Bash 成为了每个类 Unix 或基于 Unix 的操作系统的默认自动化语言。每个系统管理员、DevOps 工程师和程序员通常使用 Bash 编写具有重复命令序列的 shell 脚本。Bash 脚本通常包含运行其他程序二进制文件的命令。在大多数情况下,我们可能需要在 shell 脚本中处理数据并创建逻辑流程。因此,我们经常需要在 shell 脚本中添加条件语句和文本操作语句。
传统的 Bash 脚本和使用旧版本 Bash 解释器的过去的程序员通常使用 awk、sed、tr 和 cut 命令进行文本操作。这些是单独的程序。尽管这些文本处理程序提供了良好的功能,但它们会减慢您的 Bash 脚本,因为每个特定命令都具有相当的进程生成时间。现代 Bash 版本通过著名的参数扩展功能提供了内置的文本处理功能。
在本文中,我将解释一些内置的字符串操作语法,您可以使用这些语法在 Bash 脚本中高效地处理文本。

子字符串提取和替换
子字符串是指特定字符串的连续片段或部分。在各种脚本编写场景中,我们需要从字符串片段中提取子字符串。例如,您可能需要仅从包含扩展名的完整文件名中获取文件名部分。此外,您可能需要使用特定字符串段替换子字符串(例如,更改文件名的文件扩展名)。
提取子字符串非常容易,只需提供字符位置和长度:
#!/bin/bash
# Linux迷 www.linuxmi.com
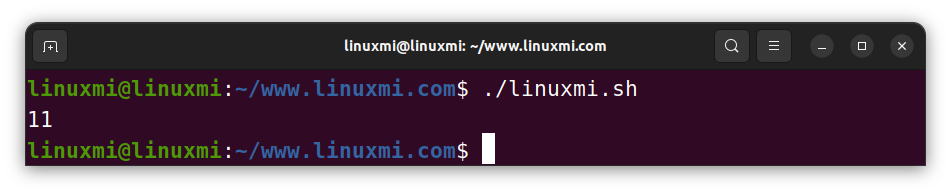
str="2023-10-12"
echo "${str:5:2}" # 10
echo "${str::4}" # 2023
echo "2022-${str:5}" # 2022-10-12
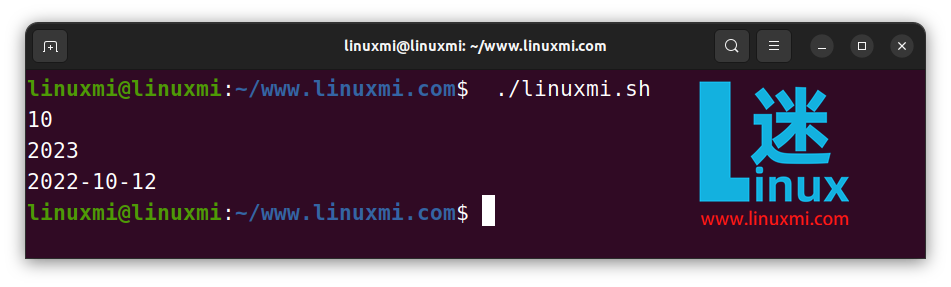
你甚至可以从右边进行子字符串计算,如下所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
str="backup.sql"
echo "original${str:(-4)}" # original.sql
Bash 还提供了一种高效的内置语法来进行子字符串替换:
#!/bin/bash
# Linux迷 www.linuxmi.com
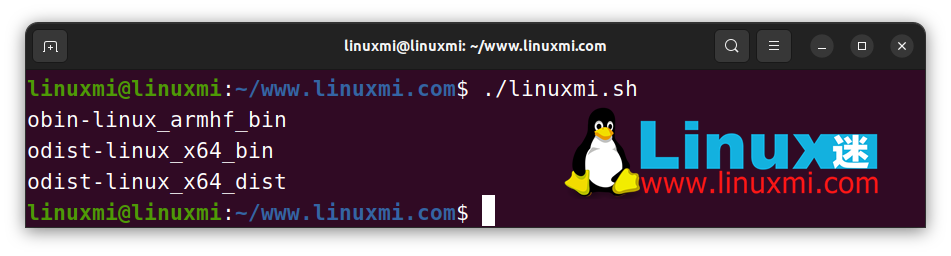
str= "obin-linux_x64_bin"
echo " ${str/x64/armhf} " # obin-linux_armhf_bin
echo " ${str/bin/dist} " # odist-linux_x64_bin
echo " ${str// bin/dist} " # odist-linux_x64_dist
linuxmi@linuxmi:~/www.linuxmi.com$ ./linuxmi.sh
obin-linux_armhf_bin
odist-linux_x64_bin
odist-linux_x64_dist
当你处理一些字符串时,例如文件名、路径等,你可能需要替换字符串的前缀和后缀。将一个文件扩展名替换为另一个扩展名就是一个很好的例子。看下面的例子:
#!/bin/bash
# Linux迷 www.linuxmi.com
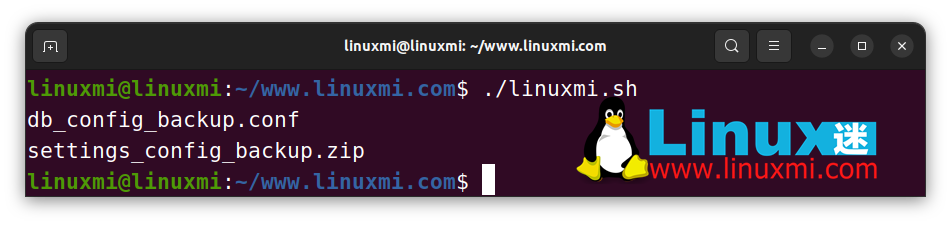
str="db_config_backup.zip"
echo "${str/%.zip/.conf}" # db_config_backup.conf
echo "${str/#db/settings}" # settings_config_backup.zip
在上面的子字符串替换示例中,我们使用了确切的子字符串段进行匹配,但您还可以使用 * 通配符字符来使用子字符串的一部分,如下所示:
#!/bin/bash
str="db_config_backup.zip"
echo "${str/%.*/.bak}" # db_config_backup.conf
echo "${str/#*_/new}" # newbackup.zip
如果您不知道要搜索的确切子字符串,上述方法很有用。
正则表达式匹配、提取和替换
许多 Unix 或 GNU/Linux 用户已经知道,可以使用 grep 和 sed 进行基于正则表达式的文本搜索。sed 帮助我们进行正则表达式替换。你可以使用内置的 Bash 正则表达式功能来处理文本,比使用这些外部二进制文件更快。
你可以使用 if 条件和 =~ 操作符执行正则表达式匹配,如下面的代码片段所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
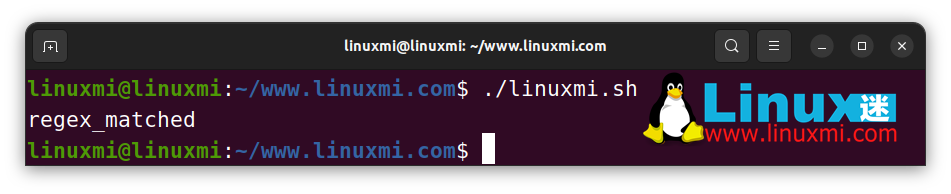
str="db_backup_2003.zip"
if [[ $str =~ 200[0-5]+ ]]; then
echo "regex_matched"
fi
如果你想的话,也可以用内联条件语句来替换 if 语句,如下所示:
[[ $str =~ 200[0-5]+ ]] && echo "regex_matched"
一旦 Bash 解释器执行了一个正则表达式匹配,它通常会将所有匹配结果存储在 BASH_REMATCH shell 变量中。这个变量是一个只读数组,并将整个匹配的数据存储在第一个索引中。如果使用子模式,则 Bash 会逐步将这些匹配项存储在其他索引中:
#!/bin/bash
# Linux迷 www.linuxmi.com
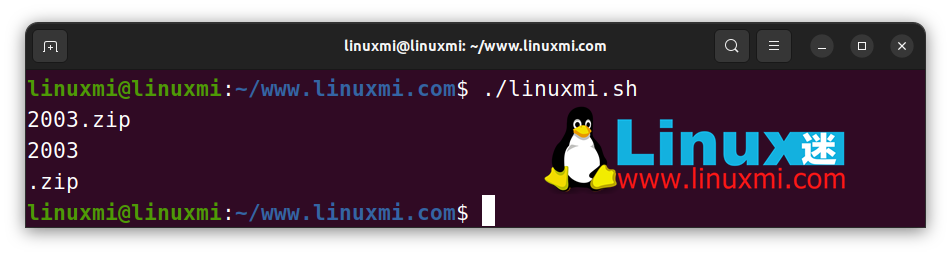
str="db_backup_2003.zip"
if [[ $str =~ (200[0-5])(.*)$ ]]; then
echo "${BASH_REMATCH[0]}" # 2003.zip
echo "${BASH_REMATCH[1]}" # 2003
echo "${BASH_REMATCH[2]}" # .zip
fi
记得我们之前在子字符串匹配中使用了通配符吗?类似地,可以在参数扩展中使用正则表达式定义,如下面的例子所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
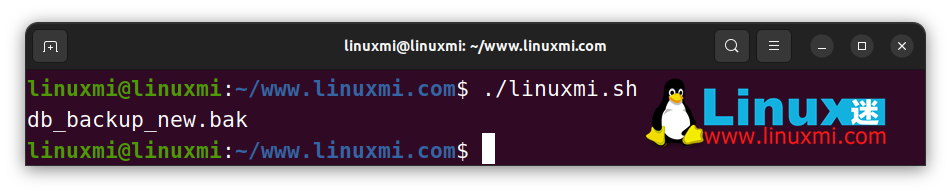
str="db_backup_2003.zip"
re="200[0-3].zip"
echo "${str/$re/new}.bak" # db_backup_new.bak
子字符串删除技巧
我们在许多文本处理需求中经常需要预处理文本段,以删除不需要的子字符串。例如,如果您提取了一个带有 v 前缀和一些构建编号的版本号,并想找到主要版本号,则必须删除一些子字符串。您可以使用相同的子字符串替换语法,但省略替换字符串参数以进行字符串删除,如下所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
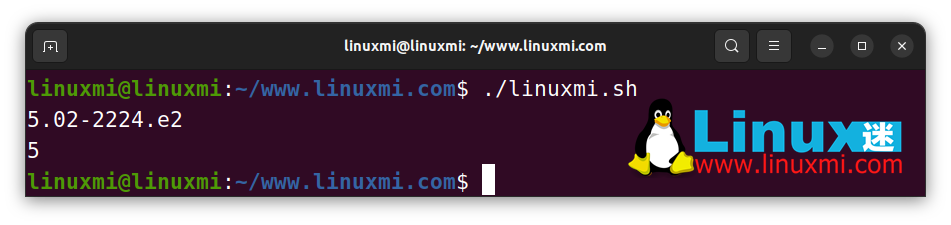
str="ver5.02-2224.e2"
ver="${str#ver}"
echo $ver # 5.02-2224.e2
maj="${ver/.*}"
echo $maj # 5
在上面的示例中,我们使用了精确的子字符串和通配符进行子字符串删除,但是您还可以使用正则表达式。看看如何提取一个不带冗余字符的干净版本号:
#!/bin/bash
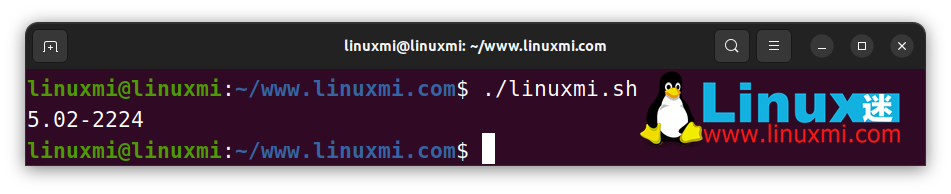
# Linux迷 www.linuxmi.com
str="ver5.02-2224_release"
ver="${str//[a-z_]}"
echo $ver # 5.02-2224
大小写转换和基于大小写的变量
即使是标准的 C 语言也提供了一个函数来转换字符的大小写。几乎所有现代编程语言都提供了内置函数来进行大小写转换。作为一种命令语言,Bash 不提供大小写转换的函数,但它通过参数扩展和变量声明为我们提供了大小写转换的功能。
请看下面的示例,它将字母的大小写进行转换:
#!/bin/bash
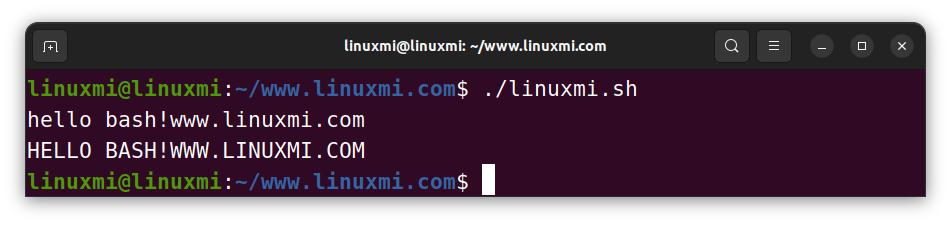
# Linux迷 www.linuxmi.com
str="Hello Bash!www.linuxmi.com"
lower="${str,,}"
upper="${str^^}"
echo $lower # hello bash!www.linuxmi.com
echo $upper # HELLO BASH!WWW.LINUXMI.COM
你也可以只将字符串的第一个字符大写或小写,如下所示:
#!/bin/bash
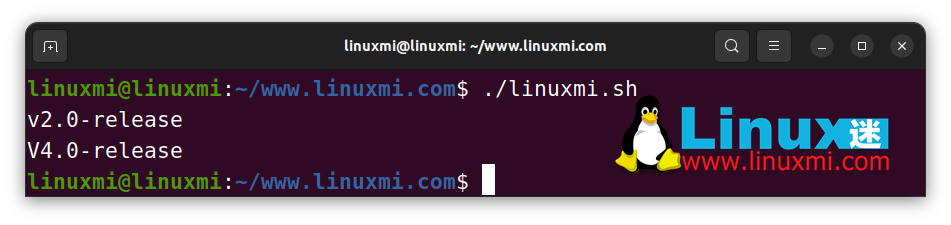
# Linux迷 www.linuxmi.com
ver1="V2.0-release"
ver2="v4.0-release"
echo "${ver1,}" # v2.0-release
echo "${ver2^}" # V4.0-release
如果您需要使特定变量严格大写或小写,您不需要每次都运行一个大小写转换函数。相反,您可以使用内置的declare命令为特定变量添加大小写属性,如下面的示例所示:
#!/bin/bash
# Linux迷 www.linuxmi.com
declare -l ver1
declare -u ver2
ver1="V4.02.2"
ver2="v2.22.1"
echo $ver1 # v4.02.2
echo $ver2 #V2.22.1
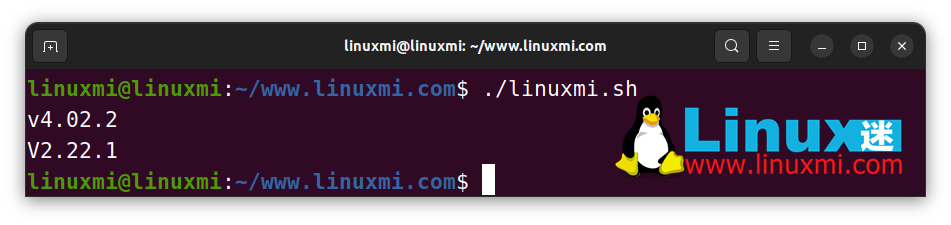
上面的 ver1 和 ver2 变量在声明时接收到了大小写属性,因此每当你为一个特定的变量分配一个值时,Bash 会根据变量属性转换文本大小写。
拆分字符串(字符串到数组的转换)
Bash 允许你使用 declare 内置函数定义索引和关联数组。大多数通用编程语言提供了在字符串对象中或通过标准库函数中拆分方法(例如 Go 的 strings.Split 函数)。在 Bash 中,你可以使用多种方法拆分一个字符串并创建一个数组。例如,我们可以将 IFS 更改为所需的分隔符并使用 read 内置函数,或者我们可以使用 tr 命令和循环构建数组,另外使用内置参数展开也是一种方法。在 Bash 中有很多字符串拆分方法。
使用 IFS 和 read 是最简单和无误的拆分字符串的方法之一:
#!/bin/bash
# Linux迷 www.linuxmi.com
str="C,C++,JavaScript,Python,Bash"
IFS=',' read -ra arr <<< "$str"
echo "${#arr[@]}" # 5
echo "${arr[0]}" # C
echo "${arr[4]}" # Bash
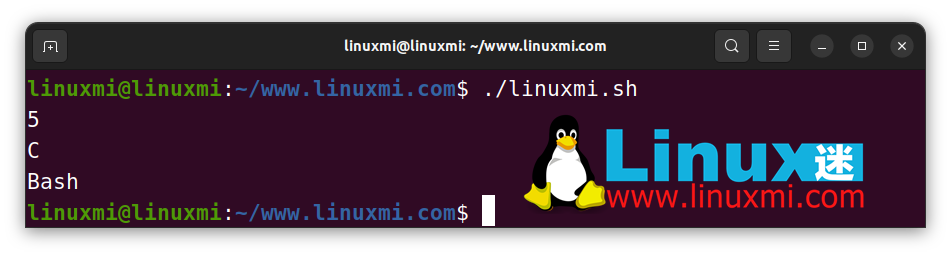
上面的代码片段使用,作为分隔符,并使用内置的read命令基于IFS创建一个数组。
即使有最简单的方法可以在不使用read的情况下处理拆分,但要确保没有隐藏的问题。例如,以下拆分实现非常简单,但当您将*(扩展为当前目录的内容)作为元素,空格作为分隔符时,它会出现问题:
#!/bin/bash
# Linux迷 www.linuxmi.com
# 警告:这段代码有几个隐藏的问题。
str="C,Bash,*"
arr=(${str//,/ })
echo "${#arr[@]}" # 包含当前目录内容