












每当你遇到文本处理问题时,正则表达式(regex)总是你的好朋友。
然而,要记住所有复杂的规则是很难的甚至是不可能的。甚至仅仅阅读语法也是令人不知所措的。
因此,学习正则表达式的优秀方法是通过学习实际示例。
本文将总结日常编程场景中常用的九个正则表达式技巧。阅读完后,正则表达式对你来说就像喝杯茶一样简单。

1.验证电子邮件地址
检查电子邮件地址的有效性是正则表达式的经典用例。
下面是一个示例程序:
在这个例子中,我们使用 Python 中的 re 模块来编译一个匹配有效电子邮件格式的正则表达式模式。然后,我们使用它的 match() 函数来检查 email 变量是否与模式匹配。
在模式中,有几个关键点:
- 我们使用 [] 表示一个范围。例如,[a-zA-Z0-9] 可以匹配 0 到 9 之间的数字、A 到 Z 之间的字母或 a 到 z 之间的字母。
- ^ 表示行的开头。在我们的例子中,我们使用它来确保文本必须以 [a-zA-Z0-9] 开始。
- $ 表示行的结尾。
- \ 用于转义特殊字符(允许我们匹配像 ‘.’ 这样的字符)。
- {n,m} 语法是用来匹配 n-m 个先前的正则表达式。我们使用了 {2,},这意味着前面的部分 [a-zA-Z] 应该至少重复 2 次。这就是为什么 “elon@example.c” 被识别为无效的电子邮件地址。
- ■表示匹配前面的正则表达式至少 1 次。例如,ab+ 将匹配 a 后面的任何非零数量的 b。
这个经典的例子演示了在 Python 中使用正则表达式的一些基本语法。
实际上,Python 的 re 模块是一个隐藏的宝藏,我们可以从中使用许多更多的技巧。
2.从字符串中提取数字
要从长文本中找到一些特殊字符,最直接的想法是使用 for 循环遍历所有字符并找到所需的内容。
但是,没有必要使用任何循环。正则表达式就是为了作为过滤器而生的。
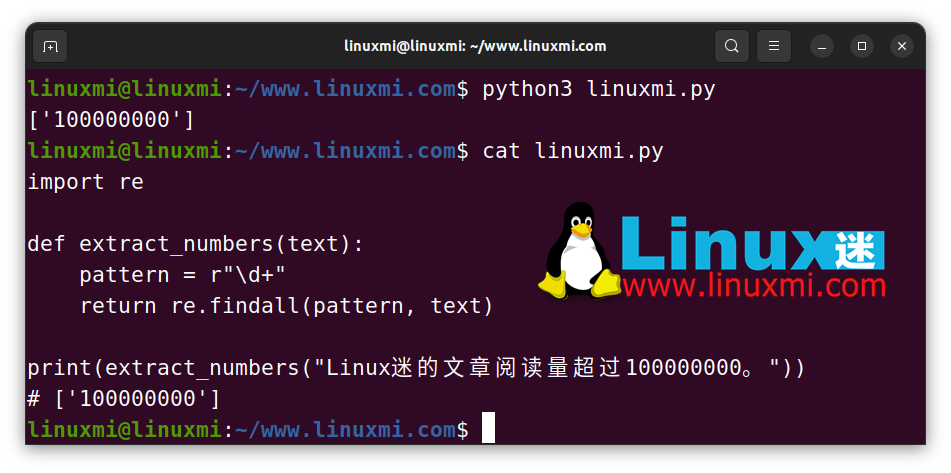
如上所示,re.findall() 函数接收一个正则表达式和一个文本,可以方便地帮助我们找到所有我们需要的字符。
其中 \d 用于在正则表达式中匹配数字。
接下来我们看一个具体例子,演示 \d 的用途。
3.验证电话号码
下面的例子利用了 \d 的用法来验证有效的电话号码:
除了 \d 外,我们还使用了 ^、$ 和 {n} 语法来确保字符串是一个有效的电话号码。
4.将文本分割成单词
将长文本分割成单独的单词是日常编程中的另一个常见需求。借助 re 模块的 split() 函数,我们可以轻松完成此任务:
如上述代码所示,我们使用 \s 来在正则表达式中匹配一个空格。
5.使用正则表达式查找和替换文本
在使用正则表达式从文本中找到特定字符后,我们可能需要用新的字符串来替换它们。
re 模块的 sub() 函数可以使这个过程变得非常顺畅:
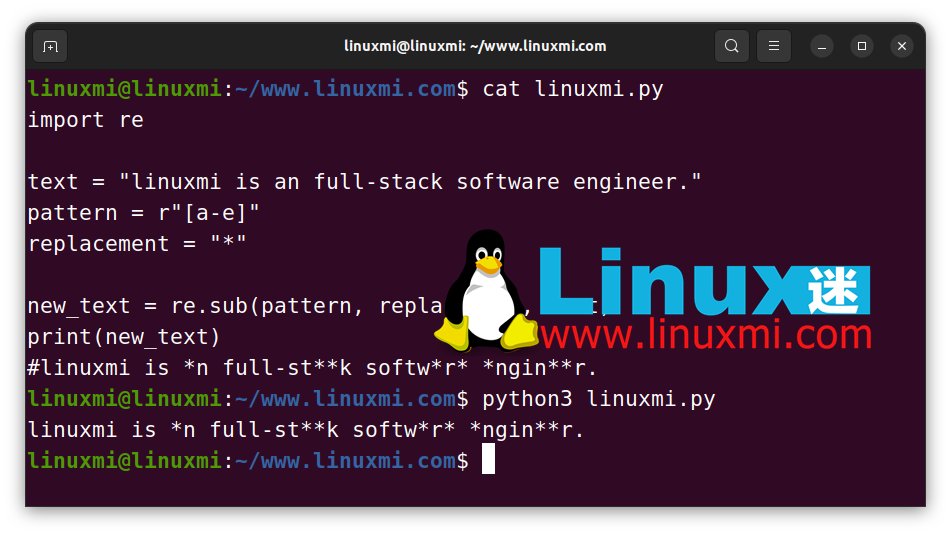
如上所示,我们只需要将三个参数传递给sub()函数:模式、替换字符串和原始文本。它将在执行后返回新文本。
6.在Python中预编译正则表达式
在Python中使用正则表达式匹配字符串时,有两个步骤:
编译正则表达式。 使用编译后的正则表达式匹配字符串。 因此,如果一个正则表达式被重复使用,每次编译都会浪费时间。
为了避免这种情况,Python允许我们预先编译一个正则表达式,然后重复使用编译后的对象进行后续匹配。这可以显著提高性能和效率。
上面的例子展示了如何使用re模块中的compile()函数预编译正则表达式并稍后使用它。只要字符串无法匹配正则表达式,match()函数就会返回None。
7.提取和操作文本的子内容
group()方法是Python re模块中的一个函数,它返回一个或多个匹配的正则表达式匹配对象的子组。它非常方便,用于提取文本的不同部分。
例如,以下代码展示了如何从“HH:MM”格式的时间字符串中提取两个部分:
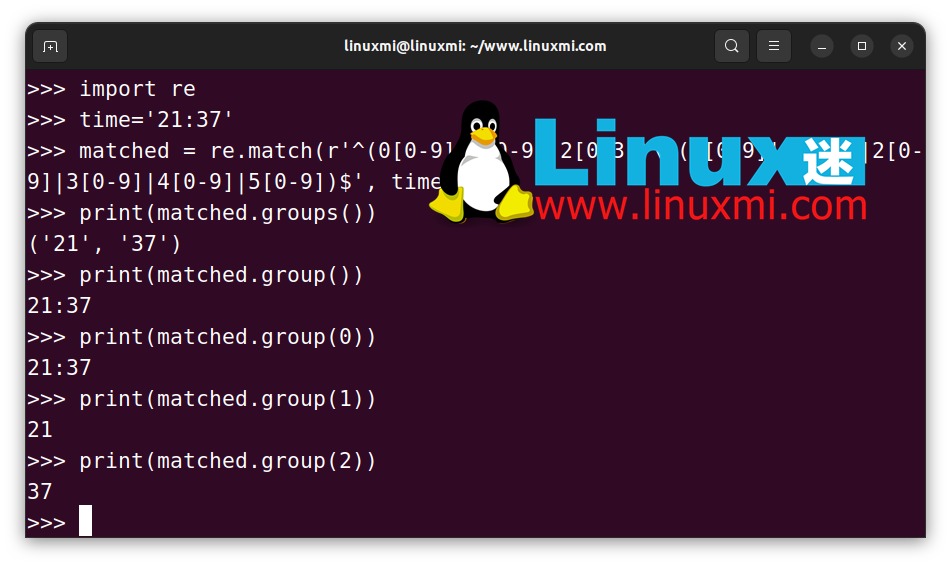
如上所示,group(0) 返回原始字符串。然后,group(1) 和 group(2) 分别返回匹配字符串的第一部分和第二部分。
8.用于提取子内容的命名分组
如果子组数量变得很多,由于太多的神奇数字,程序将很难阅读。
因此,Python 提供了用于子内容提取的命名组技巧:我们可以使用命名组捕获匹配字符串的特定部分,而不是使用编号的捕获组。这可以使我们的代码更易于阅读和维护。
以下是一个例子:
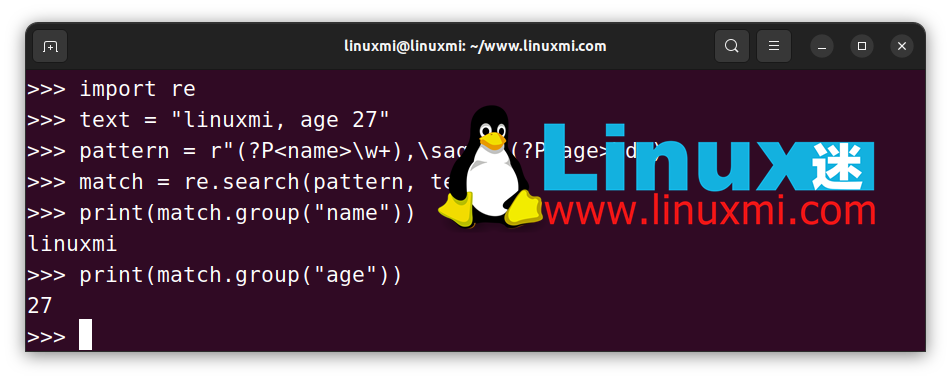
如上所示,命名分组的关键语法是 ?P<xxx>。它定义了对应组的名称,我们可以使用 group() 函数根据名称提取内容。
9.使用VERBOSE标志使正则表达式易读
在一些复杂的情况下,正则表达式可能会变得越来越复杂和难以读取。我们肯定需要一种方法来使其更整洁和干净。
这就是re.VERBOSE技巧。
如上所示,我们可以将复杂的正则表达式分成多行,以提高可读性。只要在re.search()函数中加入re.VERBOSE标志,它就可以像平常一样被正确识别。


















