,无论是可读性还是扩展性都非常好。说白了就是代码看起来清晰干净,研发起来快捷且安全,排查问题也容易定位。但还有一些系统你就是看上好几遍代码都捋不清逻辑,改造的时候更是无从下手。
一个系统存在复杂的业务逻辑是正常的,而一个优雅的系统是能够通过良好的结构去管理这些复杂性。我把这个结构称之为【系统框架】。
搭建系统框架是系统建设的第一步,也是最重要一步。我们这篇文章就来聊聊如何搭建一个好的系统框架。
我们先看一个反例:
反例时间
假设我们有一个http接口,需要返回用户的信息。用户信息包括:用户昵称、用户vip等级、用户标签、用户余额、余额历史以来充值总额、用户最贵一次消费。
下面的代码是一种典型的实现方式(可以看注释来了解步骤):

很多同学看到这样的代码觉得已经挺好了。有日志、有注释、有异常处理,代码也没有挤在一堆。但真的是这样吗?
我认为这样的代码确实反映了工程师一定的技术素养,但起码存在以下这些问题:
【Q1】如果新增接口,所有的日志打印要冗余写一遍,包括入口日志、出口日志、异常日志。
【Q2】如果新增接口,try-catch的异常处理逻辑也需要冗余重写。
【Q3】如果新增一个只获取用户金额信息的接口,需要冗余复制上述代码中和金额相关的部分。
【Q4】如果接口需要修改,返回新的信息,那就需要往这个代码里添加新的业务逻辑。而这个类一旦有变化,就涉及对这个类的回归验证。
【Q5】如果我要同时支持可以根据用户昵称来搜索用户信息,那么我要新增一个基本完全一样的接口(除了入参不同)。
(记住以上这些问题,我们下面会逐一来解决)
所以,如果用发展的眼光(需求新增)去看这段代码,你可以基本判断以后会存在大量的逻辑冗余。
大量的冗余会带来研发的低效、升级的遗漏、逻辑不一致的风险等等。
此外,不同工程师可能都有自己的编码习惯,同样是处理日志,异常,写法可以迥然不同。
结合在大厂多年的经验,优雅的系统会结合两种设计方式来解决这类冗余的问题。我们一起来看看。
一、模板模式
【模板模式】就是设计模式中的“模板方法模式”。模板方法模式的核心思想就是:统一算法框架,暴露算法要素给子类来实现。
看定义还是抽象了一些,我们直接看例子。
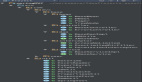
下图就是一个定义了算法框架的抽象模板类:

可以看到,process方法里仅做了两件事:
【1】实现了所有接口的共用逻辑。比如打日志、计算耗时、捕获异常并处理。
【2】确定了步骤(步骤也称之为算法框架)。比如先校验参数,后执行业务逻辑。
基于上面的模板,我们的服务只需要做如下实现就可以了:

下面我们根据【模板模式】的思想修改我们的反面案例,我们的代码就变成了:

可以看到,通过模板模式,你起码会有这样几个好处:
【1】每个接口都不用担心忘了执行必要的公共逻辑,例如打印日志、异常处理。
【2】不用担心接口有遗漏步骤及搞错步骤顺序,例如入参校验在执行业务流程之前。
【3】接口只需要关心自己业务逻辑的实现即可。
【4】所有接口打印的日志及异常处理方式确保是一致的,方便监控和定位问题。
【5】如果需要增加一些公用的能力,例如埋点上报某个统计平台,只需要在框架中添加逻辑,所有接口都直接生效。
我们使用【模板模式】解决了业务无关逻辑的冗余问题,也就是上述针对反面例子提出的问题中的Q1、Q2,下一步我们要动手解决业务逻辑冗余的问题,也就是针对问题Q3、Q4、Q5。
二、流程引擎
流程引擎的核心思想是:将要执行的逻辑看成是一个个步骤的串接,由统一的角色来管理步骤的执行顺序,这个角色就是流程引擎。
我们用两张图来对比下使用流程引擎和常规瀑布式编码的不同。
1.流程式编码 vs 瀑布式编码

上图分别展示了两种编码法方式【瀑布式编码】和【流程式代码】。
【瀑布式编码】就是从上往下按照步骤把业务逻辑写完。
【流程式编码】是先把可以独立的功能抽成一个个执行器。不同的服务根据自己功能的需求来串接这些执行器。
两者对比,流程式编码有这样一些好处:
【避免冗余】:同样的业务逻辑只有一份代码。
【最小修改】:如果需要加一个环节,只需要新增一个处理器,并且编排到流程中即可,对已有代码没有任何侵入。
【方便追踪】:我们可以在每一个节点执行完以后,在流程引擎中添加一些日志,以此来追踪执行过程。例如在哪里中断了?哪个执行器耗时最长?
【利于分工】:每个处理器约定好职责就可以独立开发,并且可以独立测试。
【可读性好】:流程式代码往往在一处编辑所有的步骤,代码可读性佳。看到一个流程由哪些节点组成,基本上就了解大概的逻辑了。
【灵活多变】:流程式编程还可以支持各个处理器以分支和循环的方式组合。
下面我们就来实现一个简单的流程引擎,并用它来继续改造上面的反例,以此来说明【流程式编程】的思想和好处。
2.处理器设计
我们先看下处理器的实现,处理器是被我们抽取出来处理一块业务逻辑的单元。如下图标识

在反例里,我们可以抽取三个处理器。【用户信息处理器】【金额处理器】【消费记录处理器】。处理器接口如下:

细心的同学可能会问,ProcessRequest和ProcessContext是什么?
【ProcessRequest】:对请求信息的封装。例如用户的userId、用户的客户端信息(IOS、安卓、以及对应版本号)、要求转账的金额、转账对象等。每个处理器都能够获得这些信息,根据自己的需要去使用。ProcessRequest中所有的值,原则上不允许被修改,以免原始请求信息被污染。
【ProcessContext】:流程执行的上下文,用于存放整个流程执行过程中的数据。在所有执行器处理完以后,结果组装器可以从ProcessContext中获取到各种结果数据,构造返回结果。
接着我们基于Processor接口,实现三个具体的处理器:



我们处理器就搞定了,等着流程引擎来唤起他们吧!
3.流程引擎设计
下面我们来看流程引擎的设计,如下图标识,可以把这些箭头的控制理解为流程引擎。流程引擎的核心作用就是控制处理器按照指定顺序执行:

下面是流程引擎接口:

流程引擎只有一个start接口用来启动流程。
以下是流程引擎抽象类。抽象类除了实现对处理器执行的控制外,还可以包括日志打印、异常处理等操作。
那一个流程引擎需要执行哪些处理器呢?这由子类决定,子类通过实现getProcessors()抽象方法来指定使用的处理器。你看,这里又有模板模式了是不。

下面看下我们具体的引擎子类是怎样的:

可以看到,引擎子类实现getProcessors()方法即可。此方法就是告诉流程引擎具体要执行的执行器列表及执行顺序。
如果你走读代码到这里,看到list里放的三个处理器名称,你基本上就知道“用户查询接口”提供了怎样的功能。这就是良好的可读性。
试想,如果有一天,一个流程中需要新增一个逻辑,我们可以包装一个新的处理器,然后添加到上图中的processorList中即可。
每个接口都可以实现一个如上截图的引擎子类,用以编排需要执行的处理器。
4.主入口的改造
当引入流程引擎后,我们的主入口(controller)就可以改造成如下这样(我们附上和之前两个版本的对比图):

你可以很明显的看到在改造之后,由于业务逻辑被内聚到一个个处理器中,入口处的代码变得简单清晰。同时你再也不用害怕每次业务需求都要改这个类,从而变得的膨胀不堪。
5.流程引擎设计一览
我们已经看到了整个流程引擎的实现过程。最后我们再用一张类图来一览整个设计,相信会帮助你更好地了解这种设计方法:

今日总结
今天,我们正式进入到【成为工程师】的细节内容。我们提到,一个工程师最基础的能力就是搭建系统。而一个系统要搭建得好,首先就要有一个好的系统框架。
我们先是通过一个反例来说明了典型的瀑布式编码存在的问题。继而讲了通过模板模式和流程引擎两种设计方式来优化瀑布式设计。以此让系统的扩展变得”容易、安全且规范“。
对于流程引擎,我们只是给出了一种最最基础的实现方式而已,但是对于很多系统来说,这么设计已经足够了。事实上,真正强大的流程引擎还包括【分支循环】【异步化】【可视化界面管理】等各种高阶功能,你可以自己做一些了解。
不过,流程引擎的选择需要结合实际情况,不然也会引入额外的复杂度。
建议你收藏这篇文章,当你碰到系统设计问题的时候,可以回头来看看,相信可以帮助到你。
下一章我们会接着讲系统设计方面的问题,来讲讲一个系统要如何分层。
加油吧,未来的架构师们!
本文转载自微信公众号「 CodingBetterLife」,作者「 赵志强 」,可以通过以下二维码关注。

转载本文请联系「 CodingBetterLife」公众号。