1、背景
在 Redis 中,在 AOF 文件重写、生成 RDB 备份文件以及主从全量同步过程中,都需要使用系统调用 fork 创建一个子进程来获取内存数据快照,在 fork() 函数创建子进程的时候,内核会把父进程的「页表」复制一份给子进程,如果页表很大,复制页表的过程耗时会非常长,那么在此期间,业务访问 Redis 读写延迟会大幅增加。
最近,阿里云联合上海交大,在数据库顶级会议 VLDB 上发表了一篇文章《Async-fork: Mitigating Query Latency Spikes Incurred by the Fork-based Snapshot Mechanism from the OS Level》,文章介绍到,他们设计了一个新的 fork(称为 Async-fork),将 fork 调用过程中最耗时的页表拷贝部分从父进程移动到子进程,父进程因而可以快速返回用户态处理用户查询,子进程则在此期间完成页表拷贝,从而减少 fork 期间到达请求的尾延迟。所以该特性在类似 Redis 类型的内存数据库上均能取得不错的效果。
2、基本概念
2.1 物理内存地址
也即实际的物理内存地址空间。
2.2 虚拟地址空间
虚拟地址空间(Virtual Address Space)是每一个程序被加载运行起来后,操作系统为进程分配的虚拟内存,它为每个进程提供了一个假象,即每个进程都在独占地使用主存。
每个进程所能访问的最大的虚拟地址空间由计算机的硬件平台决定,具体地说是由 CPU 的位数决定的。比如 32 位的 CPU 就是我们常说的 4GB 虚拟内存空间。
程序访问内存地址使用虚拟地址空间,然后由操作系统将这个虚拟地址映射到适当的物理内存地址上。这样,只要操作系统处理好虚拟地址到物理内存地址的映射,就可以保证不同的程序最终访问的内存地址位于不同的区域,彼此没有重叠,就可以达到内存地址空间隔离的效果。
当进程创建时,每个进程都会有一个自己的 4GB 虚拟地址空间。要注意的是这个 4GB 的地址空间是“虚拟”的,并不是真实存在的,而且每个进程只能访问自己虚拟地址空间中的数据,无法访问别的进程中的数据,通过这种方法实现了进程间的地址隔离。
对于 Linux,4GB 的虚拟地址空间包含用户态虚拟内存空间和内核态虚拟内存空间两部分,默认分配状态如下:

2.3 内存页表
「页表」保存的是虚拟内存地址与物理内存地址的映射关系。
CPU 访问数据的时候,CPU 发出的地址是虚拟地址,CPU 中内存管理单元(MMU)通过查询页表,把虚拟地址转换为物理地址,再去访问物理内存条。
2.3.1 内存分页
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小,这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在 Linux 下,每一页的大小为 4KB。
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万(2^20)个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是每个进程都是有自己的虚拟地址空间,也就说都有自己的页表。每个机器上同时运行多个进程,页表将占用大量内存。
2.3.2 多级页表
要解决上面提到的存储进程页表项占用大量内存空间的问题,就需要采用一种叫作多级页表(Multi-Level Page Table)的解决方案。
我们把这个 100 多万个「页表项」的单级页表再分页,将页表(一级页表)分为 1024 个页表(二级页表),每个二级页表中包含 1024 个「页表项」,形成二级分页。这样,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。也就是,内存中只需要保存一级页表以及使用到的二级页表,大量的未被使用的二级页表则不需要分配内存并加载在内存中,因此,达到节省页表占用内存空间的目的。
对于 64 位的系统,使用四级分页目录,分别是:
- 页全局目录项 PGD(Page Global Directory);
- 页上级目录项 PUD(Page Upper Directory);
- 页中间目录项 PMD(Page Middle Directory);
- 页表项 PTE(Page Table Entry);

2.4 虚拟内存区域(VMA)
进程的虚拟内存空间包含一段一段的虚拟内存区域(Virtual memory area, 简称 VMA),每个 VMA 描述虚拟内存空间中一段连续的区域,每个 VMA 由许多虚拟页组成,即每个 VMA 包含许多页表项 PTE。
3、Fork 原理
在默认 fork 的调用过程中,父进程需要将许多进程元数据(例如文件描述符、信号量、页表等)复制到子进程,而页表的复制是其中最耗时的部分(占据 fork 调用耗时的 97% 以上)。
Linux 的 fork() 使用写时拷贝 (copy-on-write) 页的方式实现。写时拷贝是一种可以推迟甚至避免拷贝数据的技术。在创建子进程的过程中,操作系统会把父进程的「页表」复制一份给子进程,这个页表记录着虚拟地址和物理地址映射关系,此时,操作系统并不复制整个进程的物理内存,而是让父子进程共享同一个物理内存。同时,操作系统内核会把共享的所有的内存页的权限都设为 read-only。
那什么时候会发生物理内存的复制呢?
当父进程或者子进程在向共享内存发起写操作时,内存管理单元 MMU 检测到内存页是 read-only 的,于是触发缺页中断异常(page-fault),处理器会从中断描述符表(IDT)中获取到对应的处理程序。在中断程序中,内核就会把触发异常的物理内存页复制一份,并重新设置其内存映射关系,将父子进程的内存读写权限设置为可读写,于是父子进程各自持有独立的一份,之后进程才会对内存进行写操作,这个过程也被称为写时复制(Copy On Write)。

4、Fork 的痛点
在原生 fork 下,在父进程调用 fork() 创建子进程的过程中,虽然使用了写时复制页表的方式进行优化,但由于要复制父进程的页表,还是会造成父进程出现短时间阻塞,阻塞的时间跟页表的大小有关,页表越大,阻塞的时间也越长。
我们在测试中很容易观察到 fork 产生的阻塞现象,以及 fork 造成的 Redis 访问抖动现象。
4.1 测试环境
Redis 版本:优化前 Redis-server
机器操作系统:无 Async-fork 特性的系统
测试数据量:21.63G
4.2 阻塞现象复现
在使用 Redis-benchmark 压测的过程中,手动执行 bgsave 命令,观察 fork 耗时和压测指标 TP100。
使用 info stats 返回上次 fork 耗时:latest_fork_usec:183632,可以看到 fork 耗时 183 毫秒。
在压测过程中分别不执行 bgsave 和执行 bgsave,结果如下:
从压测数据可以看到,单机环境下压测,压测时未执行 bgsave,TP100 约 1 毫秒;如果压测过程中,手动执行 bgsave 命令,触发 fork 操作,TP100 达到 187 毫秒。
4.3 Strace 跟踪 fork 过程耗时
strace 常用来跟踪进程执行时的系统调用和所接收的信号。
由于 Linux 中通过 clone() 系统调用实现 fork();我们可以看到追踪到 clone 系统调用,并且耗时 183 毫秒,与 info stats统计的 fork 耗时一致。
5、Async-fork
鉴于以上 linux 原生 fork 系统调用的痛点,对于像 Redis 这样的高性能内存数据库,将会增加 fork 期间的用户访问延迟,论文中设计了一个新的 fork(称为 Async-fork)来解决上述问题。
Async-fork 设计的核心思想是将 fork 调用过程中最耗时的页表拷贝工作从父进程移动到子进程,缩短父进程调用 fork 时陷入内核态的时间,父进程因而可以快速返回用户态处理用户查询,子进程则在此期间完成页表拷贝。与 Linux 中的默认原生 fork 相比,Async-fork 显著减少了 Redis 快照期间到达请求的尾延迟。
5.1 Async-fork 的挑战
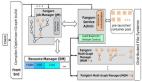
然而,Async-fork 的实现过程中,实际工作并非描述的这么简单。页表的异步复制操作可能导致快照不一致。以下图为例,Redis 在 T0 时刻保存内存快照,而某个用户请求在 T2 时刻向 Redis 插入了新的键值对(k2, v2),这将导致父进程修改它的页表项(PTE2)。假如 T2 时刻这个被修改的页表项(PTE2)还没有被子进程复制完成, 这个修改后的内存页表项及对应内存页后续将被复制到子进程,这个新插入的键值对将被子进程最终写入硬盘,破坏了快照一致性。(快照文件应该记录的是保存拍摄内存快照那一刻的内存数据)
图片来源于:参考资料[1] 第 8 页
5.2 Async-fork 详解
前面提到,每个进程都有自己的虚拟内存空间,Linux 使用一组虚拟内存区域 VMA 来描述进程的虚拟内存空间,每个 VMA 包含许多页表项。
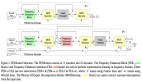
在默认 fork 中,父进程遍历每个 VMA,将每个 VMA 复制到子进程,并自上而下地复制该 VMA 对应的页表项到子进程,对于 64 位的系统,使用四级分页目录,每个 VMA 包括 PGD、PUD、PMD、PTE,都将由父进程逐级复制完成。在 Async-fork 中,父进程同样遍历每个 VMA,但只负责将 PGD、PUD 这两级页表项复制到子进程。
随后,父进程将子进程放置到某个 CPU 上使子进程开始运行,父进程返回到用户态,继续响应用户请求。由子进程负责每个 VMA 剩下的 PMD 和 PTE 两级页表的复制工作。
如果在父进程返回用户态后,子进程复制内存页表期间,父进程需要修改还未完成复制的页表项,怎样避免上述提到的破坏快照一致性问题呢?
图片来源于:参考资料[1] 第 7 页
5.2.1 主动同步机制
父进程返回用户态后,父进程的 PTE 可能被修改。如果在子进程复制内存页表期间,父进程检测到了 PTE 修改,则会触发主动同步机制,也就是父进程也加入页表复制工作,来主动完成被修改的相关页表复制,该机制用来确保 PTE 在修改前被复制到子进程。
当一个 PTE 将被修改时,父进程不仅复制这一个 PTE,还同时将位于同一个页表上的所有 PTE(一共 512 个 PTE),连同它的父级 PMD 项复制到子进程。
父进程中的 PTE 发生修改时,如果子进程已经复制过了这个 PTE,父进程就不需要复制了,否则会发生重复复制。怎么区分 PTE 是否已经复制过?
Async-fork 使用 PMD 项上的 RW 位来标记是否被复制。具体而言,当父进程第一次返回用户态时,它所有 PMD 项被设置为写保护(RW=0),代表这个 PMD 项以及它指向的 512 个 PTE 还没有被复制到子进程。当子进程复制一个 PMD 项时,通过检查这个 PMD 是否为写保护,即可判断该 PMD 是否已经被复制到子进程。如果还没有被复制,子进程将复制这个 PMD,以及它指向的 512 个 PTE。
在完成 PMD 及其指向的 512 个 PTE 复制后,子进程将父进程中的该 PMD 设置为可写(RW=1),代表这个 PMD 项以及它指向的 512 个 PTE 已经被复制到子进程。当父进程触发主动同步时,也通过检查 PMD 项是否为写保护判断是否被复制,并在完成复制后将 PMD 项设置为可写。同时,在复制 PMD 项和 PTE 时,父进程和子进程都锁定 PTE 表,因此它们不会出现同时复制同一 PMD 项指向的 PTE。
在操作系统中,PTE 的修改分为两类:
1)VMA 级的修改。例如,创建、合并、删除 VMA 等操作作用于特定 VMA 上,VMA 级的修改通常会导致大量的 PTE 修改,因此涉及大量的 PMD。
2)PMD 级的修改。PMD 级的修改仅涉及一个 PMD。
5.2.2 错误处理
Async-fork 在复制页表时涉及到内存分配,难免会发生错误。例如,由于内存不足,进程可能无法申请到新的 PTE 表。当错误发生时,应该将父进程恢复到它调用 Async-fork 之前的状态。
在 Async-fork 中,父进程 PMD 项目的 RW 位可能会被修改。因此,当发生错误时,需要将 PMD 项全部回滚为可写。
6、Redis 优化实践
6.1 Async-fork 阻塞现象
在支持 Async-fork 的操作系统(即 Tair 专属操作系统镜像)机器上测试,理论上来说,按照文章的预期,用户不需要作任何修改(Async-fork 使用了原生 fork 相同的接口,没有另外新增接口),就可以享受 Async-fork 优化带来的优势,但是,使用 Redis 实际测试过程中,结果不符合预期,在 Redis 压测过程中手动执行 bgsave 命令触发 fork 操作,还是观察到了 TP100 抖动现象。
测试环境
Redis 版本:优化前 Redis-Server
机器操作系统:Tair 专属操作系统镜像
测试数据量:54.38G
问题现象
现象:fork 耗时正常,但是压测过程中执行 bgsave,TP100 不正常
在压测过程中执行 bgsave,使用 info stats 返回上次 fork 耗时:latest_fork_usec:426
TP100 结果如下:
也就是说,观察到的 fork 耗时正常,但是压测过程中 Redis 依然出现了尾延迟,这显然不符合预期。
追踪过程
使用 strace 命令进行分析,结果如下:
可以观察到,clone 耗时 380 微秒,已经大幅降低,也就 fork 快速返回了用户态响应用户请求。然而,注意到,紧接着出现了一个 mmap 耗时 358 毫秒,与 TP100 数据接近。
由于 mmap 系统调用会在当前进程的虚拟地址空间中,寻找一段满足大小要求的虚拟地址,并且为此虚拟地址分配一个虚拟内存区域( vm_area_struct 结构),也就是会触发 VMA 级虚拟页表变化,也就触发父进程主动同步机制,父进程主动帮助完成相应页表复制动作。VMA 级虚拟页表变化,需要将对应的三级和四级所有页目录都复制到子进程,因此,耗时比较高。
那么,这个 mmap 调用又是哪里来的呢?
定位问题
perf 是 Linux下的一款性能分析工具,能够进行函数级与指令级的热点查找。
通过 perf trace 可以看到响应调用堆栈及耗时,分析结果如下:
也就可以看到,在 bgsave 执行逻辑中,有一处打印日志中的 fprintf 调用了 mmap,很显然这应该是 fork 返回父进程后,父进程中某处调用。
6.2 Async-fork 适配优化
针对找出来的代码位置,可以进行相应优化,针对此处的日志影响,我们可以屏蔽日志或者将日志移动到子进程进行打印,通过同样的分析手段,如果存在其他影响,均可进行对应优化。进行相应适配优化修改后,我们再次进行测试。
测试环境
Redis 版本:优化后 Redis-Server
机器操作系统:Tair 专属操作系统镜像
测试数据量:54.38G
现象
在压测过程中执行 bgsave,fork 耗时和 TP100 均正常。
使用 info stats 返回上次 fork 耗时:latest_fork_usec:414
TP100 结果如下:
跟踪验证
再次使用 strace 和 perf 工具跟踪验证
strace 跟踪父进程只看到 clone,并且耗时只有 378 微秒,
Perf trace 跟踪父进程也只看到 clone 调用
由于我们的优化是将触发 mmap 的相关日志修改到子进程中,使用 Perf trace 跟踪 fork 产生的子进程,命令为:
strace -p 14697 -T -tt -f -ff -o strace05.out
通过 Redis 日志文件找到子进程 pid 为 15931;打开对应生成的保存子进程 strace 信息的文件strace05.out.15931(父进程 strace 信息保存在文件strace05.out.14697)
在子进程中看到了 mmap 调用,子进程中调用不会影响父进程对业务访问的响应。
7性能测试
修改 Redis 代码,针对 Async-fork 适配优化后,我们针对 fork 与 Async-fork 进行了性能对比测试;测试包含不同数据量下 fork() 命令耗时与 fork() 操作对压测过程中 TP100 的影响。
7.1 fork() 命令耗时
fork() 命令耗时,即针对 Redis 执行 bgsave 命令后,通过 Redis 提供的 info stats命令观察到的latest_fork_usec用时。

注:由于 fork 与 Async-fork 系统下,fork() 操作产生的latest_fork_usec数据差距悬殊非常大,使用单纵轴会导致 Async-fork 的数据在图表中显示不明显,不方便查看,因此,该图表使用了双纵轴;虽然 Async-fork 的图表看起来比较高,但是实际右纵轴范围小,所以数据小
从图表可以看出,使用支持 Async-fork 的操作系统,fork() 操作产生的耗时非常小,不管数据量多大,耗时都非常稳定,基本在 200 微秒左右;而原生 fork 产生的耗时会随着数据量增长而增长,而且是从几十毫秒增长到几百毫秒。
7.2 TP100 抖动
在使用 Redis-benchmark 压测过程中,手动执行 bgsave 命令,触发操作系统 fork() 操作,观察不同数据量下,fork 与 Async-fork 对 Redis 压测时 TP100 的影响。

从图上可以看出,使用支持 Async-fork 的操作系统,fork() 操作对 Redis 压测产生的性能影响非常小,性能提升非常明显,不管数据量多大,耗时都非常稳定,基本在 1-2 毫秒左右;而原生 fork 产生的抖动影响时间会随着数据量增长而增长, TP100 从几十毫秒增长到几百毫秒。
8、总结
通过不同数据量下对比测试,我们可以看到,Async-fork 相比原生 fork,阻塞时间大大减少,性能提升非常明显。而且阻塞时间非常稳定,不会因为数据量的增长出现倍数级增长。
在单机测试场景下,8G 数据量大小下,TP100 和latest_fork_usec 耗时均减少 98% 以上。
基于论文中 Async-fork 的设计思想,Tair 专属操作系统镜像已支持该特性,并且将该特性集成在原生 fork 中,没有新增系统调用接口,理论上用户只需要使用支持 Async-fork 的操作系统,程序无需做任何修改,就可以享受到 Async-fork 特性带来的性能提升。对于 Redis 而言,我们也只需要对 Redis 稍加适配就可以获得该技术带来的红利。
在 Redis 应用场景中,在添加从节点、RDB 文件备份、AOF 持久化文件重写等场景下,应用支持 Async-fork 的操作系统,都将极大的减少对业务的影响。