超高分辨率作为记录和显示高质量图像、视频的一种标准受到众多研究者的欢迎,与较低分辨率(1K 高清格式)相比,高分辨率捕获的场景通常细节十分清晰,像素的信息被一个个小 patch 放大。但是,想要将这种技术应用于图像处理和计算机视觉还面临很多挑战。
本文中,来自阿里巴巴的研究者专注于新的视图合成任务,提出了一个名为 4K-NeRF 的框架,其基于 NeRF 的体积渲染方法可以实现在 4K 超高分辨率下高保真视图合成。

论文地址:https://arxiv.org/abs/2212.04701
项目主页:https://github.com/frozoul/4K-NeRF
话不多说,我们先来看看效果(以下视频均进行了降采样处理,原版 4K 视频请参考原项目)。
方法
接下来我们来看看该研究是如何实现的。
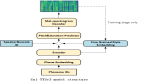
4K-NeRF pipeline(如下图):使用基于 patch 的射线采样技术,联合训练 VC-Encoder(View-Consistent)(基于 DEVO)在一个较低分辨率的空间中编码三维几何信息,之后经过一个 VC-Decoder 实现针对高频细高质量的渲染与视图一致性的增强。

该研究基于 DVGO [32] 中定义的公式实例化编码器,学习到的基于体素网格的表示来显式地编码几何结构:

对于每个采样点,密度估计的三线性插值配备了一个 softplus 激活函数用于生成该点的体密度值:

颜色则是用一个小型的 MLP 估计算:

这样可以通过累积沿着设线 r 的采样点的特征来得到每个射线(或像素)的特征值:

为了更好地利用嵌入在 VC-Encoder 中的几何属性,该研究还通过估计每条射线 r 沿采样射线轴的深度生成了一个深度图。估计的深度图为上面 Encoder 生成的场景三维结构提供了强有力的指导:

之后经过的网络是通过叠加几个卷积块(既不使用非参数归一化,也不使用降采样操作)和交错的升采样操作来建立的。特别是,该研究不是简单地将特征 F 和深度图 M 连接起来,而是加入了深度图中的深度信号,并通过学习变换将其注入每个块来调制块激活。

不同于传统的 NeRF 方法中的像素级机制,该研究的方法旨在捕获射线(像素)之间的空间信息。因此,这里不适合采用 NeRF 中随机射线采样的策略。因此该研究提出了一种基于 patch 的射线采样训练策略,以方便捕获射线特征之间的空间依赖性。训练中,首先将训练视图的图像分割成大小为 N_p×N_p 的 patch p,以确保像素上的采样概率是均匀的。当图像空间维数不能被 patch 大小精确分割时,需要截断 patch 直到边缘,得到一组训练 patch。然后从集合中随机抽取一个 (或多个) patch,通过 patch 中像素的射线形成每次迭代的 mini-batch。
为了解决对精细细节产生模糊或过度平滑视觉效果的问题,该研究添加了对抗性损失和感知损失来规范精细细节合成。感知损失 通过预先训练的 19 层 VGG 网络来估计特征空间中预测的 patch
通过预先训练的 19 层 VGG 网络来估计特征空间中预测的 patch 和真值 p 之间的相似性:
和真值 p 之间的相似性:

该研究使用 损失而不是 MSE 来监督高频细节的重建
损失而不是 MSE 来监督高频细节的重建

此外,该研究还添加了一个辅助 MSE 损失,最后总的 loss 函数形式如下:

实验效果
定性分析
实验对 4K-NeRF 与其他模型进行了比较,可以看到基于普通 NeRF 的方法有着不同程度的细节丢失、模糊现象。相比之下,4K-NeRF 在这些复杂和高频细节上呈现了高质量的逼真渲染,即使是在训练视野有限的场景上。


定量分析
该研究与目前几个方法在 4k 数据的基准下去做对比,包括 Plenoxels、DVGO、JaxNeRF、MipNeRF-360 和 NeRF-SR。实验不但以图像恢复的评价指标作为对比,还提供了推理时间和缓存内存,以供全面评估参考。结果如下:

虽然与一些方法的结果在一些指标上相差不大,但是得益于他们基于体素的方法在推理效率和内存成本上都取得了惊人的性能,允许在 300 ms 内渲染一个 4K 图像。

总结及未来展望
该研究探讨了 NeRF 在精细细节建模方面的能力,提出了一个新颖的框架来增强其在以极高分辨率的场景中恢复视图一致的细微细节的表现力。此外,该研究还引入了一对保持几何一致性的编解码器模块,在较低的空间中有效地建模几何性质,并利用几何感知特征之间的局部相关性实现全尺度空间中的视图一致性的增强,并且基于 patch 的抽样训练框架也允许该方法集成来自面向感知的正则化的监督。该研究希望将框架合并到动态场景建模中的效果,以及神经渲染任务作为未来的方向。